Reputatsioonikahju ennetamise eeldus: Internetis leiduvate negatiivsete artiklite põhjaliku uurimise meetodite selgitus

Kui soovite veebilehtedelt kustutada teavet mineviku ettevõtte skandaalide, põlengute, arreteerimiste ja kriminaalsete taustade kohta, on esmaseks eelduseks see, et peate looma nimekirja kõigist negatiivsetest lehekülgedest ja postitustest, et midagi ei jääks kahe silma vahele. Kui te ei suuda seda nimekirja koostada, ei saa te hinnata kogu mahtu ja tegeleda mainekahju haldamisega. Näiteks võib juhtuda, et kohtumenetlused, nagu ajutised meetmed või kohtuasjad, mida oleks pidanud saama korraldada ühe korraga, tuleb läbi viia kaks korda, sest midagi jäi märkamata.
Kuid kõigi veebilehtede ja postituste loetlemine, mis sisaldavad teavet teatud faktide kohta (näiteks ettevõtte skandaalid, põlengud, arreteerimised ja kriminaalne taust), pole sugugi “lihtne”. See on väga spetsialiseeritud ülesanne, mida ei saa teha ilma asjakohaste teadmisteta.
Monolith advokaadibüroo on mainekahju haldamisele spetsialiseerunud advokaadibüroo, mille meeskonda kuuluvad endised IT-inseneridest peajuristid ja internetiuuringutele spetsialiseerunud töötajad. Järgnevalt selgitame, kuidas peaks toimuma internetiuuring.
Mis on Google’i otsingutulemused ja nende piirangud?
Interneti-uuringute aluseks on ikkagi Google’i otsing. Kuid Google’is on enda poolt otsitavate märksõnade, näiteks vahistamisartikli kustutamise korral “oma nimi vahistamine” ja muude selliste märksõnade otsingutulemustel kolm piirangut.
Google’i otsingu sihtmärgiks olevad veebilehed
Internetis on olemas “lugematul hulgal” veebilehti. Internetis olevate veebilehtede koguarvu on teoreetiliselt võimatu mõõta, kuid ühe teooria kohaselt on praeguse seisuga “veebisaitide” arv umbes 1,8 miljardit.
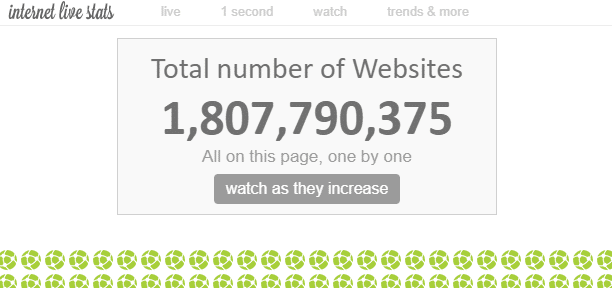
Ühel veebisaidil on mitu veebilehte, seega on veebilehtede arv palju suurem.
Ja Google’i otsing töötab lihtsalt öeldes järgmiselt:
- Google’i bot (Googlebot) skaneerib interneti, avastab uued veebilehed, järgides linke teadaolevatelt veebilehtedelt
- Mõistab selle lehe sisu (indekseerimine)
- Kui otsing tehakse lehel sisalduvate märksõnade järgi, kuvatakse see leht otsingutulemustes
Mida ma tahan öelda, on see, et Google’i otsingus kuvatakse ainult “veebilehed, mille Google on indekseerinud ülaltoodud viisil”, mitte “kõik veebilehed”. Seega, kui kasutate Google’i otsingut, ei saa te leida “veebilehti, mida Google pole veel indekseerinud”, ja üldse pole olemas meetodit, mis võimaldaks leida kõik internetis olevad veebilehed ilma ühegi vahelejäämiseta.
“Sarnased” veebilehed on otsingutulemustest välja jäetud
Google ei kuvata otsingutulemustes kõiki “indekseeritud veebilehti, mis sisaldavad otsingusõna”. See võib olla märgatav, kui kasutate Google’i otsingut. See on näidatud otsingutulemuste viimasel lehel kui “Sarnaste lehtede väljajätmiseks, et kuvada kõige täpsemaid otsingutulemusi, on ülaltoodud ○ lehte välja jäetud”.
Näiteks,
- teatud uudis levitatakse esmalt suure uudiste saidi kaudu
- uudisartikkel kopeeritakse uudiste koondamise teenustesse
- see kopeeritakse ka isiklikele saitidele jne
Kui samasisulised lehed täidavad otsingutulemused, on see kasutajatele ebamugav, seega Google jätab “sarnased” lehed, nagu eespool mainitud juhtudel 2 ja 3, otsingutulemustest automaatselt välja.
See ei pruugi olla “kasutajasõbralik” funktsioon, kui soovite “kõrvaldada mainekahjustuse lehed”. Näiteks, kui eespool mainitud “teatud uudis” on teie varasem vahistamisartikkel, siis
Otsingutulemustes kuvati ainult “1. suure uudiste saidi esmane levitamisartikkel”, nii et kui selle lehe kustutasite, siis 1. lehe kadumise tõttu hakkab “2. uudiste koondamise teenuse kopeeritud artikkel” ilmuma Google’i otsingutulemustes
See on võimalik stsenaarium.
Selle probleemi lahendamiseks peate klõpsama kuvatud “Kõigi otsingutulemuste kuvamiseks otsige uuesti siit”, kuid kui te ei tea seda funktsiooni, võite “mainekahjustuse lehed” maha vaadata.
Ühel saidil kuvatavate artiklite arvul on ülempiir

Lisaks seab Google ühe veebisaidi otsingutulemuste lehtede arvule ülempiiri. See spetsifikatsioon on veidi keeruline, kuid lihtsustatult öeldes on “ühest saidilt kuvatavate lehtede maksimaalne arv 2”.
See tähendab, et näiteks kui Yahoo! Tarkusekotis on ettevõtte või isiku nime mainivaid Q&A-sid viis, siis Google’i otsingutulemustes kuvatakse Yahoo! Tarkusekoti lehti maksimaalselt kaks. Sama kehtib ka foorumite puhul – isegi kui on viis 5chani lõime, mis sisaldavad teatud märksõna, kuvatakse Google’i otsingutulemustes maksimaalselt kaks. Samuti, näiteks kui isikul on,
- artikkel, mis käsitleb tema vahistamist
- artikkel, mis käsitleb tema taasvahistamist
- artikkel, mis käsitleb tema süüdimõistvat otsust
ja need kolm artiklit on samal uudistesaidil, siis Google’i otsingutulemustes ei kuvata vähemalt ühte neist (3-2=1).
Kui teatud märksõna otsides kuvatakse otsingutulemustes suur hulk lehti samalt saidilt (näiteks Yahoo! Tarkusekott, teatud foorum, teatud uudistesait jne), on see kasutajatele ebamugav, seega on Google sellise spetsifikatsiooni kehtestanud.
Kuid see spetsifikatsioon ei pruugi olla “kasutajasõbralik”, kui soovite “puhastada mainekahjustuse lehti”.
Näiteks kui soovite eemaldada Yahoo! Tarkusekoti negatiivseid Q&A-sid kohtumenetluse kaudu ja vaatate Google’i otsingutulemusi ning otsustate, et “sihtmärke on ainult kaks”, ja jätkate menetlust, siis pärast eemaldamist kuvatakse otsingutulemustes üks kolmest järelejäänud lehest (5-2=3).
Täpne Google’i otsing “otsinguvalemite” abil
Eeltoodud probleemidest eriti kolmanda lahendamiseks on vajalik Google’i funktsioon nimega “otsinguvalem”.
Google seab tõepoolest “globaalse otsingu” funktsiooni, mis “otsib kogu internetist lehekülgi, mis sisaldavad vastavaid märksõnu”, piiranguks “põhimõtteliselt 2 lehekülge ühe saidi kohta”. Kuid kui kasutate “otsinguvalemit” nagu “märksõna site:sihtkoha URL”, siis saate:
- Otsida ainult määratud sihtkoha lehekülgedelt
- Selle otsingutulemustel ei ole “põhimõtteliselt 2 lehekülge ühe saidi kohta” piirangut
See võimaldab teil teha selliseid otsinguid.
“Otsinguvalem” on tegelikult palju keerulisem ja on olemas ka teisi otsinguvalemeid, mida kasutatakse eespool nimetatud probleemide lahendamiseks.
Erilised otsinguvahendid teatud saitidele
Näiteks on Yahoo! Tarkusekotil olemas oma otsingufunktsioon.
Selle otsingu tulemused ei põhine “juhuslikult Google’i poolt indekseeritud veebilehtedel”, vaid “Yahoo! Tarkusekoti andmebaasis, mida otsib otse Yahoo! Tarkusekoti otsinguprogramm”. See lahendab probleemi, millest me alguses rääkisime, et “on olemas veebilehti, mida Google pole veel indekseerinud”. See tähendab, et “kui leht on Yahoo! Tarkusekotis, siis saab selle leida kasutades Yahoo! Tarkusekoti otsingufunktsiooni, ilma et midagi jääks märkamata”.
Seega,
Kui teatud fakti (ettevõtte skandaal, isiku vahistamine jne) kohta on vähemalt üks leht leitud Yahoo! Tarkusekotis globaalse otsingu kaudu, siis on Yahoo! Tarkusekoti otsingufunktsiooni kasutamine tõhusam kui “site:” otsinguvalem, kuna see võimaldab leida kõik asjakohased lehed ilma, et midagi jääks märkamata.
See on oluline.
Sama kehtib ka Twitteri kohta. Twitteri olemuse tõttu on sageli mitu säutsu teatud sündmuse (ettevõtte skandaal, isiku vahistamine jne) kohta. Kõik need säutsud ei pruugi olla Google’is indekseeritud ja kõik need ei pruugi ilmuda globaalse otsingu tulemustes.
Kustutamise objekti “1 ühiku” loendamise meetod

Sobiva loetelu ja “URL-i” seos
Seni oleme kirjutanud “meetoditest, kuidas Google’i otsingut jms kasutades võimalikult palju veebilehti (URL-e) koguda”, kuid see ei tähenda, et mida rohkem loetletakse, seda parem. Kustutamise taotluse objekt ei pruugi tingimata olla “URL” ühikuna.
5chani puhul
See on probleem, mis tekib eriti foorumitüüpi saitide (nagu 5chan ja selle kloonisaidid või muud foorumitüüpi saidid) puhul.
Näiteks, kui otsite Google’is teatud märksõna, kasutades otsinguvormi “site:5ch.net”, st otsides 5chani seest, võib juhtuda, et otsingutulemustena kuvatakse järgmised URL-id:
- ○○○.5ch.net/test/read.cgi/○○/○○○○/40
- ○○○.5ch.net/test/read.cgi/○○/○○○○/1-100
- ○○○.5ch.net/test/read.cgi/○○/○○○○/30-
5chanil on järgmised omadused:
- Kui märgite lõime URL-i järel vastuse numbri, kuvatakse ainult vastav vastus
- Kui märgite lõime URL-i järel “A-B” vastusnumbri vahemiku, kuvatakse ainult vastav vahemik
- Kui märgite lõime URL-i järel “A-” vastusnumbri alguspunkti ja “-“, kuvatakse kõik vastused alates vastavast vastusest
See tähendab, et kui märksõna on kirjutatud ainult vastuse numbriga 40, kuvatakse “otsingutulemustes” mitmesugused URL-id (veebilehed).
Kuid kui soovite foorumitüüpi saidilt kustutamistaotlust esitada, on taotluse objekti ühik vähemalt põhimõtteliselt “vastus”. Seega, kui soovite kustutada vastuse numbriga 40, piisab, kui ekstraheerite ainult
- ○○○.5ch.net/test/read.cgi/○○/○○○○/40
URL-i ja teisi ei pea loetlema.
5chani kloonisaitide ja kokkuvõttesaitide puhul
Lisaks, kuigi see on veelgi keerulisem lugu, on sama 5chani (ja selle kloonide) puhul kloonisaitide ja “kokkuvõttesaitide” puhul kustutamistaotluse ühik sõltuvalt saidist “vastus” mitte “leht (lõim)”. “Milline sait on kustutamistaotluse objekt” on täielikult “teadmiste” valdkond.
https://monolith.law/reputation/delation-of-scraping-site-roundup-website[ja]
Seetõttu on
- õigusliku kustutamistaotluse ühiku mõistmine
- teatud veebisaidi URL-i spetsifikatsioonide mõistmine (näiteks 5chanil on ülaltoodud keerulised reeglid)
ilma nendeta on “kustutamise objekti loetlemine otsingutulemuste vaatamise ajal” keeruline.
Otsingud väljaspool avatud veebi

Seni oleme rääkinud saitidest, mida Google võib indekseerida, kuid on ka saite, mis:
- ei ole Google’i poolt kindlasti indekseeritud
- kuid peaksid olema kaalutud eemaldamise taotluse sihtmärgina mainekahju haldamise kontekstis
Need saidid on olemas.
Google ei võta otsingusse arvesse saite, mida saab vaadata ilma sisselogimata (avatud veeb). Kuid näiteks on olemas sellised teenused nagu “tasuline veebiteenus, mis võimaldab otsida ja vaadata ajaleheartiklite arhiivi” (seega peab kasutaja registreeruma või sisse logima, et seda näha).
Näiteks vahistamisartiklite eemaldamise korral tuleb hoolikalt uurida ka eespool nimetatud ajalehe andmebaasi saite. Ettevõtted ja isikud, kes uurivad krediidivõimekust, kasutavad sageli neid ajalehe andmebaasi saite.
Ajalehe andmebaasi saitide kohta leiate üksikasjalikuma selgituse allolevast artiklist.
https://monolith.law/reputation/criminal-record-newspaper-database[ja]
Kokkuvõte
Nagu eespool näidatud, on “Internetist eemaldamise taotluste loetelu koostamine mainekahju tõrjumiseks” väga spetsialiseeritud ülesanne. Meie büroo teeb mainekahju tõrjumisel sellist loetelu, kuid see töö eeldab IT- ja Interneti-alast spetsialiseerumist.
Internetis mainekahju tõrjumisel on lehekülgede (või foorumi postituste) eemaldamine ülesanne, mida saab teha ainult advokaat.
https://monolith.law/reputation/hiben-koui[ja]
Kuid teisest küljest on see loetelu, nagu selles artiklis üldjoontes selgitatud, väga kõrgetasemeline ülesanne, mis nõuab peamiselt IT- ja Interneti-alaseid teadmisi. See on üks suur põhjus, miks peaksite mainekahju tõrjumiseks pöörduma advokaadibüroo poole, millel on kõrgetasemeline spetsialiseerumine IT- ja Interneti-valdkonnas. Kui selline loetelu on puudulik, võib tekkida järgmised probleemid:
- Kui kõik loetletud leheküljed on eemaldatud, võivad otsingutulemustes ilmneda muud leheküljed, mis ei olnud loetelu koostamise ajal globaalsetes otsingutulemustes, ja on vaja täiendavat eemaldamist, mis tähendab, et algne eelarvearvestus oli oluliselt vale.
- Kohtumenetluse puhul, mis oleks pidanud olema ühekordne, võib olla vaja kahte või kolme korda, mis toob kaasa suured kulud.
- Ajalehtede andmebaasi saitide ja muude avatud veebi lehekülgede olemasolu võib jääda märkamata, mis tähendab, et näiteks “arreteerimisartikli otsimine takistab tööle saamist” ei lahenda “probleemi”.
Seetõttu võivad tekkida sellised probleemid.
Category: Internet




















