Premisas para las medidas contra el daño reputacional: Explicación de cómo examinar detenidamente los artículos negativos en Internet

En el caso de querer eliminar por completo las páginas web relacionadas con escándalos corporativos pasados, incidentes de incendio, arrestos y antecedentes penales, el primer paso es “enumerar todas las páginas y publicaciones negativas sin dejar ninguna fuera”. Si no se puede hacer esta lista, no se puede avanzar con las medidas de gestión de riesgos de reputación mientras se observa el volumen total. Además, existe el riesgo de que, por ejemplo, en procedimientos judiciales como medidas provisionales y juicios, lo que debería haberse resuelto en una sola vez, tenga que hacerse dos veces debido a una omisión.
Sin embargo, no es “fácil” en absoluto enumerar todas las páginas web y publicaciones que mencionan un hecho específico (como escándalos corporativos, incidentes de incendio, arrestos y antecedentes penales) en Internet. Esta tarea requiere un alto nivel de especialización y no se puede realizar sin el conocimiento adecuado.
El despacho de abogados Monolith, con un abogado principal que fue ingeniero de IT y personal especializado en investigación en Internet como se mencionó anteriormente, es un despacho de abogados con experiencia en la gestión de riesgos de reputación. A continuación, explicaremos cómo se debe realizar la investigación en Internet.
¿Qué son los resultados de búsqueda de Google y sus limitaciones?
La base de cualquier investigación en línea es, sin duda, la búsqueda en Google. Sin embargo, en los resultados de búsqueda que se muestran en Google cuando buscas las palabras clave que deseas, por ejemplo, en el caso de la eliminación de un artículo de arresto, si buscas palabras clave como “mi nombre + arresto”, hay limitaciones en tres aspectos.
Páginas web sujetas a la búsqueda de Google
En Internet, existen “innumerables” páginas web. Aunque es teóricamente imposible medir el número total de páginas web en Internet, se dice que el número de “sitios web” es de aproximadamente 1.8 mil millones en este momento.
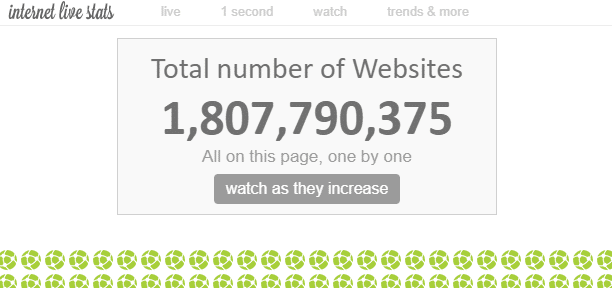
Dado que existen múltiples páginas web dentro de un solo sitio web, el número de páginas web es mucho mayor.
Y la búsqueda de Google, para decirlo de manera simple, se realiza de la siguiente manera:
- El bot de Google (Googlebot) rastrea Internet, detectando nuevas páginas web que se pueden abrir siguiendo los enlaces desde las páginas web conocidas
- Comprende el contenido de esa página (registro de índice)
- Muestra esa página en los resultados de búsqueda cuando se realiza una búsqueda con las palabras clave contenidas en esa página
Lo que quiero decir es que lo que se muestra en la búsqueda de Google son las páginas web que Google ha registrado en el índice “de la manera descrita anteriormente”, no “todas las páginas web”. En otras palabras, mientras utilices la búsqueda de Google, no podrás encontrar “páginas web que Google aún no ha registrado en el índice”, y de hecho, no existe una forma en este mundo de buscar exhaustivamente todas las páginas web en Internet sin dejar ninguna fuera.
“Páginas ‘similares’ son excluidas de los resultados de búsqueda”
Además, Google no muestra “todas las páginas web indexadas que contienen la palabra clave de búsqueda” en los resultados de búsqueda. Esto es algo que puede notar si usa Google Search de manera regular. Se refiere al mensaje que aparece en la última página de los resultados de búsqueda que dice “Para mostrar los resultados de búsqueda más precisos, se han excluido las páginas similares a las ○ anteriores”.
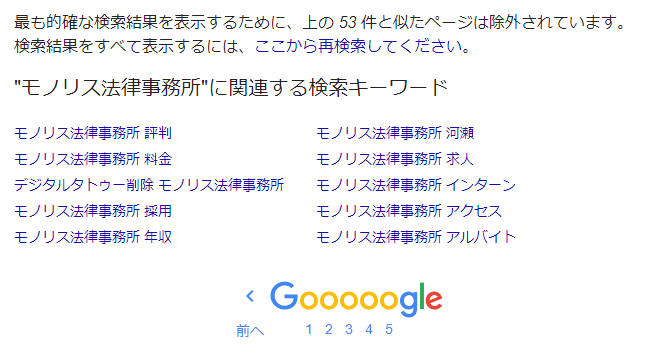
Por ejemplo,
- Una noticia es distribuida por primera vez en un sitio de noticias importante
- La noticia es republicada en servicios que recopilan artículos de noticias
- La noticia también es republicada en sitios personales, etc.
En tales casos, si las páginas con el mismo contenido llenan los resultados de búsqueda, sería difícil para los usuarios usarlo, por lo que Google excluye automáticamente las páginas “similares”, en este caso, 2 y 3, de los resultados de búsqueda.
Esto no siempre es una característica “útil” cuando se quiere “eliminar todas las páginas de difamación”. Por ejemplo, si la “noticia” mencionada anteriormente es un artículo sobre su propio arresto pasado,
Solo se mostraba el “1. Artículo de distribución original del sitio de noticias importante” en los resultados de búsqueda, por lo que eliminó solo esa página, pero una vez que se eliminó el 1, el “2. Artículo republicado en el servicio de recopilación de noticias” comenzó a aparecer en los resultados de búsqueda de Google.
Esto es algo que podría suceder.
Este problema se puede resolver haciendo clic en la parte que dice “Para mostrar todos los resultados de búsqueda, vuelva a buscar desde aquí” en la pantalla anterior, pero si no conoce esta característica o función, existe la posibilidad de que “pase por alto” las páginas de difamación.
Existe un límite en la cantidad de artículos que se pueden mostrar desde el mismo sitio

Además, Google ha establecido un límite en el número de páginas de resultados de búsqueda que se pueden mostrar desde un solo sitio web. Esta especificación es un poco complicada, pero para simplificar, “el máximo de páginas que se pueden mostrar desde el mismo sitio es de dos”.
¿Qué significa esto? Por ejemplo, supongamos que hay cinco preguntas y respuestas en Yahoo! Respuestas en las que aparece el nombre de una empresa o individuo. En los resultados de búsqueda de Google para el nombre de esa empresa o individuo, se mostrarán un máximo de dos páginas de Yahoo! Respuestas. Lo mismo ocurre con los foros, si hay cinco hilos en 5chan que contienen una cierta palabra clave, solo se mostrarán un máximo de dos en los resultados de búsqueda de Google. Además, por ejemplo, si una persona tiene:
- Un artículo sobre su arresto
- Un artículo sobre su re-arresto
- Un artículo sobre su condena
Si existen tres artículos en el mismo sitio de noticias, al menos uno de ellos (3-2=1) no se mostrará en los resultados de búsqueda de Google.
Si al buscar una palabra clave, las páginas dentro del mismo sitio (por ejemplo, Yahoo! Respuestas, un foro específico, un sitio de noticias específico, etc.) aparecen en gran cantidad en los resultados de búsqueda, esto sería inconveniente para el usuario, por lo que Google ha establecido esta especificación.
Sin embargo, esta especificación no siempre es “fácil de usar” cuando se quiere “eliminar todas las páginas de daño a la reputación”.
Por ejemplo, si se quiere eliminar una pregunta y respuesta negativa de Yahoo! Respuestas a través de un procedimiento judicial, y se miran los resultados de búsqueda de Google y se decide que “solo hay dos objetivos”, y se procede con el procedimiento, cuando se tiene éxito en la eliminación, uno de los tres restantes (5-2=3) aparecerá en los resultados de búsqueda.
Búsqueda avanzada de Google utilizando “Fórmulas de búsqueda”
Entre los problemas mencionados anteriormente, la función de “Fórmulas de búsqueda” de Google es especialmente necesaria para resolver el tercer problema.
Google ciertamente establece un límite de “2 páginas básicas por sitio” para la función de “buscar páginas que contengan la palabra clave en todo el Internet” (búsqueda global). Sin embargo, al utilizar la “Fórmula de búsqueda” de “palabra clave site:URL del sitio objetivo”, puedes:
- Realizar búsquedas solo en los artículos dentro del sitio objetivo especificado
- Los resultados de esa búsqueda no tienen el límite de “2 páginas básicas por sitio”
Esto te permite realizar dicha búsqueda.
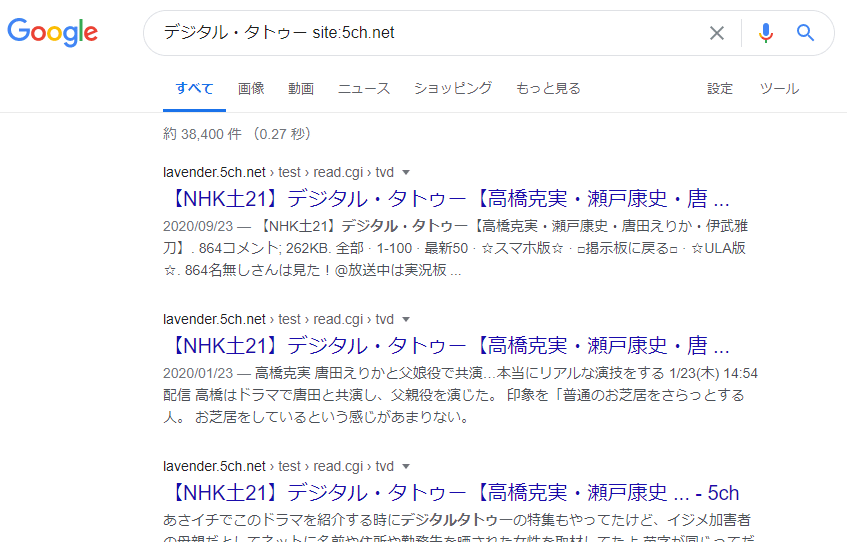
Las “Fórmulas de búsqueda” son en realidad más complejas, y existen otras fórmulas de búsqueda que se utilizan para resolver problemas además de los mencionados anteriormente.
Métodos de búsqueda especializados para sitios específicos
Por ejemplo, Yahoo! Respuestas tiene su propia función de búsqueda.
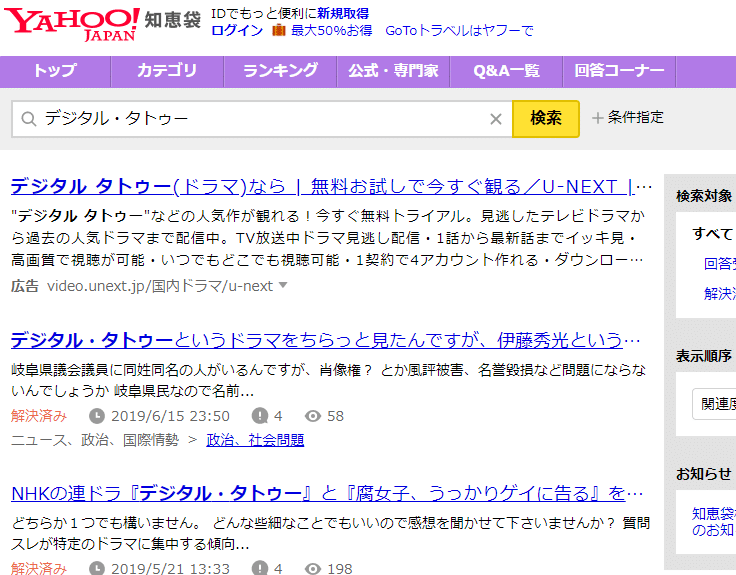
Esta búsqueda no se basa en “páginas web que Google ha indexado (por casualidad)”, sino en “los resultados de la búsqueda del programa de búsqueda de Yahoo! Respuestas en su propia base de datos”. Por lo tanto, resuelve el problema mencionado al principio, que “existen páginas web que Google aún no ha indexado”. En otras palabras, “si es una página dentro de Yahoo! Respuestas, se puede encontrar sin excepción utilizando la función de búsqueda de Yahoo! Respuestas”.
En otras palabras,
En cuanto a un hecho (escándalo de una empresa, arresto de una persona, etc.), al menos si se encuentra una página de Yahoo! Respuestas en la búsqueda global, se puede hacer una lista más completa utilizando la función de búsqueda de Yahoo! Respuestas que utilizando la fórmula de búsqueda “site:”.
Esto es lo que significa.
Lo mismo se aplica a Twitter. Debido a la naturaleza de su servicio, Twitter es un sitio donde a menudo existen múltiples tweets sobre un hecho que se ha convertido en un tema de conversación (escándalo de una empresa, arresto de una persona, etc.). No todos estos tweets están necesariamente indexados en Google, y no todos aparecen en la búsqueda global.
Método de conteo para “1” elemento a eliminar

La relación entre una lista adecuada y la “URL”
Hasta ahora, hemos estado escribiendo sobre “cómo recoger tantas páginas web (URLs) como sea posible utilizando Google Search, etc.”, pero eso no significa que sea mejor si puedes listar más. Esto se debe a que el objetivo de la solicitud de eliminación no necesariamente toma la “URL” como una unidad.
En el caso de 5chan (5ちゃんねる)
Esto es particularmente problemático en el caso de sitios de tablones de anuncios (como 5chan y sus sitios de copia, y otros sitios de tablones de anuncios).
Por ejemplo, si buscas una palabra clave en Google con la fórmula de búsqueda “site:5ch.net”, es decir, buscando dentro de 5chan, puedes encontrar casos en los que se muestran URLs como los siguientes en los resultados de búsqueda:
- ○○○.5ch.net/test/read.cgi/○○/○○○○/40
- ○○○.5ch.net/test/read.cgi/○○/○○○○/1-100
- ○○○.5ch.net/test/read.cgi/○○/○○○○/30-
5chan tiene las siguientes características:
- Si escribes el número de respuesta después de la URL del hilo, solo se muestra esa respuesta.
- Si escribes un rango de números de respuesta como “A-B” después de la URL del hilo, solo se muestran las respuestas en ese rango.
- Si escribes un número de respuesta inicial y un “-” después de la URL del hilo, se muestran todas las respuestas a partir de esa respuesta.
En otras palabras, si la palabra clave está escrita solo en la respuesta número 40, varias URLs (páginas web) se mostrarán en los “resultados de búsqueda”.
Sin embargo, cuando se solicita la eliminación de un sitio de tablón de anuncios, la unidad de la solicitud de eliminación es, al menos en principio, la “respuesta”. Por lo tanto, si quieres eliminar la respuesta número 40, simplemente necesitas extraer la siguiente URL:
- ○○○.5ch.net/test/read.cgi/○○/○○○○/40
No necesitas listar las otras dos.
En el caso de los sitios de copia y recopilación de 5chan
Además, para complicar aún más las cosas, incluso dentro de 5chan (y sitios relacionados), en el caso de sus sitios de copia y “sitios de recopilación”, la unidad de la solicitud de eliminación puede ser la “página (hilo)” en lugar de la “respuesta”, dependiendo del sitio. Determinar “qué es el objetivo de la solicitud de eliminación de qué sitio” es completamente un asunto de “know-how”.
Por lo tanto,
- Entender la unidad de la solicitud de eliminación legal
- Entender las especificaciones de URL de un sitio web (por ejemplo, 5chan tiene las reglas complejas mencionadas anteriormente)
Si no tienes estos conocimientos, puede ser difícil “listar los objetivos de eliminación mientras miras los resultados de búsqueda”.
Búsqueda más allá de la web abierta

Hasta ahora, hemos explicado sobre los sitios que Google podría indexar, pero también existen sitios que:
- Google definitivamente no indexará
- Pero deben considerarse para solicitudes de eliminación como parte de la gestión de riesgos de reputación
Google, debido a sus especificaciones, solo considera sitios web abiertos (que cualquiera puede ver sin iniciar sesión) como objetivos de búsqueda. Sin embargo, existen servicios web en este mundo, por ejemplo, que permiten buscar y ver artículos de periódicos antiguos en masa, que son de pago (por lo tanto, no se pueden ver sin registrarse o iniciar sesión).
Por ejemplo, en el caso de la eliminación de artículos de arresto, es necesario examinar cuidadosamente también los sitios de bases de datos de periódicos mencionados anteriormente. Esto se debe a que muchas empresas que investigan la solvencia de empresas y particulares utilizan estos sitios de bases de datos de periódicos.
Para obtener más detalles sobre los sitios de bases de datos de periódicos, consulte el siguiente artículo.
Resumen
Como se ha mencionado anteriormente, “elaborar una lista de objetivos para solicitar la eliminación como medida contra el daño a la reputación en Internet” es una tarea de alta especialización. Nuestro despacho realiza la elaboración de esta lista de artículos objetivo cuando se nos encarga la gestión del daño a la reputación, pero este trabajo presupone una especialización en IT e Internet.
En la gestión del daño a la reputación en Internet, la eliminación de páginas (o respuestas en foros) es una tarea que sólo puede ser realizada por un abogado.
Por otro lado, como se explica en este artículo, la elaboración de esta lista es una tarea que requiere un alto nivel de conocimiento en IT e Internet. Esto es una gran razón para encargar la gestión del daño a la reputación a un despacho de abogados con una alta especialización en IT e Internet. Si la elaboración de esta lista es insuficiente, se pueden producir problemas como:
- Aunque se eliminen todas las páginas listadas, pueden aparecer en los resultados de búsqueda otras páginas que no se mostraban en los resultados de búsqueda globales en el momento de la elaboración de la lista, lo que requeriría una eliminación adicional y haría que el presupuesto inicial estuviera muy equivocado.
- En cuanto a los procedimientos judiciales, aunque deberían haberse resuelto en una sola vez, se necesitarían dos o tres veces, lo que supondría un coste excesivo.
- No se da cuenta de la existencia de páginas fuera de la web abierta, como los sitios de bases de datos de periódicos, y por ejemplo, “el problema de que la búsqueda de artículos de arresto dificulta la obtención de un empleo” no se resuelve.
Estos son los problemas que pueden surgir.
Category: Internet
Related Articles


¿Cuál es el método de manejo cuando se encuentran escritos de insultos y difamación en Discord?
Internet

Cómo escribir una solicitud de eliminación de publicaciones en 2chan (2ch.sc) y puntos a tener e.
Internet


Explicación de los términos de uso de Instagram que los YouTubers japoneses deben tener en cuent.
Internet















