Spiegazione su come esaminare attentamente gli articoli negativi online: un presupposto per le misure contro i danni alla reputazione

Nel caso in cui si desideri eliminare completamente le pagine web relative a scandali aziendali passati, incidenti di diffamazione, arresti o precedenti penali, la prima cosa da fare è elencare tutte queste pagine e post negativi senza lasciare nulla fuori. Se non si riesce a fare questo elenco, non si può procedere con le misure di gestione del rischio reputazionale guardando il volume totale, e c’è anche il rischio che, ad esempio, si debba ripetere una procedura giudiziaria, come un’ingiunzione provvisoria o un processo, che avrebbe dovuto essere risolta in una sola volta, a causa di un’omissione.
Tuttavia, elencare tutte le pagine web e i post che descrivono un certo fatto (ad esempio, scandali aziendali, incidenti di diffamazione, arresti o precedenti penali) su Internet non è affatto un compito “facile”. Questo compito richiede un alto grado di specializzazione e non può essere svolto senza le competenze appropriate.
Lo studio legale Monolith, con il suo avvocato capo, ex ingegnere IT, e il suo staff specializzato in ricerche online, è uno studio legale specializzato nella gestione del rischio reputazionale. Di seguito spiegheremo come dovrebbe essere condotta la ricerca online.
Cosa sono i risultati di ricerca di Google e i suoi limiti?
La base della ricerca online è, senza dubbio, la ricerca su Google. Tuttavia, i risultati di ricerca visualizzati su Google, quando si cercano parole chiave che si desidera trovare, come ad esempio “il mio nome arresto” nel caso della rimozione di un articolo sull’arresto, hanno dei limiti in tre aspetti.
Pagine web oggetto di ricerca su Google
Su Internet esistono “innumerevoli” pagine web. Sebbene il numero totale di pagine web su Internet sia teoricamente impossibile da misurare, si dice che il numero di “siti web” sia attualmente di circa 1,8 miliardi.
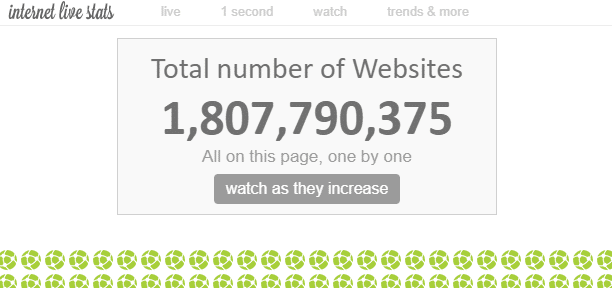
Dato che esistono molteplici pagine web all’interno di un singolo sito web, il numero di pagine web è molto superiore a quello.
E la ricerca su Google, per dirla in modo semplice, avviene attraverso il seguente meccanismo:
- Il bot di Google (Googlebot) esplora Internet, rileva nuove pagine web che possono essere aperte seguendo i link dalle pagine web conosciute
- Comprende il contenuto di quella pagina (registrazione nell’indice)
- Quando viene effettuata una ricerca con le parole chiave contenute in quella pagina, mostra quella pagina nei risultati di ricerca
Quello che voglio dire è che ciò che viene visualizzato nella ricerca di Google sono le pagine web che Google ha registrato nell’indice “come sopra”, non “tutte le pagine web”. In altre parole, finché si utilizza la ricerca di Google, non è possibile trovare “pagine web che Google non ha ancora registrato nell’indice”, e non esiste un modo per cercare tutte le pagine web su Internet senza perdere nulla.
Pagine web “simili” vengono escluse dai risultati di ricerca
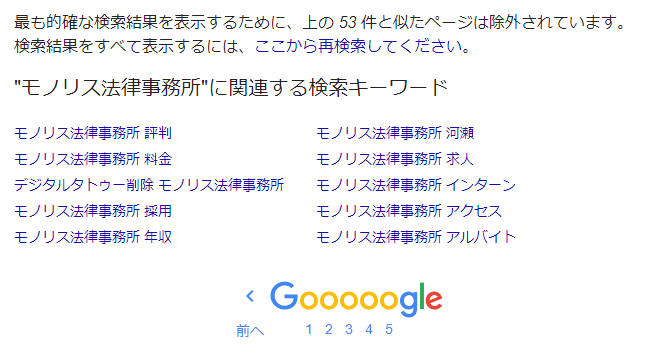
Inoltre, Google non mostra “tutte le pagine web che contengono la parola chiave di ricerca e che sono state indicizzate” nei risultati di ricerca. Questo è qualcosa che potreste aver notato utilizzando normalmente la ricerca di Google. Si tratta del messaggio che appare all’ultima pagina dei risultati di ricerca, che dice “Per mostrare i risultati di ricerca più pertinenti, le pagine simili a quelle sopra sono state escluse”.
Ad esempio,
- Una notizia viene distribuita per la prima volta su un grande sito di notizie
- La notizia viene ripubblicata su servizi che raccolgono articoli di notizie
- La notizia viene anche ripubblicata su siti personali, ecc.
In questi casi, se le pagine con lo stesso contenuto riempissero i risultati di ricerca, sarebbe difficile per gli utenti utilizzarli. Pertanto, Google esclude automaticamente le pagine “simili” dai risultati di ricerca, come i numeri 2 e 3 nell’esempio sopra.
Questo non è necessariamente un’implementazione “utile” se si vuole “eliminare completamente le pagine di diffamazione”. Ad esempio, se la “notizia” nell’esempio sopra fosse un articolo sul tuo arresto passato,
Se l’unico risultato di ricerca visualizzato fosse “1. L’articolo originale del grande sito di notizie” e tu lo avessi rimosso, l’articolo “2. Ripubblicato su un servizio di raccolta di articoli di notizie” potrebbe iniziare ad apparire nei risultati di ricerca di Google una volta che l’1 è stato rimosso.
Questo è un possibile scenario.
Per risolvere questo problema, è sufficiente fare clic sulla parte che dice “Per visualizzare tutti i risultati di ricerca, effettua una nuova ricerca da qui” nella visualizzazione sopra. Tuttavia, se non si conosce questa funzione o implementazione, si potrebbe “perdere” una pagina di diffamazione.
C’è un limite al numero di articoli visualizzati dallo stesso sito

Inoltre, Google ha impostato un limite al numero di pagine dei risultati di ricerca visualizzate da un singolo sito web. Questa specifica è un po’ complessa, ma per semplificare, “il massimo numero di pagine visualizzate dallo stesso sito è due”.
Per esempio, supponiamo che ci siano cinque Q&A in cui appare il nome di un’azienda o di un individuo su Yahoo! Chiebukuro (un sito di domande e risposte giapponese). Anche se si cercano il nome dell’azienda o dell’individuo su Google, al massimo due pagine di Yahoo! Chiebukuro appariranno nei risultati di ricerca. Lo stesso vale per i forum, anche se ci sono cinque thread su 5channel (un forum di discussione giapponese) che contengono una certa parola chiave, al massimo due appariranno nei risultati di ricerca di Google. Inoltre, per esempio, se una persona ha,
- Un articolo sull’arresto
- Un articolo sul re-arresto
- Un articolo sulla condanna
Se ci sono tre articoli sullo stesso sito di notizie, almeno uno di essi (3-2=1) non apparirà nei risultati di ricerca di Google.
Quando si cerca una certa parola chiave, se le pagine all’interno dello stesso sito (ad esempio Yahoo! Chiebukuro, un particolare forum, un particolare sito di notizie, ecc.) appaiono in gran numero nei risultati di ricerca, ciò può essere scomodo per l’utente, quindi Google ha questa specifica.
Tuttavia, questa specifica non è necessariamente “facile da usare” se si vuole “eliminare tutte le pagine di diffamazione”.
Ad esempio, se si vuole rimuovere una Q&A negativa da Yahoo! Chiebukuro attraverso un procedimento legale, e si guarda ai risultati di ricerca di Google e si decide che “ci sono solo due obiettivi”, e si procede con il procedimento, quando la rimozione ha successo, uno dei restanti 3 (5-2=3) potrebbe apparire nei risultati di ricerca.
Ricerca avanzata su Google utilizzando “Operatori di ricerca”
Per risolvere in particolare il terzo problema sopra menzionato, è necessario utilizzare una funzione di Google chiamata “Operatori di ricerca”.
Google, infatti, ha impostato un limite di “2 pagine per sito” per la funzione che “cerca pagine che contengono la parola chiave da tutto l’Internet” (ricerca globale). Tuttavia, utilizzando l’operatore di ricerca “parola chiave site:URL del sito target”, è possibile:
- Eseguire una ricerca solo negli articoli all’interno del sito target specificato
- Non esiste un limite di “2 pagine per sito” per i risultati di questa ricerca
Questo tipo di ricerca può essere eseguita.
Gli “Operatori di ricerca” sono in realtà più complessi e esistono anche operatori di ricerca utilizzati per risolvere problemi diversi da quelli sopra menzionati.
Metodi di ricerca speciali per siti specifici
Ad esempio, Yahoo! Chiebukuro (Yahoo! Answers in Giappone) ha una funzione di ricerca unica.
Questa ricerca non riguarda “le pagine web indicizzate da Google (casualmente)”, ma “i risultati della ricerca del database interno di Yahoo! Chiebukuro effettuata direttamente dal programma di ricerca di Yahoo! Chiebukuro”. Questo risolve il problema menzionato inizialmente, ovvero “esistono pagine web che Google non ha ancora indicizzato”. In altre parole, “se si tratta di una pagina all’interno di Yahoo! Chiebukuro, utilizzando la funzione di ricerca di Yahoo! Chiebukuro, è possibile trovare tutto senza omissioni”.
Quindi,
Se si scopre una pagina di Yahoo! Chiebukuro in una ricerca globale riguardante un certo fatto (scandali aziendali, arresti di individui, ecc.), utilizzare la funzione di ricerca interna di Yahoo! Chiebukuro piuttosto che la formula di ricerca “site:” permette di ottenere un elenco completo senza omissioni.
Questo è il punto.
Lo stesso vale per Twitter. A causa della natura del suo servizio, Twitter è un sito che spesso ha molti tweet riguardanti fatti che diventano argomento di discussione (scandali aziendali, arresti di individui, ecc.). Non tutti questi tweet sono necessariamente indicizzati da Google, e non tutti vengono necessariamente visualizzati in una ricerca globale.
Metodo di conteggio per “1” elemento da eliminare

La relazione tra un elenco appropriato e l'”URL”
Finora, abbiamo discusso “come raccogliere il maggior numero possibile di pagine web (URL) utilizzando Google Search e simili”, ma non è necessariamente vero che più elementi si elencano, meglio è. Questo perché l’oggetto di una richiesta di eliminazione non è necessariamente l'”URL” come unità di misura.
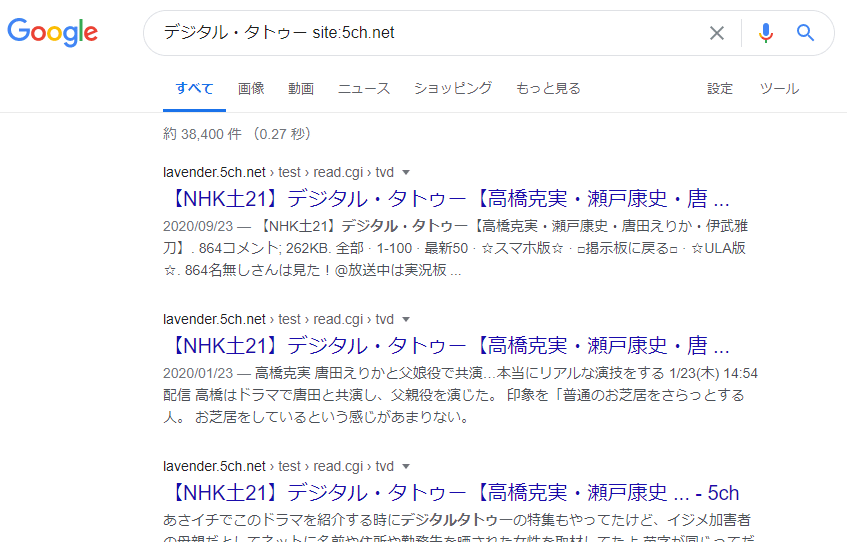
Nel caso di 5ch (un forum online giapponese)
Questo è un problema particolarmente rilevante nel caso di siti di forum come 5ch e i suoi siti clone, e altri siti di forum.
Ad esempio, se si cerca una certa parola chiave su Google con la formula di ricerca “site:5ch.net”, ovvero cercando all’interno di 5ch, potrebbero apparire nei risultati di ricerca URL come i seguenti:
- ○○○.5ch.net/test/read.cgi/○○/○○○○/40
- ○○○.5ch.net/test/read.cgi/○○/○○○○/1-100
- ○○○.5ch.net/test/read.cgi/○○/○○○○/30-
5ch ha le seguenti caratteristiche:
- Se si scrive il numero di risposta dopo l’URL del thread, solo quella risposta verrà visualizzata
- Se si scrive un intervallo di numeri di risposta come “A-B” dopo l’URL del thread, solo le risposte in quell’intervallo verranno visualizzate
- Se si scrive un numero di risposta iniziale e un “-” dopo l’URL del thread, verranno visualizzate tutte le risposte da quel numero in poi
In altre parole, se la parola chiave è scritta solo nella risposta numero 40, varie pagine web (URL) verranno visualizzate nei “risultati di ricerca”.
Tuttavia, quando si fa una richiesta di eliminazione a un sito di forum, l’unità di misura per l’oggetto della richiesta è, almeno in linea di principio, la “risposta”. Pertanto, se si desidera eliminare la risposta numero 40, basta estrarre l’URL
- ○○○.5ch.net/test/read.cgi/○○/○○○○/40
e non è necessario elencare gli altri due.
Nel caso di siti clone e siti di aggregazione di 5ch
Per aggiungere, anche se è un po’ complicato, anche se si tratta dello stesso 5ch (o simili), nel caso dei suoi siti clone e dei “siti di aggregazione”, a seconda del sito, l’unità di misura per una richiesta di eliminazione non è la “risposta”, ma la “pagina (thread)”. Determinare “quale è l’oggetto di una richiesta di eliminazione per quale sito” rientra completamente nel campo del “know-how”.
Per questo motivo,
- la comprensione dell’unità di misura per una richiesta di eliminazione legale
- la comprensione delle specifiche dell’URL di un sito web (ad esempio, 5ch ha le complesse regole sopra descritte)
sono necessarie per “elencare gli oggetti di eliminazione mentre si guardano i risultati di ricerca”.
Ricerca al di fuori del web aperto

Finora, abbiamo discusso dei siti che Google potrebbe indicizzare, ma esistono anche gruppi di siti che:
- Google non indicizzerà sicuramente
- Tuttavia, dovrebbero essere considerati per le richieste di rimozione come parte della gestione del rischio reputazionale
Google, per sua natura, non considera come target di ricerca i siti web che non sono aperti al pubblico (web aperto) e che possono essere visualizzati da chiunque senza effettuare il login. Tuttavia, esistono servizi web a pagamento nel mondo, come quelli che consentono di cercare e visualizzare in blocco articoli passati di giornali (e quindi non possono essere visualizzati senza registrazione o login).
Ad esempio, nel caso della rimozione di articoli sull’arresto, è necessario esaminare attentamente anche i siti di database di giornali. Questo perché molte aziende che indagano sulla credibilità di aziende o individui utilizzano questi siti di database di giornali.
Per ulteriori dettagli sui siti di database di giornali, si prega di consultare l’articolo sottostante.
Riassunto
Come sopra illustrato, “elencare le voci da rimuovere su Internet come misura di gestione del rischio reputazionale” è un compito altamente specializzato. Il nostro studio legale svolge questo tipo di elencazione quando si occupa di gestione del rischio reputazionale, ma questo lavoro presuppone una competenza specialistica in IT e Internet.
La rimozione di pagine (o post su forum) su Internet come misura di gestione del rischio reputazionale è un compito che solo un avvocato può svolgere.
Tuttavia, d’altra parte, come spiegato in questo articolo, l’elenco richiede una conoscenza molto avanzata di IT e Internet. Questo è uno dei principali motivi per cui si dovrebbe rivolgere a uno studio legale con una competenza avanzata in IT e Internet per la gestione del rischio reputazionale. Se l’elenco non è accurato, si possono verificare problemi come:
- Anche se tutte le pagine elencate vengono rimosse, altre pagine che non erano visibili nei risultati di ricerca globale al momento dell’elenco potrebbero apparire nei risultati di ricerca, rendendo necessaria una rimozione aggiuntiva e rendendo il calcolo del budget iniziale notevolmente errato.
- Per quanto riguarda le procedure giudiziarie, invece di essere risolte in una sola volta, potrebbero essere necessarie due o tre volte, comportando costi eccessivi.
- Non si nota l’esistenza di pagine al di fuori del web aperto, come i siti di database di giornali, e quindi non si risolve il “problema” di, ad esempio, “avere difficoltà a trovare lavoro a causa di articoli di arresto”.
Questi sono i problemi che possono sorgere.
Category: Internet
Related Articles

Eliminazione di tutti i video in caso di rottura? Punti da stabilire per i YouTuber coppia duran.
Internet

Come evitare che il proprio nome appaia nei risultati di ricerca? Spiegazione del metodo di rimo.
Internet

Quando è possibile eliminare i post su Twitter riguardanti un precedente arresto? Spiegazione de.
Internet



Spiegazione dei punti chiave della revisione del 'Diritto d'autore giapponese' del 2020: fino a .
Internet

Leak di informazioni riservate come i dati dei clienti su un forum anonimo! Metodi per eliminare.
Internet













