Pressupostos de medidas contra danos à reputação: Explicando como examinar artigos negativos na internet

Para eliminar páginas da web relacionadas a escândalos corporativos passados, incidentes de repercussão negativa, prisões e antecedentes criminais, a primeira coisa que precisa ser feita é listar todas essas páginas e publicações negativas sem deixar nada de fora. Se não for possível fazer essa lista, não será possível avançar com as medidas de gestão de danos à reputação, olhando para o volume total. Além disso, há o risco de ter que realizar procedimentos judiciais, como medidas provisórias e julgamentos, duas vezes devido a omissões, quando deveriam ter sido concluídos em uma única vez.
No entanto, listar todas as páginas da web e publicações que mencionam um determinado facto (por exemplo, escândalos corporativos, incidentes de repercussão negativa, prisões e antecedentes criminais) não é de todo “fácil”. Esta é uma tarefa que requer um alto grau de especialização e conhecimento.
O escritório de advocacia Monolith, com um advogado principal que era um engenheiro de TI e uma equipa especializada em pesquisa na internet, é um escritório de advocacia especializado em gestão de danos à reputação. A seguir, explicaremos como deve ser realizada a pesquisa na internet.
O que são os resultados de pesquisa do Google e os seus limites?
A base de qualquer pesquisa na internet é, sem dúvida, a pesquisa do Google. No entanto, nos resultados de pesquisa exibidos pelo Google, quando procuramos por palavras-chave que queremos encontrar, por exemplo, no caso de remoção de artigos de prisão, como “o meu nome + prisão”, existem limitações em três aspectos.
Páginas da web que são alvo da pesquisa Google
Na internet, existem “inúmeras” páginas da web. Embora seja teoricamente impossível medir o número total de páginas da web na internet, algumas fontes afirmam que o número de “sites” é atualmente cerca de 1,8 bilhões.
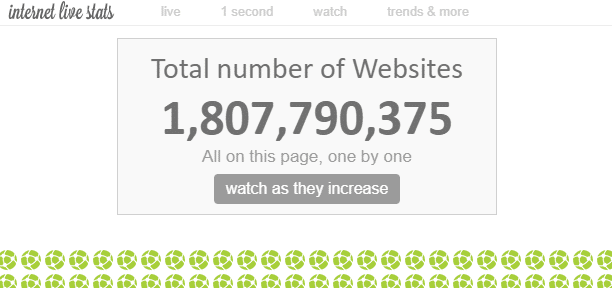
Como existem várias páginas da web dentro de um único site, o número de páginas da web é muito maior do que isso.
E a pesquisa Google, para simplificar, é realizada da seguinte maneira:
- O bot do Google (Googlebot) rastreia a internet, descobre novas páginas da web que podem ser abertas seguindo links de páginas da web conhecidas
- Compreende o conteúdo dessa página (registra no índice)
- Quando uma pesquisa é realizada com as palavras-chave contidas nessa página, a página é exibida nos resultados da pesquisa
O que quero dizer é que as páginas da web exibidas na pesquisa Google são apenas as “páginas da web que o Google indexou da maneira descrita acima”, não “todas as páginas da web”. Em outras palavras, enquanto você estiver usando a pesquisa Google, não poderá encontrar “páginas da web que o Google ainda não indexou”, e não existe uma maneira de pesquisar todas as páginas da web na internet sem exceção.
“Páginas semelhantes” são excluídas dos resultados da pesquisa
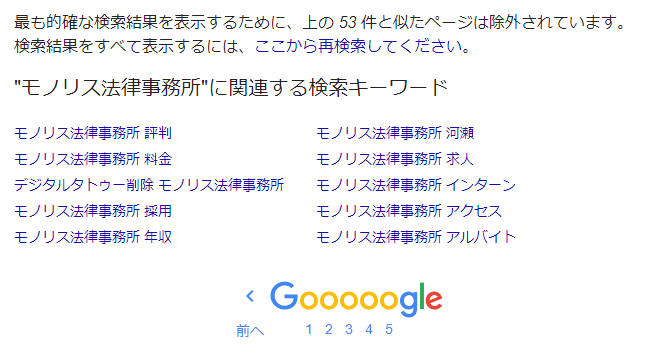
Além disso, o Google não exibe “todas as páginas da web que contêm a palavra-chave de pesquisa e estão indexadas” nos resultados da pesquisa. Isto é algo que pode notar se usar regularmente a pesquisa do Google. É o que é indicado na última página dos resultados da pesquisa: “Para mostrar os resultados mais relevantes, as páginas semelhantes aos ○ itens acima foram excluídas”.
Por exemplo,
- Uma notícia é distribuída pela primeira vez num grande site de notícias
- A notícia é republicada em serviços que agregam artigos de notícias
- A notícia é também republicada em sites pessoais, etc.
Nestes casos, se páginas com o mesmo conteúdo encherem os resultados da pesquisa, isso torna-se inconveniente para o utilizador. Por isso, o Google exclui automaticamente das pesquisas as “páginas semelhantes”, ou seja, no caso acima, os itens 2 e 3.
Isto não é necessariamente uma característica “conveniente” se quiser “eliminar todas as páginas de difamação”. Por exemplo, se a “notícia” mencionada acima for um artigo sobre a sua própria detenção no passado,
Apenas o “1. Artigo de distribuição original do grande site de notícias” estava a ser exibido nos resultados da pesquisa, por isso, quando essa página foi eliminada, com a remoção do item 1, o “2. Artigo republicado no serviço de agregação de notícias” começou a aparecer nos resultados da pesquisa do Google.
Esta é uma situação possível.
Este problema pode ser resolvido clicando na parte que diz “Para mostrar todos os resultados da pesquisa, pesquise novamente a partir daqui” na exibição acima, mas se não conhecer esta funcionalidade, pode haver a possibilidade de “perder” páginas de difamação.
Existe um limite para o número de artigos exibidos a partir do mesmo site

Além disso, o Google estabelece um limite para o número de páginas de resultados de pesquisa exibidas a partir de um único site. Esta especificação é um pouco complexa, mas para simplificar, “o máximo que é exibido a partir do mesmo site é de 2 páginas”.
Para explicar, por exemplo, mesmo que existam 5 perguntas e respostas em que o nome de uma empresa ou indivíduo aparece no Yahoo! Respostas, nos resultados da pesquisa do Google para o nome da empresa ou indivíduo em questão, no máximo 2 páginas do Yahoo! Respostas serão exibidas. O mesmo se aplica a fóruns, etc. Mesmo que existam 5 tópicos no 5chan que contêm uma determinada palavra-chave, no máximo 2 serão exibidos nos resultados da pesquisa do Google. Além disso, por exemplo, se uma pessoa tem,
- Um artigo sobre a sua prisão
- Um artigo sobre a sua re-prisão
- Um artigo sobre a sua condenação
Se existem 3 artigos no mesmo site de notícias, pelo menos um deles (3-2=1) não será exibido nos resultados da pesquisa do Google.
Quando se pesquisa uma determinada palavra-chave, se as páginas dentro do mesmo site (por exemplo, Yahoo! Respostas, um determinado fórum, um determinado site de notícias, etc.) aparecem em grande quantidade nos resultados da pesquisa, isso é inconveniente para o usuário, por isso o Google tem esta especificação.
No entanto, esta especificação não é necessariamente “fácil de usar” quando se quer “eliminar todas as páginas de difamação”.
Por exemplo, no caso acima, se quiser remover uma pergunta e resposta negativa do Yahoo! Respostas através de um processo judicial, e olhar para os resultados da pesquisa do Google e decidir que “só existem 2 alvos” e prosseguir com o processo, quando a remoção for bem sucedida, um dos restantes 3 (5-2=3) será exibido nos resultados da pesquisa.
Pesquisa avançada no Google usando “expressões de pesquisa”
Entre os problemas mencionados acima, a funcionalidade “expressões de pesquisa” do Google é particularmente necessária para resolver o terceiro problema.
O Google, de facto, estabelece um limite de “2 páginas básicas por site” para a funcionalidade de “pesquisar páginas que contêm a palavra-chave em questão em toda a Internet” (pesquisa global). No entanto, ao usar a “expressão de pesquisa” “palavra-chave site:URL do site alvo”, você pode:
- Realizar pesquisas apenas nos artigos do site alvo especificado
- Não há limite de “2 páginas básicas por site” nos resultados dessa pesquisa
Realizar este tipo de pesquisa.
As “expressões de pesquisa” são na verdade mais complexas, e existem expressões de pesquisa que são usadas para resolver problemas além dos mencionados acima.
Método de pesquisa especial para sites específicos
Por exemplo, o Yahoo! Respostas tem uma função de pesquisa própria.
Esta pesquisa não é baseada em “páginas da web que o Google (por acaso) indexou”, mas sim nos “resultados da pesquisa do programa de pesquisa do Yahoo! Respostas diretamente na base de dados do Yahoo! Respostas”. Isto resolve o problema mencionado anteriormente de que “existem páginas da web que o Google ainda não indexou”. Em outras palavras, “se for uma página dentro do Yahoo! Respostas, pode ser encontrada sem falhas usando apenas a função de pesquisa do Yahoo! Respostas”.
Portanto,
No caso de um facto (escândalo da empresa, prisão de um indivíduo, etc.) ser descoberto nas páginas do Yahoo! Respostas através de uma pesquisa global, é possível fazer uma lista completa usando a função de pesquisa do Yahoo! Respostas, em vez de usar a expressão de pesquisa “site:”.
É isso.
Isto também se aplica ao Twitter. Devido à natureza do serviço, o Twitter é um site onde é comum haver vários tweets sobre um facto que se tornou um tópico de discussão (escândalo da empresa, prisão de um indivíduo, etc.). Nem todos esses tweets estão necessariamente indexados no Google, e nem todos são necessariamente exibidos numa pesquisa global.
Método de contagem para “1 item” a ser excluído

A relação entre a listagem adequada e o “URL”
Até agora, escrevemos sobre “como encontrar o maior número possível de páginas da web (URLs) usando a pesquisa do Google”, mas isso não significa que é bom listar o máximo possível. Isso porque o alvo da solicitação de exclusão não necessariamente usa o “URL” como unidade.
No caso do 5chan (5ちゃんねる)
Isso é particularmente problemático no caso de sites de fóruns (como o 5chan e seus sites de cópia, e outros sites de fóruns).
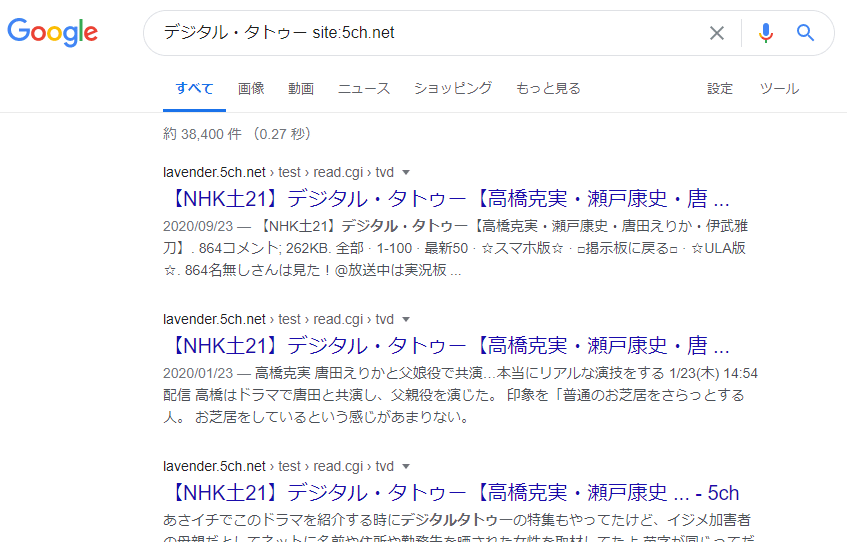
Por exemplo, se você pesquisar um determinado termo no Google com a expressão de pesquisa “site:5ch.net”, ou seja, pesquisar dentro do 5chan, URLs como os seguintes podem ser exibidos nos resultados da pesquisa:
- ○○○.5ch.net/test/read.cgi/○○/○○○○/40
- ○○○.5ch.net/test/read.cgi/○○/○○○○/1-100
- ○○○.5ch.net/test/read.cgi/○○/○○○○/30-
O 5chan tem as seguintes características:
- Se você adicionar o número de resposta após o URL do tópico, apenas essa resposta será exibida
- Se você adicionar um intervalo de números de resposta como “A-B” após o URL do tópico, apenas as respostas nesse intervalo serão exibidas
- Se você adicionar um número de resposta inicial e um “-” após o URL do tópico, todas as respostas a partir dessa resposta serão exibidas
Em outras palavras, mesmo que o termo de pesquisa esteja escrito apenas na resposta número 40, várias URLs (páginas da web) serão exibidas nos “resultados da pesquisa”.
No entanto, quando se faz uma solicitação de exclusão para um site de fórum, a unidade do alvo da solicitação é, pelo menos em princípio, a “resposta”. Portanto, se você quiser excluir a resposta número 40, basta extrair a seguinte URL:
- ○○○.5ch.net/test/read.cgi/○○/○○○○/40
E você não precisa listar os dois últimos.
No caso de sites de cópia do 5chan e sites de compilação
Além disso, para complicar ainda mais as coisas, mesmo no caso do 5chan (e similares), no caso de seus sites de cópia e “sites de compilação”, a unidade da solicitação de exclusão pode ser a “página (tópico)”, não a “resposta”, dependendo do site. Determinar “qual é o alvo da solicitação de exclusão de qual site” é totalmente uma questão de “know-how”.
https://monolith.law/reputation/delation-of-scraping-site-roundup-website[ja]
Portanto,
- Compreensão da unidade da solicitação de exclusão legal
- Compreensão das especificações do URL de um site (por exemplo, o 5chan tem regras complexas como as acima)
Sem isso, será difícil “listar os alvos de exclusão enquanto olha para os resultados da pesquisa”.
Pesquisa fora da Web Aberta

Até agora, temos falado sobre sites que o Google pode potencialmente indexar, mas também existem sites que:
- O Google definitivamente não irá indexar
- No entanto, devem ser considerados para pedidos de remoção como parte da gestão de danos à reputação
Estes sites também existem.
O Google, devido às suas especificações, só considera como alvo de pesquisa os sites que qualquer pessoa pode ver sem fazer login (Web Aberta). No entanto, existem serviços pagos na internet que permitem a pesquisa e visualização em massa de artigos antigos de jornais, por exemplo, e que não podem ser vistos sem registo ou login.
Por exemplo, no caso da remoção de artigos sobre detenções, é necessário examinar cuidadosamente também os sites de bases de dados de jornais. Isto porque muitas empresas que investigam a credibilidade de empresas e indivíduos utilizam estes sites de bases de dados de jornais.
Para mais detalhes sobre os sites de bases de dados de jornais, consulte o artigo abaixo.
https://monolith.law/reputation/criminal-record-newspaper-database[ja]
Resumo
Como mencionado acima, “compilar uma lista de alvos para solicitar a remoção como medida de gestão de danos à reputação na Internet” é uma tarefa altamente especializada. O nosso escritório realiza a compilação de tais listas de artigos-alvo quando lidamos com a gestão de danos à reputação, mas este trabalho pressupõe uma especialização em IT e Internet.
A remoção de páginas (ou respostas em fóruns) como medida de gestão de danos à reputação na Internet é uma tarefa que só pode ser realizada por advogados.
https://monolith.law/reputation/hiben-koui[ja]
Por outro lado, a compilação desta lista é uma tarefa que exige um conhecimento muito avançado de IT e Internet, como explicado neste artigo. Isto é uma das grandes razões pelas quais se deve recorrer a um escritório de advocacia com uma alta especialização em IT e Internet para a gestão de danos à reputação. Se a compilação da lista for negligente, pode-se enfrentar problemas como:
- Mesmo que todas as páginas listadas sejam removidas, outras páginas que não estavam visíveis nos resultados de pesquisa globais no momento da compilação podem aparecer nos resultados de pesquisa, tornando necessária a remoção adicional e fazendo com que o orçamento inicial seja significativamente errado.
- Em relação aos procedimentos judiciais, o que deveria ter sido resolvido numa única vez pode requerer duas ou três vezes, resultando em custos excessivos.
- Não se aperceber da existência de páginas fora da web aberta, como sites de bases de dados de jornais, e não resolver “problemas” como “dificuldades em encontrar emprego devido a artigos de prisão serem pesquisados”.
Estes são os problemas que podem surgir.
Category: Internet
Related Articles

Os documentos publicados por agências governamentais têm direitos autorais? Explicação sobre pon.
Internet

Os mapas residenciais são obras protegidas por direitos autorais? Explicação do processo judicia.
Internet

Em que medida a fotografia e a publicação sem permissão são permitidas por lei? Explicação de 4 .
Internet

O que é o 'Direito de Publicidade'? Explicação das diferenças com o 'Direito de Imagem' e situaç.
Internet















