Premisa măsurilor împotriva daunelor reputaționale: Explicarea metodei de examinare a articolelor negative de pe internet

În cazul în care doriți să eliminați paginile web care se referă la scandaluri anterioare ale companiei, incidente de defăimare, arestări sau antecedente penale, primul pas este să creați o listă completă a acestor pagini și postări negative. Fără această listă, nu puteți avansa cu măsurile de gestionare a riscurilor de reputație, privind volumul total. De exemplu, există riscul ca procedurile judiciare, cum ar fi ordonanțele provizorii sau procesele, care ar fi trebuit să se finalizeze într-o singură etapă, să necesite o a doua etapă din cauza unor omisiuni.
Însă, listarea tuturor paginilor web și postărilor care menționează un anumit fapt (de exemplu, scandaluri ale companiei, incidente de defăimare, arestări sau antecedente penale) pe internet nu este deloc o sarcină “simplă”. Această parte a procesului necesită o mare specializare și nu poate fi realizată fără cunoștințe specifice.
Cabinetul nostru de avocatură, Monolith Law Office, are avocați cu experiență în IT și personal specializat în cercetarea pe internet, oferind servicii profesionale în gestionarea riscurilor de reputație. Vom explica mai jos cum ar trebui să se desfășoare cercetarea pe internet.
Ce sunt rezultatele căutării Google și care sunt limitele lor?
Baza oricărei cercetări online este, desigur, căutarea Google. Cu toate acestea, rezultatele căutării pe Google pentru cuvintele cheie pe care doriți să le căutați, de exemplu, în cazul eliminării unui articol despre arestare, cuvinte cheie precum “numele meu arestare”, au limite în trei sensuri.
Pagini web vizate de căutarea Google
Pe internet există un număr “incontabil” de pagini web. Deși numărul total de pagini web de pe internet nu poate fi măsurat teoretic, se spune că numărul de “site-uri web” este de aproximativ 1,8 miliarde în prezent.
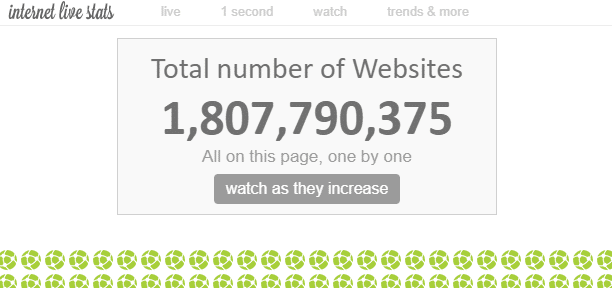
Având în vedere că există mai multe pagini web pe un singur site, numărul de pagini web este mult mai mare decât acesta.
Și căutarea Google, simplu spus, este:
- Botul Google (Googlebot) scanează internetul, detectează pagini web noi care pot fi deschise urmând linkuri din paginile web cunoscute
- Înțelege conținutul acelei pagini (înregistrare în index)
- Afișează acea pagină în rezultatele căutării atunci când se efectuează o căutare cu cuvinte cheie incluse în acea pagină
Este realizată prin acest mecanism. Ceea ce vreau să spun este că ceea ce este afișat în căutarea Google este doar “paginile web pe care Google le-a înregistrat în index în acest fel”, nu “toate paginile web”. Adică, atâta timp cât utilizați căutarea Google, nu puteți găsi “pagini web pe care Google încă nu le-a înregistrat în index”, și mai mult, nu există nicio metodă în această lume pentru a căuta toate paginile web de pe internet fără a omite niciuna.
“Paginile web ‘similare’ sunt excluse din rezultatele căutării”
De asemenea, Google nu afișează în rezultatele căutării “toate paginile web care conțin cuvântul cheie căutat și care sunt înregistrate în index”. Acest lucru poate fi observat în mod obișnuit atunci când folosiți căutarea Google. Este vorba despre mesajul care apare pe ultima pagină a rezultatelor căutării, care spune “Pentru a afișa cele mai relevante rezultate, paginile similare cu cele ○ de mai sus au fost excluse”.
De exemplu,
- o anumită știre este distribuită inițial pe un site de știri de top
- știrea este republicată pe servicii care adună articole de știri
- știrea este de asemenea republicată pe site-uri personale etc.
În acest caz, dacă paginile cu același conținut ar umple rezultatele căutării, ar fi dificil pentru utilizatori să le folosească, așa că Google exclude automat “paginile similare”, în acest caz 2 și 3, din rezultatele căutării.
Aceasta nu este neapărat o caracteristică “utilă” dacă doriți să “ștergeți toate paginile cu reputație negativă”. De exemplu, dacă “anumita știre” menționată mai sus este un articol despre arestarea ta din trecut,
Dacă doar “1. Articolul inițial de pe site-ul de știri de top” a fost afișat în rezultatele căutării și ați șters doar acea pagină, odată cu dispariția 1, “2. Articolul republicat pe serviciul de adunare a știrilor” ar putea începe să apară în rezultatele căutării Google
Acesta este un scenariu posibil.
Pentru a rezolva această problemă, trebuie doar să faceți clic pe partea care spune “Pentru a afișa toate rezultatele căutării, căutați din nou de aici”, dar dacă nu cunoașteți această caracteristică sau funcție, există posibilitatea să “ratați” paginile cu reputație negativă.
Există un limită pentru numărul de articole afișate din același site

În plus, Google stabilește o limită pentru numărul de pagini de rezultate ale căutării care sunt afișate dintr-un singur site web. Această specificație este puțin complexă, dar simplu spus, “numărul maxim de pagini afișate din același site este de 2”.
Adică, de exemplu, chiar dacă există 5 întrebări și răspunsuri în care apare numele unei companii sau al unei persoane pe Yahoo! Răspunsuri, în rezultatele căutării Google pentru numele companiei sau persoanei respective, paginile din Yahoo! Răspunsuri vor fi afișate la maximum 2 pagini. Același lucru este valabil și pentru forumuri, chiar dacă există 5 thread-uri pe 5chan care conțin un anumit cuvânt cheie, în rezultatele căutării Google vor fi afișate doar maxim 2. De asemenea, de exemplu, dacă o persoană are,
- un articol despre arestarea sa
- un articol despre re-arestarea sa
- un articol despre condamnarea sa
și cele 3 articole există pe același site de știri, cel puțin unul dintre ele (3-2=1) nu va fi afișat în rezultatele căutării Google.
Când căutați un anumit cuvânt cheie, dacă paginile din același site (de exemplu, Yahoo! Răspunsuri, un anumit forum, un anumit site de știri etc.) apar în număr mare în rezultatele căutării, acest lucru poate fi incomod pentru utilizatori, așa că Google a stabilit această specificație.
Însă, această specificație nu este neapărat “ușor de utilizat” atunci când doriți să “ștergeți toate paginile cu reputație negativă”.
De exemplu, dacă doriți să eliminați întrebările și răspunsurile negative de pe Yahoo! Răspunsuri prin proceduri judiciare, și vă uitați la rezultatele căutării Google și decideți că “doar 2 sunt relevante” și continuați procedura, atunci când ștergerea este reușită, una dintre cele 3 rămase din 5-2=3 va începe să apară în rezultatele căutării.
Căutare avansată Google folosind “formule de căutare”
Dintre problemele menționate mai sus, funcția “formulă de căutare” a Google este necesară în special pentru a rezolva a treia problemă.
Google, într-adevăr, stabilește o limită de “2 pagini de bază per site” pentru funcția sa de “căutare a paginilor care conțin cuvântul cheie respectiv din întregul internet” (căutare globală). Cu toate acestea, dacă utilizați “formula de căutare” care este “cuvânt cheie site:URL-ul site-ului țintă”, puteți efectua o căutare care:
- Efectuează căutări doar în articolele din site-ul țintă specificat
- Rezultatele acestei căutări nu au o limită de “2 pagini de bază per site”
“Formulele de căutare” sunt de fapt mai complexe și există și alte formule de căutare care sunt utilizate pentru a rezolva problemele în afara celor menționate mai sus.
Mijloace speciale de căutare pentru anumite site-uri
De exemplu, Yahoo! Chiebukuro (Yahoo! Answers în Japonia) are o funcție de căutare unică.
Această căutare nu este rezultatul “paginilor web indexate (întâmplător) de Google”, ci “baza de date din Yahoo! Chiebukuro, căutată direct de programul de căutare Yahoo! Chiebukuro”. Acest lucru rezolvă problema menționată inițial, că “există pagini web pe care Google încă nu le-a indexat”. Cu alte cuvinte, “dacă este o pagină din Yahoo! Chiebukuro, atâta timp cât folosiți funcția de căutare Yahoo! Chiebukuro, o puteți găsi fără a pierde nimic”.
Prin urmare,
În cazul unui anumit fapt (scandalul unei companii, arestarea unei persoane etc.), dacă cel puțin o pagină Yahoo! Chiebukuro este descoperită în căutarea globală, folosirea funcției de căutare Yahoo! Chiebukuro poate oferi o listă mai completă decât utilizarea formulei de căutare “site:”.
Acesta este punctul.
Același lucru este valabil și pentru Twitter. Datorită naturii serviciului său, Twitter este un site unde există adesea mai multe tweet-uri despre un fapt care a devenit subiect de discuție (scandalul unei companii, arestarea unei persoane etc.). Nu toate aceste tweet-uri sunt neapărat indexate de Google și, cel puțin, nu toate sunt afișate în căutarea globală.
Metoda de numărare a “unei singure” intrări pentru ștergere

Relația dintre listarea adecvată și “URL”
Până acum, am scris despre “metoda de a colecta cât mai multe pagini web (URL-uri) posibile folosind Google Search etc.”, dar nu înseamnă că este bine dacă putem lista multe. Acest lucru se datorează faptului că obiectul cererii de ștergere nu este neapărat “URL” ca unitate.
În cazul 5chan
Acesta este un subiect care devine o problemă, în special în cazul site-urilor de tip forum (cum ar fi 5chan și site-urile sale copiate, și alte site-uri de forum).
De exemplu, dacă căutați un anumit cuvânt cheie în Google cu formula de căutare “site:5ch.net”, adică căutând în 5chan, există cazuri în care URL-uri precum cele de mai jos sunt afișate ca rezultate ale căutării.
- ○○○.5ch.net/test/read.cgi/○○/○○○○/40
- ○○○.5ch.net/test/read.cgi/○○/○○○○/1-100
- ○○○.5ch.net/test/read.cgi/○○/○○○○/30-
5chan are specificații precum:
- Dacă numărul de răspunsuri este scris după URL-ul thread-ului, doar acel răspuns este afișat
- Dacă intervalul numărului de răspunsuri este scris ca “A-B” după URL-ul thread-ului, doar răspunsurile din acel interval sunt afișate
- Dacă numărul de început al răspunsurilor și “-” sunt scrise după URL-ul thread-ului, răspunsurile de după acel număr sunt afișate
În alte cuvinte, doar pentru că cuvântul cheie este scris în răspunsul numărul 40, diverse URL-uri (pagini web) sunt afișate ca “rezultate ale căutării”.
Însă, atunci când facem o cerere de ștergere pentru un site de forum, unitatea obiectului cererii este, cel puțin în principiu, “răspunsul”. Prin urmare, dacă doriți să ștergeți răspunsul numărul 40, pur și simplu
- ○○○.5ch.net/test/read.cgi/○○/○○○○/40
Extrageți doar acest URL, și nu este necesar să listați celelalte două.
În cazul site-urilor copiate 5chan și site-urilor de rezumat
Și dacă adaug, deși este o poveste puțin mai complicată, chiar și în cazul 5chan (și altele asemenea), în cazul site-urilor sale copiate și al “site-urilor de rezumat”, în funcție de site, unitatea cererii de ștergere nu este “răspunsul”, ci “pagina (thread-ul)”. “Ce este obiectul cererii de ștergere pentru care site” este complet în domeniul “know-how”.
https://monolith.law/reputation/delation-of-scraping-site-roundup-website[ja]
Prin urmare,
- Înțelegerea unității cererii de ștergere legală
- Înțelegerea specificațiilor URL-ului unui anumit site web (de exemplu, 5chan are reguli complexe precum cele de mai sus)
Dacă nu există, va fi dificil să “listați obiectele de ștergere în timp ce vedeți rezultatele căutării”.
Căutare în afara web-ului deschis

Până acum, am discutat despre site-urile pe care Google le-ar putea indexa, dar există și:
- Site-uri pe care Google nu le va indexa cu siguranță
- Dar care ar trebui luate în considerare pentru solicitările de ștergere în cadrul gestionării daunelor la reputație
Aceste site-uri există de asemenea.
Google, datorită specificațiilor sale, nu include în căutările sale decât site-urile web deschise (open web), care pot fi vizualizate de oricine fără a se autentifica. Cu toate acestea, există, de exemplu, servicii web plătite care permit căutarea și vizualizarea în bloc a articolelor vechi din ziare (și, prin urmare, nu pot fi vizualizate fără înregistrare sau autentificare).
De exemplu, în cazul ștergerii articolelor despre arestări, este necesar să se examineze cu atenție și site-urile de baze de date ale ziarelor. Acest lucru se datorează faptului că multe companii care investighează creditul companiilor sau al indivizilor folosesc aceste site-uri de baze de date ale ziarelor.
Detalii despre site-urile de baze de date ale ziarelor pot fi găsite în articolul de mai jos.
https://monolith.law/reputation/criminal-record-newspaper-database[ja]
Concluzie
După cum am menționat mai sus, “compilarea unei liste cu țintele pentru solicitările de ștergere ca măsură împotriva daunelor de reputație pe internet” este o sarcină cu un grad ridicat de specializare. Biroul nostru efectuează această listare a articolelor țintă atunci când preluăm măsurile împotriva daunelor de reputație, dar această activitate presupune o expertiză specializată în IT și internet.
Ștergerea paginilor (sau a răspunsurilor pe forumuri) ca măsură împotriva daunelor de reputație pe internet este o sarcină pe care numai un avocat o poate efectua.
https://monolith.law/reputation/hiben-koui[ja]
Pe de altă parte, această listare necesită cunoștințe de IT și internet, așa cum am explicat în acest articol, este o sarcină care necesită un nivel ridicat de expertiză. Acesta este unul dintre motivele principale pentru care ar trebui să solicitați măsurile împotriva daunelor de reputație unui birou de avocatură cu o expertiză avansată în IT și internet. Dacă această listare este superficială, se pot întâmpla următoarele:
- Chiar dacă ștergeți toate paginile listate, alte pagini care nu au fost afișate în rezultatele căutării globale la momentul listării pot apărea în rezultatele căutării, necesitând ștergeri suplimentare, ceea ce înseamnă că bugetul inițial a fost calculat greșit
- Procedurile judiciare, care ar fi trebuit să se finalizeze într-o singură rundă, pot necesita două sau trei runde, ceea ce duce la costuri excesive
- Nu observați existența paginilor din afara web-ului deschis, cum ar fi site-urile de baze de date ale ziarelor, și de exemplu, “problema” de a nu putea obține un loc de muncă din cauza căutării de articole de arestare nu este rezolvată
Acestea sunt problemele care pot apărea.
Category: Internet




















