Grundvoraussetzungen für Maßnahmen gegen Rufschädigung: Erklärung zur genauen Untersuchung von negativen Artikeln im Internet

Wenn es darum geht, Webseiten, die über vergangene Unternehmensskandale, Shitstorms, Verhaftungen oder Vorstrafen berichten, vollständig zu entfernen, ist es zunächst notwendig, alle diese negativen Seiten und Beiträge vollständig aufzulisten. Ohne diese Auflistung ist es nicht möglich, Maßnahmen zur Schadensbegrenzung bei Rufschädigung voranzutreiben, während man das Gesamtvolumen betrachtet. Darüber hinaus besteht die Gefahr, dass man beispielsweise gerichtliche Verfahren wie einstweilige Verfügungen oder Gerichtsverfahren, die eigentlich in einer einzigen Runde abgeschlossen werden sollten, aufgrund von Übersehenem zweimal durchführen muss.
Allerdings ist es keineswegs “einfach”, alle Webseiten und Beiträge, die über eine bestimmte Tatsache (wie zum Beispiel Unternehmensskandale, Shitstorms, Verhaftungen oder Vorstrafen) berichten, im Internet aufzulisten. Diese Aufgabe erfordert ein hohes Maß an Fachwissen und kann ohne entsprechendes Know-how nicht durchgeführt werden.
Die Monolith-Anwaltskanzlei, mit ihrem Team aus ehemaligen IT-Ingenieuren und spezialisierten Internetrecherche-Mitarbeitern, ist eine Anwaltskanzlei, die sich auf Maßnahmen zur Schadensbegrenzung bei Rufschädigung spezialisiert hat. Im Folgenden erläutern wir, wie die Internetrecherche durchgeführt werden sollte.
Was sind die Google-Suchergebnisse und ihre Grenzen?
Die Grundlage für die Online-Recherche ist zweifellos die Google-Suche. Allerdings gibt es bei den Suchergebnissen, die bei Google angezeigt werden, wenn Sie nach den gewünschten Schlüsselwörtern suchen, zum Beispiel im Falle der Löschung eines Verhaftungsartikels “Ihr eigener Name Verhaftung”, Grenzen in drei Aspekten.
Webseiten, die von Google-Suche erfasst werden
Im Internet gibt es “unzählige” Webseiten. Die Gesamtzahl der Webseiten im Internet kann theoretisch nicht gemessen werden, aber es wird gesagt, dass die Anzahl der “Websites” derzeit etwa 1,8 Milliarden beträgt.
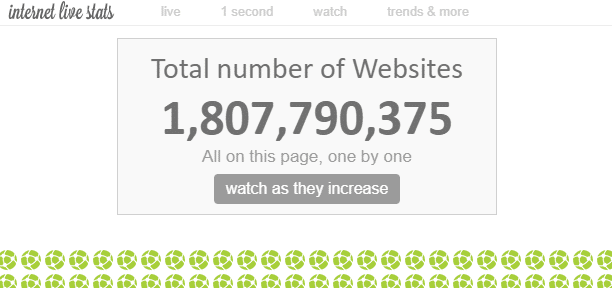
Da es innerhalb einer Website mehrere Webseiten gibt, ist die Anzahl der Webseiten weitaus größer.
Und die Google-Suche ist einfach gesagt,
- Google’s Bot (Googlebot) durchsucht das Internet, entdeckt neue Webseiten, die durch Verfolgen von Links aus bekannten Webseiten geöffnet werden können
- Versteht den Inhalt dieser Seite (Indexregistrierung)
- Zeigt diese Seite in den Suchergebnissen an, wenn eine Suche mit den auf dieser Seite enthaltenen Schlüsselwörtern durchgeführt wird
Das ist der Mechanismus. Was ich sagen möchte ist, dass das, was in der Google-Suche angezeigt wird, nur die “Webseiten sind, die Google wie oben beschrieben indexiert hat”, und nicht “alle Webseiten”. Mit anderen Worten, solange Sie die Google-Suche verwenden, können Sie “Webseiten, die Google noch nicht indexiert hat”, nicht finden, und es gibt keine Methode auf dieser Welt, um alle Webseiten im Internet vollständig und ohne Ausnahme zu durchsuchen.
“Ähnliche” Webseiten werden aus den Suchergebnissen ausgeschlossen
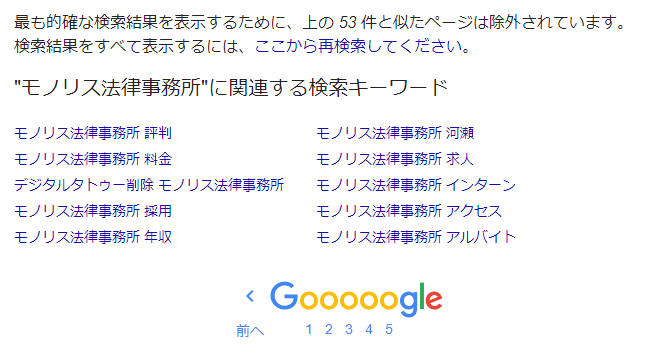
Google zeigt nicht alle Webseiten, die in seinem Index registriert und die Suchbegriffe enthalten, in den Suchergebnissen an. Dies ist etwas, das Sie vielleicht bemerkt haben, wenn Sie Google normalerweise verwenden. Auf der letzten Seite der Suchergebnisse wird angezeigt: “Um die genauesten Suchergebnisse anzuzeigen, wurden Seiten, die den oben genannten ähnlich sind, ausgeschlossen”.
Zum Beispiel,
- wenn eine Nachricht zuerst auf einer großen Nachrichtenseite veröffentlicht wird,
- dann auf Diensten, die Nachrichtenartikel zusammenfassen, weiterverbreitet wird,
- und schließlich auch auf persönlichen Websites und dergleichen weiterverbreitet wird,
Google schließt “ähnliche” Seiten, in diesem Fall 2 und 3, automatisch aus den Suchergebnissen aus, um zu verhindern, dass die Suchergebnisse mit Seiten mit demselben Inhalt überflutet werden, was für die Benutzer unpraktisch wäre.
Dies ist nicht unbedingt eine “benutzerfreundliche” Funktion, wenn Sie versuchen, alle Seiten mit schlechtem Ruf zu entfernen. Wenn zum Beispiel die oben genannte “Nachricht” ein alter Artikel über Ihre eigene Verhaftung ist,
Es könnte passieren, dass nur der “1. Originalartikel der großen Nachrichtenseite” in den Suchergebnissen angezeigt wurde, und wenn Sie diese Seite entfernen, wird nun der “2. Artikel, der auf einem Dienst, der Nachrichtenartikel zusammenfasst, weiterverbreitet wurde” in den Google-Suchergebnissen angezeigt.
Dies ist eine mögliche Situation.
Um dieses Problem zu lösen, können Sie einfach auf den Teil klicken, der besagt “Um alle Suchergebnisse anzuzeigen, suchen Sie hier erneut”. Wenn Sie diese Funktion jedoch nicht kennen, besteht die Möglichkeit, dass Sie Seiten mit schlechtem Ruf “übersehen”.
Es gibt eine Obergrenze für die Anzahl der Artikel, die innerhalb derselben Website angezeigt werden

Darüber hinaus hat Google eine Obergrenze für die Anzahl der Suchergebnisseiten festgelegt, die innerhalb einer einzigen Website angezeigt werden. Diese Spezifikation ist etwas kompliziert, aber einfach ausgedrückt bedeutet es, dass “höchstens 2 Seiten innerhalb derselben Website angezeigt werden”.
Was bedeutet das? Zum Beispiel, selbst wenn es 5 Q&As gibt, in denen der Name eines Unternehmens oder einer Person auf Yahoo! Chiebukuro (Yahoo! Answers) erscheint, werden in den Google-Suchergebnissen für den Namen dieses Unternehmens oder dieser Person höchstens 2 Seiten innerhalb von Yahoo! Chiebukuro angezeigt. Das Gleiche gilt für Foren usw. Selbst wenn es 5 Threads auf 5chan gibt, die ein bestimmtes Keyword enthalten, werden in den Google-Suchergebnissen höchstens 2 davon angezeigt. Außerdem, zum Beispiel, wenn eine Person hat,
- Artikel über die Verhaftung
- Artikel über die erneute Verhaftung
- Artikel über das schuldige Urteil
und es gibt 3 Artikel auf derselben Nachrichtenwebsite, wird mindestens einer von ihnen (3-2=1) nicht in den Google-Suchergebnissen angezeigt.
Wenn Sie ein bestimmtes Keyword suchen und viele Seiten innerhalb derselben Website (zum Beispiel Yahoo! Chiebukuro, ein bestimmtes Forum, eine bestimmte Nachrichtenwebsite usw.) in den Suchergebnissen aufgelistet werden, ist dies für den Benutzer unpraktisch, daher hat Google diese Spezifikation.
Allerdings ist diese Spezifikation nicht unbedingt “benutzerfreundlich”, wenn Sie “alle Seiten mit schlechtem Ruf löschen” möchten.
Zum Beispiel, wenn Sie in dem oben genannten Fall negative Q&As auf Yahoo! Chiebukuro durch ein Gerichtsverfahren löschen möchten und Sie sich die Google-Suchergebnisse ansehen und entscheiden, dass es “nur 2 Ziele gibt”, und das Verfahren fortsetzen, wird eine der verbleibenden 3 (5-2=3) nach dem erfolgreichen Löschen in den Suchergebnissen angezeigt.
Erweiterte Google-Suche mit “Suchausdrücken”
Von den oben genannten Problemen ist insbesondere die Lösung des dritten Problems durch die Funktion “Suchausdrücke” von Google erforderlich.
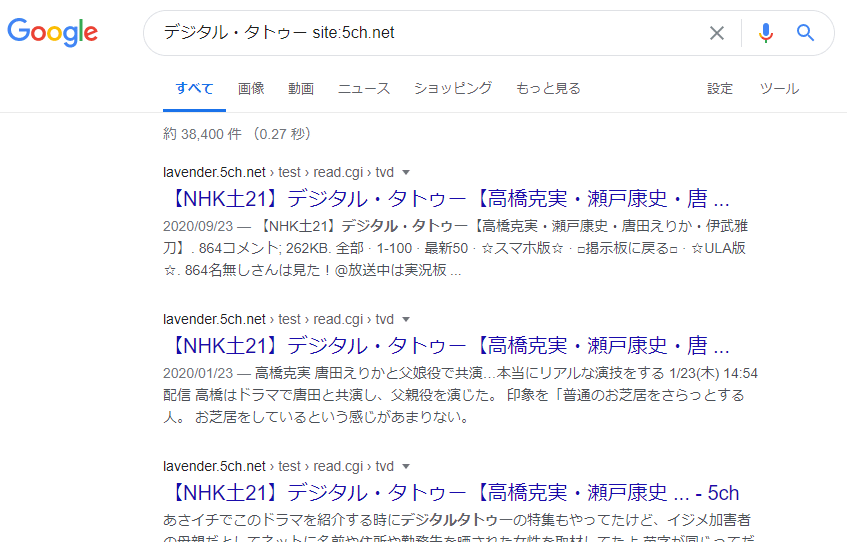
Google hat sicherlich eine Funktion (globale Suche), die “Seiten mit dem entsprechenden Schlüsselwort aus dem gesamten Internet sucht”, und setzt ein Limit von “grundlegend 2 Seiten pro Website”. Wenn Sie jedoch den “Suchausdruck” “Schlüsselwort site: Ziel-URL” verwenden, können Sie eine Suche durchführen, bei der:
- nur Artikel innerhalb der angegebenen Zielwebsite durchsucht werden
- es gibt kein Limit von “grundlegend 2 Seiten pro Website” in den Suchergebnissen
“Suchausdrücke” sind tatsächlich komplexer und es gibt auch Suchausdrücke, die zur Lösung anderer Probleme als den oben genannten verwendet werden.
Spezielle Suchmethoden für bestimmte Websites
Zum Beispiel verfügt Yahoo! Chiebukuro (Yahoo! Wissensbeutel) über eine eigene Suchfunktion.
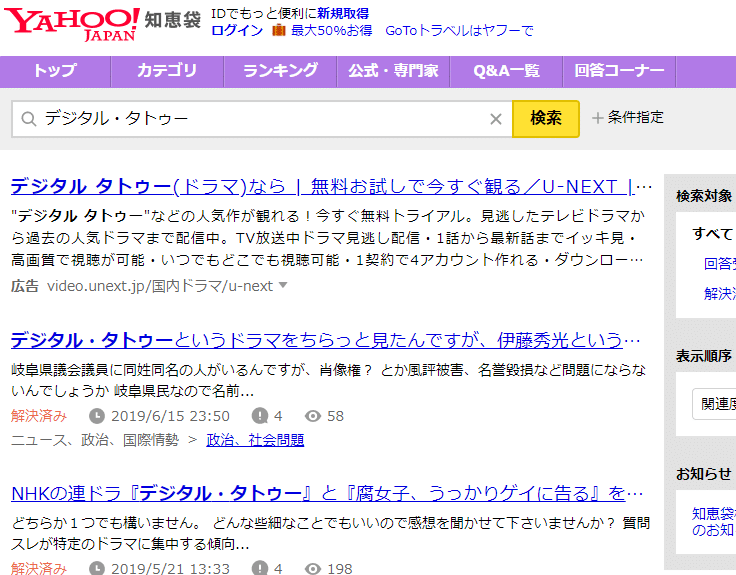
Diese Suche ist nicht auf “Webseiten, die Google (zufällig) indexiert hat”, sondern auf “Datenbanken innerhalb von Yahoo! Chiebukuro, die direkt vom Suchprogramm von Yahoo! Chiebukuro durchsucht wurden”. Dies löst das zuvor erwähnte Problem, dass es Webseiten gibt, die Google noch nicht indexiert hat. Mit anderen Worten, wenn es sich um eine Seite innerhalb von Yahoo! Chiebukuro handelt, können Sie alles finden, ohne etwas zu übersehen, solange Sie die Suchfunktion von Yahoo! Chiebukuro verwenden.
Das heißt,
Wenn es um eine bestimmte Tatsache geht (Unternehmensskandale, persönliche Verhaftungen usw.) und mindestens eine Seite von Yahoo! Chiebukuro in der globalen Suche gefunden wurde, können Sie eine vollständigere Liste erstellen, indem Sie die Suchfunktion von Yahoo! Chiebukuro verwenden, anstatt die “site:” Suchanweisung zu verwenden.
Das ist die Aussage.
Dies gilt auch für Twitter. Aufgrund der Natur des Dienstes gibt es auf Twitter oft mehrere Tweets zu einem bestimmten Thema (Unternehmensskandale, persönliche Verhaftungen usw.). Nicht alle diese Tweets sind unbedingt bei Google indexiert, und nicht alle werden in der globalen Suche angezeigt.
Zählweise für das “eine” zu löschende Element

Die Beziehung zwischen einer angemessenen Auflistung und “URL”
Bisher haben wir darüber geschrieben, “wie man so viele Webseiten (URLs) wie möglich mit Google-Suche und ähnlichen Methoden findet”. Es ist jedoch nicht immer besser, je mehr man auflistet. Denn das Ziel einer Löschungsanfrage ist nicht unbedingt auf “URLs” als Einheit ausgerichtet.
Im Falle von 5chan (japanisches Diskussionsforum)
Dies ist besonders problematisch bei Foren-Websites wie 5chan, seinen Kopie-Websites und anderen Foren-Websites.
Zum Beispiel, wenn Sie ein bestimmtes Keyword in Google mit der Suchformel “site:5ch.net” suchen, also innerhalb von 5chan, können URLs wie die folgenden in den Suchergebnissen angezeigt werden:
- ○○○.5ch.net/test/read.cgi/○○/○○○○/40
- ○○○.5ch.net/test/read.cgi/○○/○○○○/1-100
- ○○○.5ch.net/test/read.cgi/○○/○○○○/30-
5chan hat folgende Eigenschaften:
- Wenn Sie die Antwortnummer nach der Thread-URL angeben, wird nur diese Antwort angezeigt
- Wenn Sie einen Bereich von Antwortnummern wie “A-B” nach der Thread-URL angeben, werden nur die Antworten in diesem Bereich angezeigt
- Wenn Sie eine Antwortnummer und ein “-” nach der Thread-URL angeben, wie “A-“, werden alle Antworten ab dieser Nummer angezeigt
Das bedeutet, wenn das Keyword nur in der Antwort Nr. 40 geschrieben ist, werden verschiedene URLs (Webseiten) in den “Suchergebnissen” angezeigt.
Wenn Sie jedoch eine Löschungsanfrage für eine Foren-Website stellen, ist die Einheit der Anfrage in der Regel die “Antwort”. Daher, wenn Sie die Antwort Nr. 40 löschen möchten, müssen Sie nur die folgende URL extrahieren:
- ○○○.5ch.net/test/read.cgi/○○/○○○○/40
Die anderen beiden müssen nicht aufgelistet werden.
Im Falle von 5chan Kopie-Websites und Zusammenfassungs-Websites
Um es noch komplizierter zu machen, selbst innerhalb des gleichen 5chan (System), variiert die Einheit der Löschungsanfrage je nach Kopie-Website oder “Zusammenfassungs-Website” und kann eine “Seite (Thread)” anstelle einer “Antwort” sein. Welche Einheit für welche Website gilt, ist vollständig im Bereich des “Know-hows”.
https://monolith.law/reputation/delation-of-scraping-site-roundup-website[ja]
Daher ist es schwierig, “die zu löschenden Elemente beim Durchsehen der Suchergebnisse aufzulisten”, wenn Sie nicht über
- ein Verständnis der rechtlichen Einheit der Löschungsanfrage
- ein Verständnis der URL-Spezifikationen einer bestimmten Website (zum Beispiel hat 5chan die oben genannten komplexen Regeln)
verfügen.
Suche außerhalb des offenen Webs

Bis jetzt haben wir über Websites gesprochen, die Google möglicherweise indexiert, aber es gibt auch Websites, die
- Google definitiv nicht indexiert
- aber dennoch als potenzielle Ziele für Löschungsanfragen im Rahmen des Reputationsmanagements in Betracht gezogen werden sollten
Google berücksichtigt in seinen Suchergebnissen nur Websites, die für jeden ohne Anmeldung zugänglich sind (das offene Web). Es gibt jedoch auch kostenpflichtige Webdienste, die beispielsweise eine umfassende Suche und Ansicht von Archivartikeln aus Zeitungen ermöglichen und die nur nach Registrierung und Anmeldung zugänglich sind.
Im Falle der Löschung von Verhaftungsartikeln ist es notwendig, auch diese Zeitungsdatenbank-Websites gründlich zu prüfen. Dies liegt daran, dass viele Unternehmen, die die Kreditwürdigkeit von Unternehmen oder Einzelpersonen untersuchen, diese Zeitungsdatenbank-Websites nutzen.
Weitere Details zu Zeitungsdatenbank-Websites finden Sie im folgenden Artikel.
https://monolith.law/reputation/criminal-record-newspaper-database[ja]
Zusammenfassung
Wie oben dargestellt, ist das “Auflisten von Zielen für Löschungsanfragen zur Bekämpfung von Rufschädigungen im Internet” eine sehr spezialisierte Aufgabe. Unsere Kanzlei führt diese Art von Zielartikellisten bei der Übernahme von Rufschadensbekämpfungsmaßnahmen durch, aber diese Arbeit setzt Fachkenntnisse in IT und Internet voraus.
Die Löschung von Seiten (oder Forenbeiträgen) als Maßnahme gegen Rufschädigung im Internet ist eine Aufgabe, die nur von Anwälten durchgeführt werden kann.
https://monolith.law/reputation/hiben-koui[ja]
Auf der anderen Seite ist diese Auflistung, wie in diesem Artikel erläutert, eine Aufgabe, die ein hohes Maß an IT- und Internetkenntnissen erfordert. Dies ist einer der großen Gründe, warum man eine Kanzlei mit hoher Fachkompetenz in IT und Internet für Rufschadensbekämpfungsmaßnahmen beauftragen sollte. Es mag sich wiederholen, aber wenn solche Auflistungen nachlässig sind, können folgende Probleme auftreten:
- Auch wenn alle aufgelisteten Seiten beseitigt werden, können andere Seiten, die zum Zeitpunkt der Auflistung nicht in den globalen Suchergebnissen angezeigt wurden, in den Suchergebnissen angezeigt werden und zusätzliche Löschungen erforderlich machen, was bedeutet, dass die ursprüngliche Budgetberechnung stark fehlerhaft war.
- Für Gerichtsverfahren, die eigentlich nur einmal hätten durchgeführt werden müssen, werden zwei oder drei Mal benötigt, was zu übermäßigen Kosten führt.
- Man bemerkt nicht die Existenz von Seiten außerhalb des offenen Webs, wie z.B. Zeitungsdatenbankseiten, und das Problem, wie z.B. “Schwierigkeiten bei der Jobsuche aufgrund von Verhaftungsartikeln”, wird nicht gelöst.
Dies sind die Gründe für die möglichen Probleme.
Category: Internet
Related Articles

Kann der Verfasser identifiziert werden, nachdem ein Artikel über Rufschädigung gelöscht wurde?
Internet




Was sind die Schlüsselpunkte in den YouTube-Nutzungsbedingungen? Ein Anwalt erklärt, worauf man .
Internet

Stellt das Zitieren von Tweets anderer Personen auf Twitter durch Screenshots eine Urheberrechts.
Internet














