अवज्ञा की हानि के उपाय की आधारभूत बातें: इंटरनेट पर नकारात्मक लेखों की समीक्षा करने के तरीके की व्याख्या

अगर आप भूतकालीन कंपनी की अनुचित घटनाओं, आगजनी की घटनाओं, गिरफ्तारियों या पूर्व अपराधों आदि के बारे में वेबपेज को साफ करना चाहते हैं, तो सबसे पहले आपको यह सुनिश्चित करने की आवश्यकता होती है कि “उन सभी नकरात्मक पृष्ठों और पोस्टों को बिना किसी छूट के सूचीबद्ध किया जाए।” यदि यह सूचीबद्ध करना संभव नहीं है, तो आप पूरे आयाम को देखते हुए प्रतिष्ठा के क्षति के प्रबंधन को आगे बढ़ाने में सक्षम नहीं होंगे, और उदाहरण के लिए, अदालती कार्यवाही जैसे कि अस्थायी उपाय या मुकदमे के बारे में, जो मूल रूप से एक बार में समाप्त होने चाहिए था, लेकिन छूट के कारण दो बार करने की आवश्यकता पैदा होती है, ऐसा खतरा भी होता है।
हालांकि, इंटरनेट से, किसी विषय (जैसे कंपनी की अनुचित घटनाएं, आगजनी की घटनाएं, गिरफ्तारियां या पूर्व अपराध) के बारे में लिखित सभी वेबपेज और पोस्टों को सूचीबद्ध करना, एक ‘आसान’ काम नहीं है। यह काम बहुत अधिक विशेषज्ञता और ज्ञान की आवश्यकता होती है।
मोनोलिथ कानूनी कार्यालय (Monolith Law Office) एक ऐसा कानूनी कार्यालय है जिसमें पूर्व IT इंजीनियर के प्रमुख वकील और उपरोक्त तरह के इंटरनेट अनुसंधान के विशेषज्ञ स्टाफ शामिल हैं, जो प्रतिष्ठा के क्षति के प्रबंधन में विशेषज्ञता रखते हैं। इंटरनेट अनुसंधान कैसे किया जाना चाहिए, नीचे, हम विवरण देते हैं।
Google खोज परिणाम और उनकी सीमाएं क्या हैं?
नेटवर्क अनुसंधान का मूल तत्व, बिना किसी संदेह के, Google खोज है। हालांकि, Google पर, जब आप अपने द्वारा खोजने योग्य कीवर्ड, उदाहरण के लिए, गिरफ्तारी के लेख को हटाने के मामले में “अपना नाम गिरफ्तार” जैसे कीवर्ड को खोजते हैं और प्रदर्शित होने वाले खोज परिणामों में, तीन मायनों में, सीमाएं होती हैं।
Google खोज के लिए वेबपेज
इंटरनेट पर “अनगिनत” वेबपेज मौजूद हैं। इंटरनेट पर कुल वेबपेजों की संख्या को सिद्धांततः मापना संभव नहीं है, लेकिन एक विचार के अनुसार, “वेबसाइटों” की संख्या वर्तमान में लगभग 1.8 बिलियन कही जाती है।
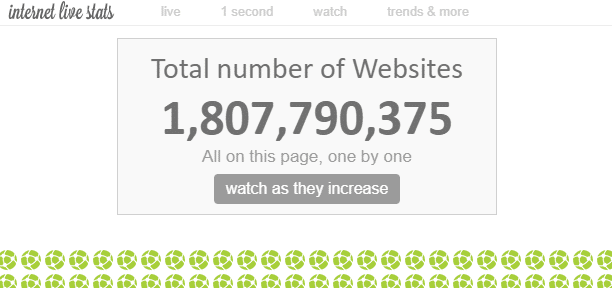
एक वेबसाइट में कई वेबपेज होते हैं, इसलिए वेबपेजों की संख्या उससे कहीं अधिक होती है।
और Google खोज का अर्थ है, सीधे शब्दों में,
- Google का बॉट (Googlebot) इंटरनेट पर खोज करता है, और पहले से ज्ञात वेबपेजों से लिंक का पता लगाकर नए वेबपेज का पता लगाता है
- उस पेज की सामग्री को समझता है (इंडेक्स पंजीकरण)
- जब उस पेज में शामिल कीवर्ड की खोज की जाती है, तो उस पेज को खोज परिणाम में प्रदर्शित करता है
इस प्रकार की प्रक्रिया होती है। मेरा कहने का मतलब यह है कि, Google खोज में प्रदर्शित होने वाले वेबपेज, वे हैं जिन्हें Google ने “उपरोक्त तरीके से इंडेक्स पंजीकृत किया है”, न कि “सभी वेबपेज”। इसका मतलब है, जब तक आप Google खोज का उपयोग कर रहे हैं, आप “वेबपेज जिन्हें Google ने अभी तक इंडेक्स पंजीकृत नहीं किया है” को नहीं खोज सकते, और वास्तव में, इंटरनेट पर सभी वेबपेज को पूरी तरह से खोजने का कोई तरीका इस दुनिया में मौजूद नहीं है।
“समान” वेबपेज खोज परिणामों से बाहर रखे जाते हैं
इसके अलावा, Google ने “इंडेक्स में पंजीकृत सभी वेबपेजों में से, खोज कीवर्ड वाले सभी वेबपेज” को खोज परिणामों में प्रदर्शित करने का वादा नहीं किया है। यह एक ऐसा मामला हो सकता है जिसे आपने Google खोज का सामान्य उपयोग करते समय देखा हो। खोज परिणामों के अंतिम पृष्ठ पर प्रदर्शित “सबसे सटीक खोज परिणाम प्रदर्शित करने के लिए, ऊपरी ○ पृष्ठों के समान पृष्ठ बाहर रखे गए हैं।” ऐसा कुछ होता है।
उदाहरण के लिए,
- कोई खबर बड़े खबर साइटों पर प्रथम बार प्रसारित होती है
- खबर लेखों को संघटित करने वाली सेवाओं पर पुनः प्रकाशित किया जाता है
- व्यक्तिगत साइटों पर भी पुनः प्रकाशित किया जाता है
ऐसे मामले में, यदि एक ही सामग्री वाले पृष्ठ खोज परिणामों को भर देते हैं, तो उपयोगकर्ताओं के लिए इसका उपयोग करना कठिन हो जाता है, इसलिए Google ने “समान” पृष्ठों को, उपरोक्त मामले में 2 और 3 को, खोज परिणामों से स्वचालित रूप से बाहर रख दिया है।
यह “अवज्ञा प्रभाव पृष्ठों को सफाई करना चाहते हैं” वाले मामले में, जरूरी नहीं है कि यह “सुविधाजनक” विन्यास हो। उदाहरण के लिए, यदि उपरोक्त “कोई खबर” आपके भूतकाल की गिरफ्तारी की खबर हो, तो
खोज परिणामों में प्रदर्शित होने वाली “1. बड़े खबर साइटों की प्रथम प्रसारण लेख” केवल थी, इसलिए उस पृष्ठ को हटा दिया गया, और 1 को हटाने के बाद, “2. खबर लेखों को संघटित करने वाली सेवा पर पुनः प्रकाशित लेख” अब Google खोज परिणामों में प्रदर्शित होने लगा
ऐसी स्थिति हो सकती है।
इस समस्या का समाधान यह है कि ऊपरी प्रदर्शन में “सभी खोज परिणाम प्रदर्शित करने के लिए, यहां से पुनः खोजें” वाले हिस्से पर क्लिक करें, लेकिन यदि आप इस विन्यास और कार्यक्षमता के बारे में नहीं जानते, तो आपको “अवज्ञा पृष्ठ” को “छूट” जाने की संभावना हो सकती है।
एक ही साइट से प्रदर्शित होने वाले लेखों की संख्या में एक अधिकतम सीमा होती है

इसके अलावा, Google ने एक वेबसाइट से प्रदर्शित होने वाले खोज परिणाम पृष्ठों की संख्या पर एक अधिकतम सीमा निर्धारित की है। यह विशेषता थोड़ी जटिल होती है, लेकिन सीधे शब्दों में कहें तो, “एक ही साइट से प्रदर्शित होने वाले पृष्ठों की संख्या अधिकतम 2 होती है।”
इसका मतलब यह है कि, उदाहरण के लिए, अगर Yahoo! ज्ञान बैग में, किसी कंपनी या व्यक्ति के नाम के साथ Q&A 5 होते हैं, तो भी Google के खोज परिणामों में, Yahoo! ज्ञान बैग के पृष्ठों की संख्या अधिकतम 2 ही होती है। यही बात चर्चा मंचों के मामले में भी लागू होती है, अगर किसी कीवर्ड के साथ 5chan थ्रेड 5 होते हैं, तो भी Google खोज परिणामों में अधिकतम 2 ही प्रदर्शित होते हैं।
- गिरफ्तारी के लेख
- पुनः गिरफ्तारी के लेख
- दोषी निर्णय के लेख
और अगर 3 लेख एक ही समाचार साइट पर मौजूद होते हैं, तो Google खोज परिणामों में कम से कम किसी एक (3-2=1) को प्रदर्शित नहीं करेगा।
जब किसी कीवर्ड को खोजा जाता है, तो एक ही साइट (जैसे कि Yahoo! ज्ञान बैग, विशेष चर्चा मंच, विशेष समाचार साइट आदि) के पृष्ठों की बड़ी संख्या खोज परिणामों में होती है, जो उपयोगकर्ताओं के लिए असुविधाजनक होती है, इसलिए Google ने ऐसी विशेषता तैयार की है।
हालांकि, यह विशेषता भी, “अवगुण्ठन पीड़ित पृष्ठों को सफाई करना चाहते हैं” जैसे मामले में, जरूरी नहीं है कि “सुविधाजनक” हो।
उदाहरण के लिए, अगर Yahoo! ज्ञान बैग के नकरात्मक Q&A को न्यायालय की प्रक्रिया के माध्यम से हटाना चाहते हैं, और Google खोज परिणामों को देखकर “लक्ष्य केवल 2 हैं” का निर्णय लेते हैं और प्रक्रिया को आगे बढ़ाते हैं, तो हटाने की सफलता के बाद, शेष 5-2=3 में से किसी एक को खोज परिणामों में प्रदर्शित किया जाएगा।
Google की उन्नत खोज के लिए “खोज सूत्र” का उपयोग
उपरोक्त समस्याओं में से, विशेष रूप से तीसरी समस्या को हल करने के लिए आवश्यक है Google का “खोज सूत्र” कहलाने वाला सुविधा।
Google निश्चित रूप से, “इंटरनेट पर सम्पूर्ण, जिसमें उल्लिखित कीवर्ड शामिल होते हैं, पृष्ठों की खोज करने” की सुविधा (ग्लोबल खोज) के लिए, “प्रति साइट मूल रूप से 2 पृष्ठ” की अधिकतम सीमा निर्धारित करता है। हालांकि, “कीवर्ड site:लक्षित साइट का URL” नामक “खोज सूत्र” का उपयोग करने पर,
- निर्दिष्ट लक्षित साइट के लेखों को ही खोज का लक्ष्य बनाता है
- उस खोज परिणाम में, “प्रति साइट मूल रूप से 2 पृष्ठ” की अधिकतम सीमा नहीं होती है
ऐसी खोज कर सकते हैं।
“खोज सूत्र” वास्तव में अधिक जटिल होते हैं, और उपरोक्त समस्याओं को हल करने के लिए उपयोग किए जाने वाले खोज सूत्र आदि भी मौजूद हैं।
विशेष साइटों के लिए विशेष खोज उपाय
उदाहरण के लिए, Yahoo! ज्ञान बैग में अपना खुद का खोज कार्यक्षमता मौजूद है।
यह खोज, “Google द्वारा (यादृच्छिक रूप से) सूचीबद्ध किए गए वेबपेज” के बजाय “Yahoo! ज्ञान बैग के डाटाबेस को, सीधे Yahoo! ज्ञान बैग के खोज प्रोग्राम द्वारा खोजा गया है”। इसलिए, यह पहले बताए गए “Google ने अभी तक सूचीबद्ध नहीं किए गए वेबपेज भी मौजूद हैं” समस्या का समाधान होता है। “यदि यह Yahoo! ज्ञान बैग का पेज है, तो Yahoo! ज्ञान बैग की खोज कार्यक्षमता का उपयोग करके, सभी को बिना छूटे खोज सकते हैं”।
अर्थात,
किसी तथ्य (कंपनी की अनुचित घटना, व्यक्ति की गिरफ्तारी आदि) के बारे में, कम से कम, ग्लोबल खोज पर Yahoo! ज्ञान बैग के पेज का पता चलने पर, “site:” खोज सूत्र का उपयोग करने की तुलना में, Yahoo! ज्ञान बैग की खोज कार्यक्षमता का उपयोग करना, बिना छूटे सूचीबद्ध करने में सक्षम होगा।
यही बात है।
यह Twitter आदि के लिए भी सही है। Twitter की सेवाओं की प्रकृति के कारण, विषय बनने वाले तथ्यों (कंपनी की अनुचित घटना, व्यक्ति की गिरफ्तारी आदि) के बारे में ट्वीट, अधिकांश साइटों पर मौजूद होते हैं। ऐसे ट्वीट सभी Google में सूचीबद्ध नहीं होते हैं, और कम से कम, सभी ग्लोबल खोज पर प्रदर्शित नहीं होते हैं।
हटाने के लिए ‘1 आइटम’ की गिनती का तरीका

उचित सूचीबद्धता और ‘URL’ का संबंध
अब तक हमने ‘Google खोज आदि का उपयोग करके, संभवतः अधिक से अधिक वेब पेज (URL) कैसे ढूंढें’ के बारे में लिखा है, लेकिन, यह जरूरी नहीं है कि अगर आपने अधिक सूचीबद्ध कर लिया है तो वह ठीक है। हटाने के अनुरोध का लक्ष्य हमेशा ‘URL’ को इकाई के रूप में नहीं लेता है।
5चैनल के मामले में
यह विशेष रूप से बोर्ड साइट (5चैनल या उसकी कॉपी साइट आदि या अन्य बोर्ड साइट) के मामले में, समस्या बनने वाली बात है।
उदाहरण के लिए, अगर आप Google में किसी कीवर्ड को ‘site:5ch.net’ के खोज सूत्र के साथ, अर्थात, 5चैनल के भीतर से खोजते हैं, तो निम्नलिखित प्रकार के URL के खोज परिणाम के रूप में प्रदर्शित होने की स्थिति हो सकती है।
- ○○○.5ch.net/test/read.cgi/○○/○○○○/40
- ○○○.5ch.net/test/read.cgi/○○/○○○○/1-100
- ○○○.5ch.net/test/read.cgi/○○/○○○○/30-
5चैनल में,
- थ्रेड के URL के बाद रेस्पोंस नंबर लिखने से, केवल उस रेस्पोंस को प्रदर्शित करता है
- थ्रेड के URL के बाद ‘A-B’ जैसे रेस्पोंस नंबर की रेंज लिखने से, केवल उस रेंज के रेस्पोंस को प्रदर्शित करता है
- थ्रेड के URL के बाद ‘A-‘ जैसे रेस्पोंस नंबर की शुरुआत और ‘-‘ लिखने से, उस रेस्पोंस के बाद के सभी रेस्पोंस को प्रदर्शित करता है
यह एक ऐसा विशेषता है। अर्थात, केवल रेस्पोंस नंबर 40 में कीवर्ड लिखने से, विभिन्न URL (वेब पेज) ‘खोज परिणाम’ में प्रदर्शित हो जाते हैं।
हालांकि, जब बोर्ड साइट के खिलाफ हटाने का अनुरोध किया जाता है, तो उस अनुरोध की इकाई, कम से कम सिद्धांततः, ‘रेस्पोंस’ होती है। इसलिए, अगर आप रेस्पोंस नंबर 40 को हटाना चाहते हैं, तो सीधे
- ○○○.5ch.net/test/read.cgi/○○/○○○○/40
ऐसे URL को ही निकालना चाहिए, और बाकी दोनों को सूचीबद्ध करने की आवश्यकता नहीं है।
5चैनल कॉपी साइट और संग्रह साइट के मामले में
और यदि हम इसके बारे में बात करें, तो यह और भी जटिल हो जाता है, लेकिन वही 5चैनल (सिस्टम) की कॉपी साइट या ‘संग्रह साइट’ के मामले में, साइट के अनुसार, हटाने के अनुरोध की इकाई ‘रेस्पोंस’ नहीं ‘पेज (थ्रेड)’ होती है। ‘किस साइट के हटाने के अनुरोध का लक्ष्य क्या है’ यह पूरी तरह ‘नौहाउ’ क्षेत्र है।
https://monolith.law/reputation/delation-of-scraping-site-roundup-website[ja]
इसलिए,
- कानूनी हटाने के अनुरोध की इकाई के बारे में समझ
- किसी वेबसाइट के URL विन्यास (उदाहरण के लिए 5चैनल में उपरोक्त जैसे जटिल नियम होते हैं) के बारे में समझ
अगर नहीं होती है, तो ‘खोज परिणाम देखते हुए हटाने के लिए आइटम की सूचीबद्धता’ यह स्वयं मुश्किल हो जाता है।
ओपन वेब के अलावा खोज

और, अब तक हमने उन साइटों के बारे में बताया है जिन पर Google इंडेक्स पंजीकरण कर सकता है, लेकिन,
- Google जो निश्चित रूप से इंडेक्स पंजीकरण नहीं करेगा
- लेकिन प्रतिष्ठा जोखिम प्रबंधन के रूप में, हटाने के अनुरोध के लिए विचार करना चाहिए
ऐसी साइटें भी मौजूद हैं।
Google, ऊपर दिए गए विनिर्देशों के अनुसार, केवल ऐसी वेबसाइटों (ओपन वेब) को खोज के लिए लेता है जिसे किसी भी व्यक्ति ने लॉगिन किए बिना देख सकता है। लेकिन उदाहरण के लिए, इस दुनिया में, “पुराने अखबार के लेखों को एक साथ खोजकर देखने के लिए, पैद की (इसलिए उपयोगकर्ता पंजीकरण या लॉगिन किए बिना देखने के लिए नहीं कर सकते) वेब सेवाएं” भी मौजूद हैं।
उदाहरण के लिए, गिरफ्तारी के लेखों को हटाने के मामले में, ऊपर बताई गई अखबार डेटाबेस साइट की भी जांच करने की आवश्यकता होती है। क्योंकि कंपनियां या व्यक्तियों की विश्वसनीयता जांचने वाली कंपनियां, ऊपर बताई गई अखबार डेटाबेस साइट का उपयोग करती हैं।
अखबार डेटाबेस साइट के बारे में, नीचे दिए गए लेख में विस्तार से विवरण दिया गया है।
https://monolith.law/reputation/criminal-record-newspaper-database[ja]
सारांश
जैसा कि ऊपर दिखाया गया है, “इंटरनेट पर से, प्रतिष्ठा क्षति प्रबंधन के रूप में हटाने के लिए अनुरोध करने के लिए लक्ष्य की सूची बनाना” एक बहुत ही विशेषज्ञता वाला कार्य है। हमारे कानूनी दफ्तर में, जब हम प्रतिष्ठा क्षति प्रबंधन का काम लेते हैं, हम उपरोक्त तरह की लक्ष्य लेख सूची बनाते हैं, लेकिन यह कार्य IT और इंटरनेट की विशेषज्ञता पर आधारित है।
इंटरनेट पर प्रतिष्ठा क्षति प्रबंधन में, पेज (या बोर्ड रिस्पॉन्स) को हटाना केवल वकीलों द्वारा किया जा सकता है।
https://monolith.law/reputation/hiben-koui[ja]
हालांकि, इसके विपरीत, यह सूची बनाने का काम, जैसा कि इस लेख में संक्षेप में बताया गया है, एक बहुत ही उच्च स्तर की IT और इंटरनेट ज्ञान की मांग करता है। यही वजह है कि प्रतिष्ठा क्षति प्रबंधन के लिए, आपको IT और इंटरनेट की उच्च स्तर की विशेषज्ञता वाले कानूनी दफ्तर से संपर्क करना चाहिए। यद्यपि यह दोहराव हो जाता है, लेकिन यदि उपरोक्त सूची बनाने का काम कमजोर होता है, तो,
- सूचीबद्ध पेज को साफ करने के बावजूद, सूचीबद्ध करने के समय ग्लोबल खोज परिणाम में प्रदर्शित नहीं होने वाले अन्य पेज खोज परिणाम में प्रदर्शित होते हैं, और अतिरिक्त हटाने की आवश्यकता होती है, जिससे मूल बजट की गणना गलत हो जाती है।
- न्यायालय की प्रक्रिया के बारे में, जो मूल रूप से एक बार होनी चाहिए थी, वह 2 या 3 बार होने की आवश्यकता होती है, और अधिक खर्च की आवश्यकता होती है।
- न्यूज़पेपर डेटाबेस साइट आदि, ओपन वेब के अलावा पेज के अस्तित्व का पता नहीं चलता, और उदाहरण के लिए “गिरफ्तारी के लेख की खोज के कारण नौकरी में बाधा आती है” जैसी “समस्या” का समाधान नहीं होता है।
इसलिए ऐसी समस्याएं उत्पन्न होती हैं।
Category: Internet




















