Penerangan Mengenai Kaedah Menyemak Artikel Negatif di Internet Sebagai Prasyarat untuk Langkah-langkah Mengurus Risiko Reputasi

Dalam situasi di mana anda ingin membersihkan laman web yang berkaitan dengan skandal syarikat masa lalu, insiden viral, penangkapan atau rekod jenayah, langkah pertama yang perlu diambil adalah “menyenaraikan semua laman dan posting negatif tanpa sebarang kebocoran”. Jika anda tidak dapat menyenaraikan ini, anda tidak akan dapat melaksanakan langkah-langkah pengurusan risiko reputasi sambil melihat keseluruhan volum, dan misalnya, dalam hal prosedur mahkamah seperti injunksi sementara atau perbicaraan, walaupun sepatutnya cukup sekali, anda mungkin perlu melakukannya dua kali kerana ada yang terlepas pandang.
Namun, menyenaraikan semua laman web dan posting yang mencatat fakta tertentu (seperti skandal syarikat, insiden viral, penangkapan atau rekod jenayah) dari internet bukanlah sesuatu yang “mudah”. Tugas ini memerlukan keahlian yang sangat tinggi dan tidak dapat dilakukan tanpa pengetahuan khusus.
Monolith Law Office adalah firma undang-undang yang memiliki keahlian dalam pengurusan risiko reputasi, dengan pengacara utama yang merupakan bekas jurutera IT dan staf yang khusus dalam penyelidikan internet seperti yang disebutkan di atas. Berikut adalah penjelasan tentang bagaimana penyelidikan internet harus dilakukan.
Apa itu Keputusan Carian Google dan Batasannya?
Asas kepada penyelidikan dalam talian adalah, tentu saja, carian Google. Walau bagaimanapun, dalam hasil carian Google, apabila anda mencari kata kunci yang anda inginkan, contohnya dalam kes penghapusan artikel penangkapan, dengan mencari kata kunci seperti “nama sendiri penangkapan”, terdapat batasan dalam 3 aspek.
Laman web yang menjadi sasaran carian Google
Di internet, terdapat ‘berjuta-juta’ laman web. Walaupun jumlah keseluruhan laman web di internet secara teori tidak dapat diukur, menurut satu pendapat, jumlah ‘laman web’ pada masa ini adalah kira-kira 1.8 bilion.
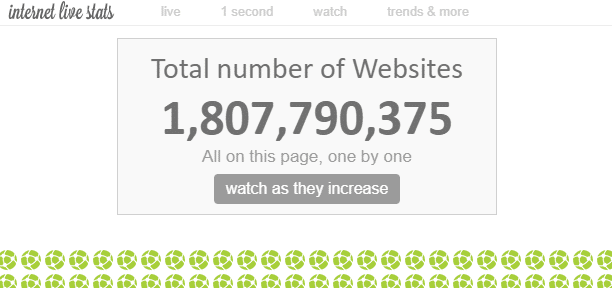
Memandangkan terdapat beberapa laman web dalam satu laman web, jumlah laman web adalah jauh lebih banyak daripada itu.
Dan carian Google, secara ringkasnya, adalah:
- Bot Google (Googlebot) merayapi internet, mengesan laman web baru yang dapat dibuka dengan mengikuti pautan dari laman web yang diketahui
- Memahami kandungan laman web tersebut (pendaftaran indeks)
- Apabila carian dilakukan dengan kata kunci yang terkandung dalam laman web tersebut, paparkan laman web tersebut dalam hasil carian
Maksudnya, apa yang dipaparkan dalam carian Google adalah ‘laman web yang Google telah mendaftarkan indeks seperti yang dinyatakan di atas’, bukan ‘semua laman web’. Dengan kata lain, selagi anda menggunakan carian Google, anda tidak dapat menemui ‘laman web yang Google belum mendaftarkan indeksnya’, dan tidak ada cara untuk mencari semua laman web di internet tanpa melewatkan satu pun.
“Halaman Web yang ‘Serupa’ Dikeluarkan dari Hasil Pencarian”
Selain itu, Google tidak menampilkan “semua halaman web yang mengandung kata kunci pencarian dan telah didaftarkan dalam indeks” dalam hasil pencarian. Ini mungkin sesuatu yang anda perasan jika anda menggunakan pencarian Google secara biasa. Ini merujuk kepada mesej yang ditampilkan pada halaman terakhir hasil pencarian yang mengatakan “Untuk menampilkan hasil pencarian yang paling tepat, halaman yang serupa dengan ○ item di atas telah dikeluarkan.”
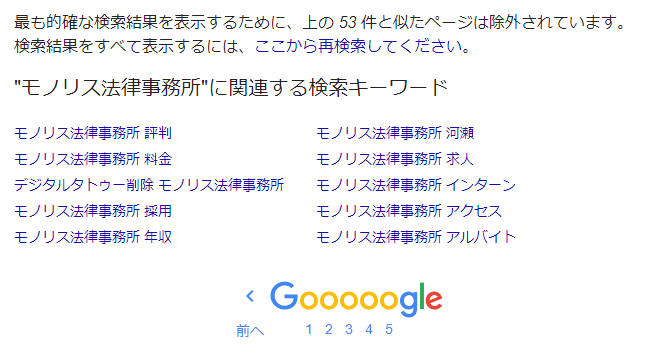
Sebagai contoh,
- Berita tertentu disiarkan pertama kali di laman berita utama
- Berita tersebut disalin ke perkhidmatan yang mengumpulkan artikel berita
- Berita tersebut juga disalin ke laman web peribadi dan sebagainya
Dalam kes seperti ini, jika halaman dengan kandungan yang sama memenuhi hasil pencarian, ia akan menjadi sukar untuk digunakan oleh pengguna, jadi Google secara automatik mengeluarkan halaman “serupa”, dalam kes ini 2 dan 3, dari hasil pencarian.
Ini bukanlah spesifikasi yang “mudah digunakan” jika anda ingin “membersihkan halaman reputasi buruk”. Sebagai contoh, jika “berita tertentu” di atas adalah artikel penangkapan anda di masa lalu,
Hanya “1. Artikel siaran pertama di laman berita utama” yang ditampilkan dalam hasil pencarian, jadi apabila anda menghapus halaman itu, “2. Artikel yang disalin ke perkhidmatan pengumpulan berita” muncul dalam hasil pencarian Google kerana 1 telah dihapuskan
Keadaan seperti ini boleh berlaku.
Masalah ini boleh diselesaikan dengan mengklik bahagian “Untuk menampilkan semua hasil pencarian, cari semula dari sini” dalam paparan di atas, tetapi jika anda tidak mengetahui spesifikasi atau fungsi ini, anda mungkin “melewatkan” halaman reputasi buruk.
Ada had maksimum untuk bilangan artikel yang dipaparkan dari laman web yang sama

Selain itu, Google telah menetapkan had maksimum untuk bilangan halaman hasil carian yang dipaparkan dari satu laman web. Spesifikasi ini agak rumit, tetapi secara ringkasnya, “maksimum 2 halaman sahaja yang dipaparkan dari laman web yang sama”.
Ini bermakna, misalnya, walaupun ada 5 soalan dan jawapan yang menyebut nama syarikat atau individu tertentu dalam Yahoo! Chiebukuro, hanya maksimum 2 halaman dari Yahoo! Chiebukuro yang akan dipaparkan dalam hasil carian Google apabila anda mencari nama syarikat atau individu tersebut. Ini juga berlaku untuk forum dan sebagainya, walaupun ada 5 thread 5chan yang mengandungi kata kunci tertentu, hanya maksimum 2 thread yang akan dipaparkan dalam hasil carian Google. Misalnya, jika seseorang mempunyai,
- Artikel penangkapan
- Artikel penangkapan semula
- Artikel penghakiman bersalah
dan 3 artikel ini wujud di laman berita yang sama, sekurang-kurangnya satu daripadanya (3-2=1) tidak akan dipaparkan dalam hasil carian Google.
Apabila anda mencari kata kunci tertentu, jika banyak halaman dari laman web yang sama (misalnya Yahoo! Chiebukuro, forum tertentu, laman berita tertentu, dll.) muncul dalam hasil carian, ini akan menjadi tidak selesa untuk pengguna, jadi Google telah membuat spesifikasi ini.
Walau bagaimanapun, spesifikasi ini juga tidak semestinya “mudah digunakan” jika anda ingin “menghapuskan semua halaman yang merosakkan reputasi”.
Misalnya, jika anda ingin menghapuskan soalan dan jawapan negatif dari Yahoo! Chiebukuro melalui prosedur mahkamah, dan anda melihat hasil carian Google dan membuat keputusan bahawa “hanya ada 2 yang perlu ditangani”, dan anda meneruskan prosedur, apabila penghapusan berjaya, salah satu daripada 3 (5-2=3) yang tersisa akan muncul dalam hasil carian.
Pencarian Google Lanjutan Menggunakan “Formula Pencarian”
Daripada masalah yang disebutkan di atas, fungsi “Formula Pencarian” Google adalah yang paling penting untuk menyelesaikan masalah ketiga.
Google memang mempunyai fungsi untuk “mencari halaman yang mengandungi kata kunci tertentu dari seluruh internet” (pencarian global), tetapi ada had maksimum “2 halaman per laman web”. Walau bagaimanapun, jika anda menggunakan “Formula Pencarian” seperti “kata kunci site:URL laman web target”, anda boleh:
- Melakukan pencarian hanya dalam artikel di laman web target yang ditentukan
- Hasil pencarian tersebut tidak terikat dengan had “2 halaman per laman web”
Anda boleh melakukan pencarian seperti ini.
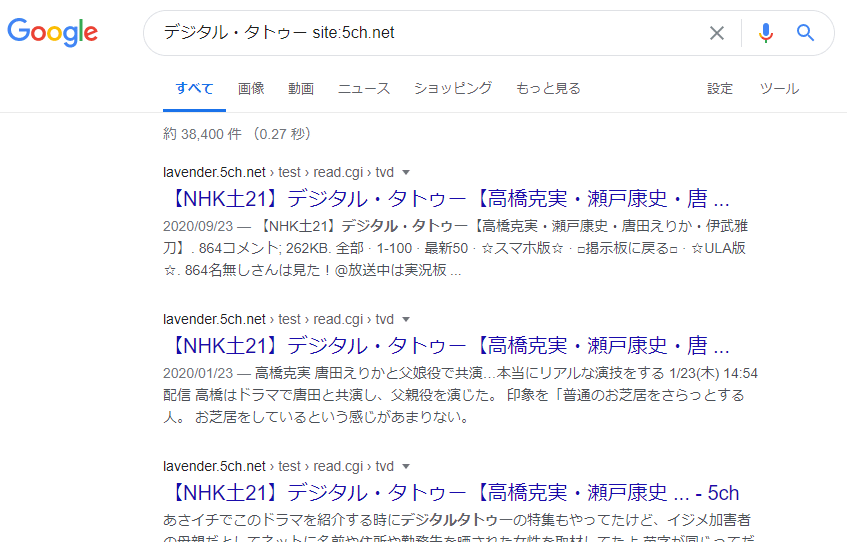
“Formula Pencarian” sebenarnya lebih kompleks, dan terdapat formula pencarian lain yang digunakan untuk menyelesaikan masalah selain yang disebutkan di atas.
Cara Pencarian Khusus untuk Laman Web Tertentu
Sebagai contoh, Yahoo! Chiebukuro (Yahoo! Answers di Jepun) mempunyai fungsi pencarian yang unik.
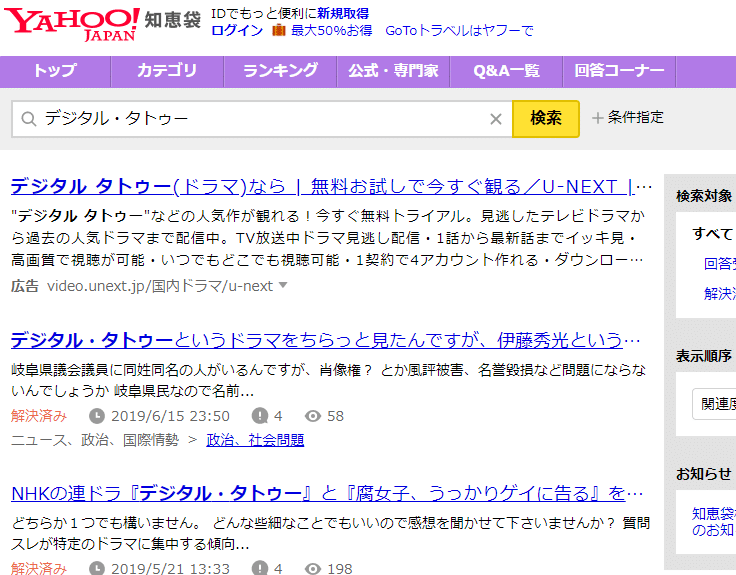
Pencarian ini bukanlah “laman web yang telah diindeks oleh Google (secara kebetulan)”, tetapi “hasil pencarian oleh program pencarian Yahoo! Chiebukuro sendiri dalam pangkalan data Yahoo! Chiebukuro”. Ini menyelesaikan masalah yang disebutkan sebelumnya, iaitu “terdapat laman web yang belum diindeks oleh Google”. Ini bermakna, “jika ia adalah halaman dalam Yahoo! Chiebukuro, anda boleh mencarinya tanpa kehilangan apa-apa dengan menggunakan fungsi pencarian Yahoo! Chiebukuro”.
Jadi,
Mengenai fakta tertentu (misalnya, skandal syarikat, penangkapan individu, dll.), sekurang-kurangnya, jika halaman Yahoo! Chiebukuro ditemui dalam pencarian global, menggunakan fungsi pencarian dalam Yahoo! Chiebukuro adalah lebih baik daripada menggunakan formula pencarian “site:” untuk mendapatkan senarai lengkap tanpa kehilangan apa-apa.
Itulah maksudnya.
Ini juga berlaku untuk Twitter dan lain-lain. Twitter, kerana sifat perkhidmatannya, adalah laman web yang sering mempunyai banyak tweet mengenai fakta yang menjadi topik perbincangan (misalnya, skandal syarikat, penangkapan individu, dll.). Bukan semua tweet ini diindeks oleh Google, dan sekurang-kurangnya, bukan semua tweet ini ditampilkan dalam pencarian global.
Cara Mengira ‘1 Item’ yang Perlu Dipadam

Hubungan Antara Penyenaraian yang Tepat dan ‘URL’
Sejauh ini, kami telah menulis tentang ‘cara mengumpulkan sebanyak mungkin laman web (URL) menggunakan Google Search dan sebagainya’, tetapi bukan berarti semakin banyak yang disenaraikan, semakin baik. Ini kerana objek permintaan penghapusan tidak semestinya menggunakan ‘URL’ sebagai unitnya.
Dalam Kes 5ch.net (Forum Jepun)
Ini adalah isu yang menjadi masalah terutama dalam kes laman web forum seperti 5ch.net, laman web salinan dan laman web forum lain.
Sebagai contoh, jika anda mencari kata kunci tertentu di Google dengan formula pencarian ‘site:5ch.net’, iaitu mencari dalam 5ch.net, URL seperti berikut mungkin dipaparkan sebagai hasil pencarian.
- ○○○.5ch.net/test/read.cgi/○○/○○○○/40
- ○○○.5ch.net/test/read.cgi/○○/○○○○/1-100
- ○○○.5ch.net/test/read.cgi/○○/○○○○/30-
5ch.net mempunyai spesifikasi seperti:
- Jika anda menulis nombor respons di belakang URL utas, hanya respons tersebut yang akan dipaparkan
- Jika anda menulis julat nombor respons seperti ‘A-B’ di belakang URL utas, hanya respons dalam julat tersebut yang akan dipaparkan
- Jika anda menulis nombor respons awal dan ‘-‘ di belakang URL utas, semua respons selepas respons tersebut akan dipaparkan
Dengan kata lain, hanya kerana kata kunci tertentu ditulis dalam respons nombor 40, pelbagai URL (laman web) akan dipaparkan sebagai ‘hasil pencarian’.
Namun, apabila membuat permintaan penghapusan kepada laman web forum, unit objek permintaan tersebut adalah, setidaknya secara prinsip, ‘respons’. Oleh itu, jika anda ingin memadam respons nombor 40, anda hanya perlu mengekstrak
- ○○○.5ch.net/test/read.cgi/○○/○○○○/40
dan anda tidak perlu menyenaraikan dua yang lain.
Dalam Kes Laman Web Salinan dan Ringkasan 5ch.net
Sebagai tambahan, walaupun ini adalah cerita yang agak rumit, walaupun di 5ch.net (dan seumpamanya), dalam kes laman web salinan dan ‘laman web ringkasan’, unit permintaan penghapusan mungkin bukan ‘respons’ tetapi ‘laman (utas)’. ‘Apa yang menjadi objek permintaan penghapusan untuk laman web mana’ adalah sepenuhnya dalam bidang ‘know-how’.
https://monolith.law/reputation/delation-of-scraping-site-roundup-website[ja]
Oleh itu,
- Pemahaman tentang unit permintaan penghapusan secara undang-undang
- Pemahaman tentang spesifikasi URL laman web tertentu (contohnya, 5ch.net mempunyai peraturan rumit seperti yang disebutkan di atas)
tanpa ini, adalah sukar untuk ‘menyenaraikan objek penghapusan semasa melihat hasil pencarian’.
Pencarian Di Luar Web Terbuka

Sehingga kini, kami telah menjelaskan tentang laman web yang mungkin diindeks oleh Google, tetapi,
- Google tidak akan mengindeks dengan pasti
- Tetapi harus dipertimbangkan sebagai subjek permintaan penghapusan dalam pengurusan reputasi
terdapat juga kumpulan laman web seperti itu.
Google, berdasarkan spesifikasi di atas, hanya menjadikan laman web yang boleh dilihat oleh sesiapa sahaja tanpa perlu log masuk (web terbuka) sebagai subjek pencarian. Namun, misalnya, di dunia ini, terdapat juga “perkhidmatan web berbayar (oleh itu, anda tidak boleh melihatnya tanpa mendaftar atau log masuk) yang membolehkan anda mencari dan melihat semua artikel lama surat khabar”.
Sebagai contoh, dalam kes penghapusan artikel penangkapan, perlu juga untuk memeriksa laman web pangkalan data surat khabar di atas. Ini kerana banyak syarikat yang menyiasat kredit syarikat atau individu menggunakan laman web pangkalan data surat khabar tersebut.
Maklumat lanjut tentang laman web pangkalan data surat khabar dapat ditemui dalam artikel di bawah.
https://monolith.law/reputation/criminal-record-newspaper-database[ja]
Rumusan
Seperti yang dinyatakan di atas, “menyenaraikan sasaran permohonan penghapusan sebagai langkah pengurusan risiko reputasi dari internet” adalah tugas yang sangat memerlukan kepakaran. Firma kami melakukan penyusunan senarai artikel sasaran seperti yang dinyatakan di atas semasa menerima tugas pengurusan risiko reputasi, tetapi tugas ini memerlukan kepakaran dalam IT dan internet.
Penghapusan laman (atau respons forum) dalam pengurusan risiko reputasi di internet adalah tugas yang hanya boleh dilakukan oleh peguam.
https://monolith.law/reputation/hiben-koui[ja]
Namun, sebaliknya, penyusunan senarai ini adalah tugas yang sangat memerlukan pengetahuan IT dan internet, seperti yang dijelaskan secara ringkas dalam artikel ini. Ini adalah salah satu alasan besar mengapa anda harus meminta bantuan firma undang-undang yang memiliki keahlian tinggi dalam IT dan internet untuk pengurusan risiko reputasi. Walaupun ini mungkin berulang, jika penyusunan senarai ini tidak dilakukan dengan betul,
- Walaupun anda membersihkan semua laman yang disenaraikan, laman lain yang tidak ditampilkan dalam hasil carian global semasa penyusunan senarai mungkin akan ditampilkan dalam hasil carian, dan penghapusan tambahan mungkin diperlukan, yang berarti anggaran awal anda sangat salah
- Mengenai prosedur mahkamah, walaupun sepatutnya cukup sekali, anda mungkin perlu melakukannya dua atau tiga kali, yang akan memerlukan kos yang berlebihan
- Anda mungkin tidak menyedari keberadaan laman di luar web terbuka, seperti laman basis data surat khabar, dan misalnya, “masalah” seperti “kesukaran mendapatkan pekerjaan kerana artikel penangkapan dicari” mungkin tidak diselesaikan
Ini adalah sebab mengapa masalah seperti ini mungkin timbul.
Category: Internet
Related Articles

Menerangkan Poin Utama Pindaan Undang-Undang Hak Cipta Jepun Tahun 2020: Sejauh Mana 'Penyertaan.
Internet
Menerangkan Contoh Kegagalan Akaun Korporat Instagram! Langkah Pencegahan dan Tindakan Balas
Internet


Adakah Permintaan Pengungkapan Maklumat Pengirim Mungkin Hanya dengan Alamat E-mel? Penjelasan u.
Internet

Peguam Menerangkan Cara Menghapus Ulasan Jahat di Laman Web Maklumat Bimbingan Belajar dan Peper.
Internet















