Передумови заходів проти шкоди від негативних відгуків: пояснення методів детального аналізу негативних статей в Інтернеті

У випадку, коли потрібно видалити веб-сторінки, що стосуються минулих корпоративних скандалів, випадків підпалу, арештів або судимості, спочатку необхідно виконати таку роботу, як “створення списку всіх негативних сторінок та публікацій без пропусків”. Якщо ви не можете створити цей список, ви не зможете продовжувати заходи щодо управління репутаційними ризиками, дивлячись на загальний обсяг, і, наприклад, щодо судових процедур, таких як тимчасові заходи або судові рішення, ви можете зіткнутися з ризиком, що вам доведеться провести їх двічі через пропущені пункти, хоча вони мали б бути завершені за один раз.
Однак, створення списку всіх веб-сторінок та публікацій, що описують певний факт (наприклад, корпоративний скандал, випадок підпалу, арешт або судимість) в Інтернеті, зовсім не “проста” робота. Ця частина вимагає високої спеціалізації і не може бути виконана без відповідних знань та навичок.
Юридична фірма “Monolith” є юридичною фірмою, що спеціалізується на управлінні репутаційними ризиками, і має в своєму складі колишніх IT-інженерів та адвокатів, а також персонал, спеціалізований на дослідженні Інтернету, як зазначено вище. Нижче ми пояснимо, як має проводитися дослідження в Інтернеті.
Що таке результати пошуку Google та їх обмеження?
Основою інтернет-досліджень, безумовно, є пошук Google. Однак, результати пошуку в Google за ключовими словами, які ви хочете знайти, наприклад, у випадку видалення статей про арешт, як “моє прізвище арешт”, мають обмеження у трьох аспектах.
Веб-сторінки, які піддаються пошуку Google
В Інтернеті існує “незліченна” кількість веб-сторінок. Теоретично неможливо виміряти загальну кількість веб-сторінок в Інтернеті, але за деякими даними, кількість “веб-сайтів” на сьогоднішній день становить приблизно 1,8 мільярда.
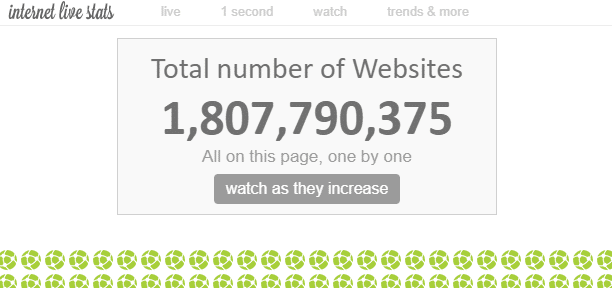
Оскільки в одному веб-сайті може бути кілька веб-сторінок, кількість веб-сторінок є значно більшою.
І пошук Google, просто кажучи, відбувається так:
- Бот Google (Googlebot) сканує Інтернет, виявляючи нові веб-сторінки, до яких можна дістатися, слідуючи за посиланнями з відомих веб-сторінок
- Розуміє вміст цієї сторінки (реєстрація в індексі)
- Коли пошук виконується за ключовими словами, що містяться на цій сторінці, ця сторінка відображається у результатах пошуку
Що я хочу сказати, це те, що відображаються в пошуку Google, це лише “веб-сторінки, які Google зареєстрував в індексі, як описано вище”, а не “всі веб-сторінки”. Тобто, використовуючи пошук Google, ви не зможете знайти “веб-сторінки, які Google ще не зареєстрував в індексі”, і взагалі, не існує способу, який би дозволив вам знайти всі веб-сторінки в Інтернеті без винятку.
“Схожі” веб-сторінки виключаються з результатів пошуку
Google не відображає “всі веб-сторінки, що містять ключові слова пошуку” серед індексованих веб-сторінок. Ви, можливо, помітили це, коли користувалися пошуком Google. На останній сторінці результатів пошуку відображається повідомлення “Для відображення найбільш точних результатів пошуку, сторінки, схожі на вищезазначені, виключено”.
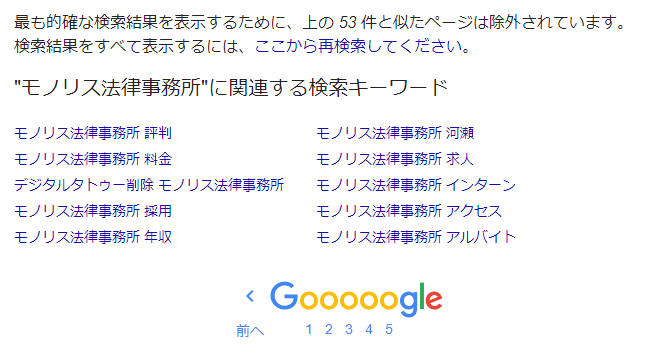
Наприклад,
- Якщо певна новина була спочатку опублікована на великому новинному сайті
- Потім була перепублікована на сервісах, що збирають новини
- І потім була перепублікована на особистих сайтах
У такому випадку, якщо сторінки з однаковим вмістом заповнюють результати пошуку, це ускладнює використання для користувачів. Тому Google автоматично виключає “схожі” сторінки з результатів пошуку, у даному випадку – пункти 2 та 3.
Це не завжди “зручно” для тих, хто хоче “позбутися” сторінок з негативними відгуками. Наприклад, якщо вищезазначена “новина” – це стаття про ваше минуле арештування,
В результати пошуку відображалася тільки “1. Оригінальна стаття великого новинного сайту”, і коли ви видалили тільки цю сторінку, після видалення 1, “2. Стаття, перепублікована на сервісі збору новин” почала відображатися в результатах пошуку Google.
Це можливий сценарій.
Цю проблему можна вирішити, натиснувши на “Щоб показати всі результати пошуку, почніть новий пошук тут” в зазначеному вище повідомленні, але якщо ви не знаєте про цю функцію, ви можете “пропустити” сторінки з негативними відгуками.
Є максимальна кількість статей, що відображаються з одного сайту

Більше того, Google встановлює максимальну кількість сторінок з результатами пошуку, що відображаються з одного веб-сайту. Ця специфікація трохи складна, але просто кажучи, “максимальна кількість сторінок, що відображаються з одного сайту, становить 2 сторінки”.
Що це означає? Наприклад, навіть якщо на Yahoo! Chiebukuro (Японський аналог Yahoo! Answers) є 5 Q&A, де згадується ім’я певної компанії або особи, в результатах пошуку Google для цієї компанії або особи буде відображено максимум 2 сторінки з Yahoo! Chiebukuro. Те ж саме стосується форумів, навіть якщо є 5 тем на 5ch (Японський аналог Reddit), що містять певне ключове слово, в результатах пошуку Google буде відображено максимум 2 теми. Наприклад, якщо є особа, про яку написано:
- Стаття про арешт
- Стаття про повторний арешт
- Стаття про винесення винуватого вироку
І всі 3 статті знаходяться на одному новинному сайті, то в результатах пошуку Google принаймні одна з них (3-2=1) не буде відображена.
Якщо при пошуку певного ключового слова велика кількість сторінок з одного сайту (наприклад, Yahoo! Chiebukuro, певний форум, певний новинний сайт тощо) відображається в результатах пошуку, це може бути незручно для користувача, тому Google має таку специфікацію.
Однак, ця специфікація не завжди “зручна” для тих, хто хоче “позбутися сторінок з негативними відгуками”.
Наприклад, якщо ви хочете видалити негативні Q&A з Yahoo! Chiebukuro через судовий процес, і дивлячись на результати пошуку Google, ви вирішите, що “є тільки 2 цільові сторінки” і продовжите процес, то після успішного видалення одна з решти 3 сторінок (5-2=3) може з’явитися в результатах пошуку.
Використання “пошукових виразів” для розширеного пошуку в Google
Згадані вище проблеми, особливо третя, вимагають використання функції “пошукові вирази” в Google.
Google, безумовно, має функцію “пошук сторінок, що містять відповідні ключові слова на всьому Інтернеті” (глобальний пошук), для якого встановлено обмеження “основні 2 сторінки на сайт”. Однак, використовуючи “пошуковий вираз” у форматі “ключове слово site:URL цільового сайту”, ви можете:
- Проводити пошук тільки в статтях вказаного цільового сайту
- Для цих результатів пошуку обмеження “основні 2 сторінки на сайт” не застосовується
Таким чином, ви можете проводити пошук.
“Пошукові вирази” насправді є більш складними, існують інші пошукові вирази, які використовуються для вирішення проблем, що не згадані вище.
Спеціальний пошуковий інструмент для конкретного сайту
Наприклад, на Yahoo!知恵袋 (Яху! Чієбукуро) існує власна пошукова функція.
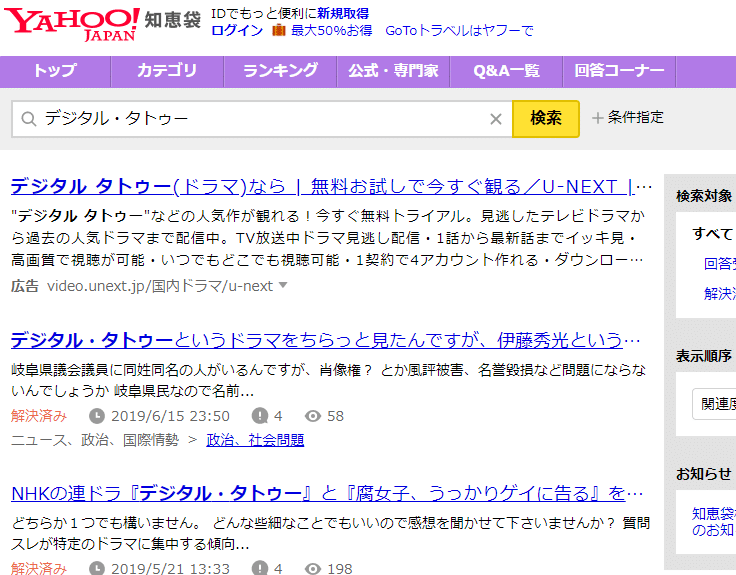
Цей пошук не є “веб-сторінкою, яку Google (випадково) індексував”, але “результатом пошуку в базі даних Яху! Чієбукуро, який був безпосередньо здійснений пошуковою програмою Яху! Чієбукуро”. Це розв’язує проблему, про яку ми говорили спочатку, що “існують веб-сторінки, які Google ще не індексував”. Це означає, що “якщо це сторінка в Яху! Чієбукуро, ви можете знайти все, що вам потрібно, використовуючи лише пошукову функцію Яху! Чієбукуро”.
Отже,
Якщо сторінка Yahoo!知恵袋 (Яху! Чієбукуро) була знайдена в глобальному пошуку по факту (наприклад, недоліки компанії, арешт особи тощо), то використання пошукової функції Yahoo!知恵袋 (Яху! Чієбукуро) дозволить вам зробити більш повний список, ніж використання формули пошуку “site:”.
Це стосується також Twitter. Через характер служби Twitter, твіти про певні події (наприклад, недоліки компанії, арешт особи тощо) часто з’являються в багаточисленних випадках. Всі ці твіти не обов’язково індексуються Google, і вони не обов’язково всі відображаються в глобальному пошуку.
Метод підрахунку “1 запису” для видалення

Відношення між правильним списком та “URL”
До цього моменту ми говорили про “методи збору якомога більшої кількості веб-сторінок (URL) за допомогою Google Search та інших засобів”, але це не означає, що краще зібрати якомога більше. Це тому, що об’єкт запиту на видалення не обов’язково вимірюється в “URL”.
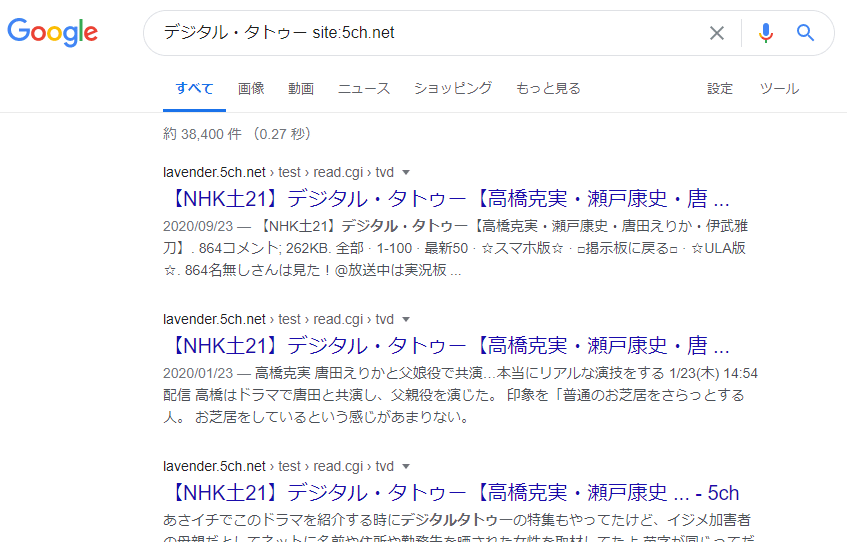
У випадку з 5ch.net
Це стає проблемою, особливо на сайтах-форумах, таких як 5ch.net, його копії та інші подібні сайти.
Наприклад, якщо ви шукаєте певне ключове слово в Google за допомогою формули пошуку “site:5ch.net”, тобто шукаєте в межах 5ch.net, можуть відображатися такі URL-адреси в результатах пошуку:
- ○○○.5ch.net/test/read.cgi/○○/○○○○/40
- ○○○.5ch.net/test/read.cgi/○○/○○○○/1-100
- ○○○.5ch.net/test/read.cgi/○○/○○○○/30-
5ch.net має такі характеристики:
- Якщо ви вкажете номер відповіді після URL-адреси потоку, відобразиться лише ця відповідь
- Якщо ви вкажете діапазон номерів відповідей, такий як “A-B”, після URL-адреси потоку, відобразиться лише цей діапазон відповідей
- Якщо ви вкажете початковий номер відповіді та “-” після URL-адреси потоку, відобразяться всі відповіді після цього номера
Тобто, якщо ключове слово записане лише в відповіді номер 40, різні URL-адреси (веб-сторінки) відображатимуться в “результатах пошуку”.
Однак, коли ви подаєте запит на видалення до сайту-форуму, одиницею запиту, як правило, є “відповідь”. Тому, якщо ви хочете видалити відповідь номер 40, достатньо витягнути лише
- ○○○.5ch.net/test/read.cgi/○○/○○○○/40
URL, і вам не потрібно включати два інших в список.
У випадку з копіями сайту 5ch.net та агрегаторами
Щоб додати, хоча це трохи заплутано, навіть на тому ж 5ch.net (або подібних сайтах), в залежності від сайту, одиницею запиту на видалення може бути не “відповідь”, а “сторінка (потік)”. “Що є об’єктом запиту на видалення для якого сайту” – це повністю в області “знань”.
https://monolith.law/reputation/delation-of-scraping-site-roundup-website[ja]
Тому,
- розуміння юридичної одиниці запиту на видалення
- розуміння специфікації URL веб-сайту (наприклад, 5ch.net має складні правила, як описано вище)
необхідні для “створення списку об’єктів для видалення, переглядаючи результати пошуку”.
Пошук поза відкритим вебом

До цього моменту ми говорили про сайти, які Google може індексувати, але також існують сайти:
- які Google точно не індексує;
- але які слід враховувати як потенційні об’єкти для видалення при управлінні репутаційними ризиками.
Google, згідно зі своїми специфікаціями, не включає до об’єктів пошуку сайти, які не є відкритим вебом, тобто сайти, які можна переглядати без входу в систему. Однак, наприклад, в світі існують такі речі, як “платні веб-сервіси, які дозволяють шукати та переглядати архівні статті з газет (і тому, щоб їх переглянути, потрібно зареєструватися або увійти в систему)”.
Наприклад, у випадку видалення статей про арешт, потрібно ретельно перевірити також сайти з базами даних газет. Це тому, що багато компаній, які займаються дослідженням кредитоспроможності компаній та осіб, використовують ці сайти з базами даних газет.
Детальніше про сайти з базами даних газет ви можете прочитати в статті за посиланням нижче.
https://monolith.law/reputation/criminal-record-newspaper-database[ja]
Підсумок
Як бачимо, “складання списку об’єктів для видалення в мережі Інтернет як заходу протидії шкоді від негативних відгуків” – це дуже спеціалізована робота. Наша юридична фірма виконує таке складання списку об’єктів при наданні послуг з протидії шкоді від негативних відгуків, але ця робота передбачає наявність спеціалізованих знань у сфері ІТ та Інтернету.
Видалення сторінок (або повідомлень на форумах) в рамках протидії шкоді від негативних відгуків в мережі Інтернет – це завдання, яке може виконувати тільки адвокат.
https://monolith.law/reputation/hiben-koui[ja]
Однак, з іншого боку, це складання списку, як було пояснено в цій статті, вимагає високого рівня знань у сфері ІТ та Інтернету. Це одна з важливих причин, чому варто звертатися до юридичної фірми з високою спеціалізацією в області ІТ та Інтернету для протидії шкоді від негативних відгуків. Якщо цей список буде складено недбало, можуть виникнути такі проблеми:
- Навіть якщо видалити всі сторінки зі списку, інші сторінки, які не були відображені в глобальних результатах пошуку під час складання списку, можуть з’явитися в результатах пошуку, і потрібно буде видаляти їх додатково, що призведе до значного перевищення початкового бюджету.
- Щодо судових процедур, які мали б зайняти тільки один раз, може виявитися, що їх потрібно проводити два або три рази, що призведе до великих витрат.
- Не виявляючи наявність сторінок поза відкритим вебом, таких як сайти баз даних газет, можна не вирішити “проблему”, наприклад, “проблему з працевлаштуванням через пошук статей про арешт”.
Це можуть бути причини виникнення таких проблем.
Category: Internet




















