Kann die Erzeugung von "Stimmen" mit KI Urheberrechtsverletzungen darstellen? (#1 Entwicklungs- und Lernphase)

Die Entwicklung von generativen KI-Systemen hat es möglich gemacht, die Stimmen existierender Sänger oder Synchronsprecher einfach zu lernen und zu generieren. Auch im Geschäftsumfeld ist es nun möglich, in der App-Entwicklung, beim Spiele-Design oder bei der Erstellung von Animationen, KI-Systeme Stimmen lernen zu lassen und neue Stimmen zu erzeugen.
Das Lernen und Generieren von Stimmen existierender Sänger oder Synchronsprecher durch generative KI kann möglicherweise eine Verletzung von Urheberrechten oder andere illegale Handlungen darstellen.
Tatsächlich gibt es derzeit keine klare Auslegung zu dieser Problematik. Was sind überhaupt die rechtlichen Ansprüche an eine ‘Stimme’, und in welchen Fällen könnte dies unter dem japanischen Urheberrecht (Japan Copyright Law) problematisch werden?
In diesem Artikel werden wir die Problematik anhand konkreter Nutzungsszenarien in zwei Teilen erörtern. Im ersten Teil, dem vorliegenden Artikel, erklären wir mögliche Rechtsverletzungen in der Entwicklungs- und Lernphase der generativen KI. Rechtliche Fragen in der Phase der Generierung und Nutzung werden in diesem Artikel (Teil 2: Generierungs- und Nutzungsphase)[ja] erläutert. Wir empfehlen Ihnen, beide Teile zu lesen.
Die drei rechtlichen Rechte rund um die menschliche “Stimme” unter japanischem Recht
Welche rechtlichen Rechte besitzt die menschliche “Stimme”? Um diese Frage zu betrachten, ist es notwendig, zwei Perspektiven in Bezug auf die “Stimme” zu haben:
- Was die Stimme sagt,
- Wie die Stimme klingt.
Das heißt, der erste Punkt betrifft den “Inhalt” der Stimme, während der zweite Punkt den “Klang” der Stimme betrifft.
Wenn beispielsweise verschiedene Synchronsprecher den Satz “Guten Morgen” sagen, bleibt der Inhalt des ersten Punktes gleich, aber der Klang des zweiten Punktes unterscheidet sich.
Unter diesen Gesichtspunkten können unter dem geltenden japanischen Recht die folgenden drei rechtlichen Rechte in Bezug auf die menschliche “Stimme” entstehen:
| ① Urheberrecht | Kann in Bezug auf den “Inhalt” der Stimme entstehen |
| ② Leistungsschutzrechte (beschränkt auf die Rechte der ausübenden Künstler) | Kann in Bezug auf den “Inhalt” und “Klang” der Stimme entstehen |
| ③ Recht auf Publicity | Kann in Bezug auf den “Klang” der Stimme entstehen |
Über das Urheberrecht in Japan
Urheberrechte entstehen, wenn der “Inhalt” einer Stimme als urheberrechtlich geschütztes Werk gilt.
Beispielsweise kann beim Vorlesen eines berühmten Romans ein Urheberrecht an der Stimme entstehen. Wichtig zu beachten ist jedoch, dass in solchen Fällen der Urheberrechtsschutz dem Autor des Romans zusteht und nicht der Person, die die Stimme liefert – dem Sprecher. Das bedeutet, wenn eine generierte KI eine synthetische Stimme erstellt, die den Inhalt eines berühmten Romans vorliest, könnte diese Handlung das Urheberrecht des Autors des Romans verletzen.
Im Gegensatz dazu entstehen keine Urheberrechte an einer Stimme, wenn deren Inhalt alltägliche Gespräche einer gewöhnlichen Person umfasst. Der Grund dafür ist, dass alltägliche Gespräche grundsätzlich nicht als urheberrechtlich geschützte Werke gelten und somit nicht unter den Schutz des Urheberrechtsgesetzes fallen.
Über das Leistungsschutzrecht in Japan
Das Leistungsschutzrecht (beschränkt auf die Rechte der ausübenden Künstler) kann entstehen, wenn der Inhalt der Stimme als Werk im Sinne des Urheberrechts gilt und diese Stimme in Form einer Lesung oder ähnlichem vorgetragen wird.
Wie bereits im Abschnitt über das Urheberrecht erwähnt, kann in solchen Fällen, in denen die Stimme eine “Lesung” als “Aufführung” darstellt, ein Leistungsschutzrecht für den Lesenden entstehen. Im Gegensatz zum Urheberrecht ist es wichtig zu beachten, dass der Inhaber des Leistungsschutzrechts nicht der Autor des Romans ist, sondern derjenige, der tatsächlich die Lesung durchführt.
Über das Recht auf Publicity in Japan
Das Recht auf Publicity bezeichnet das exklusive Recht, die Anziehungskraft des Namens oder des Bildnisses einer Person für Kunden zu nutzen. Dieses Recht wurde durch die Rechtsprechung anerkannt, basierend auf einem Urteil des Obersten Gerichtshofs (H24 (2012).2.2).
| ▶︎ Oberstes Gerichtsurteil H24 (2012).2.2 (Pink Lady-Fall) ■ Urteilsinhalt ① Wenn der Name oder das Bildnis an sich als unabhängiges Objekt der Betrachtung in Produkten verwendet wird, ② der Name oder das Bildnis dem Produkt beigefügt wird, um eine Differenzierung des Produkts zu erreichen, und ③ der Name oder das Bildnis ausschließlich zum Zweck der Nutzung der Kundenanziehungskraft in der Werbung für das Produkt verwendet wird, dann stellt dies eine Verletzung des Rechts auf Publicity dar und ist als unerlaubte Handlung rechtswidrig. ■ Erläuterung des Prüfers (Oberster Gerichtshof, Urteilserläuterungen, Zivilsachen, Jahr H24 (2012), Teil 1, Seite 18) Unter “Bildnis etc.” im Sinne der drei Kategorien dieses Urteils versteht man Informationen, die zur Identifikation einer Person dienen, wie zum Beispiel Unterschriften, Namenszüge, Stimmen, Pseudonyme, Künstlernamen usw. |
Laut dem Pink Lady-Fall kann auch für eine Stimme ein Recht auf Publicity entstehen. Wenn festgestellt wird, dass die betreffende Stimme von einer Person mit Kundenanziehungskraft, wie einem existierenden Synchronsprecher, Schauspieler oder Sänger, stammt, entsteht das Recht auf Publicity unabhängig von ihrem “Inhalt”. Wenn diese Stimme in einer der drei im Pink Lady-Fall dargelegten Verletzungsformen genutzt wird, liegt eine Verletzung des Rechts auf Publicity vor.
Drei Nutzungsmuster in der Entwicklungs- und Lernphase
Wenn man sagt, dass man mit generativer KI Stimmen erzeugt, muss man den Prozess in die folgenden zwei Phasen unterteilen:
- Entwicklungs- und Lernphase
- Generierungs- und Nutzungsphase
Phase 1 wird von KI-Entwicklern durchgeführt, während Phase 2 von KI-Nutzern gehandhabt wird.
Visualisiert man diese Prozesse, ergibt sich das folgende Bild:
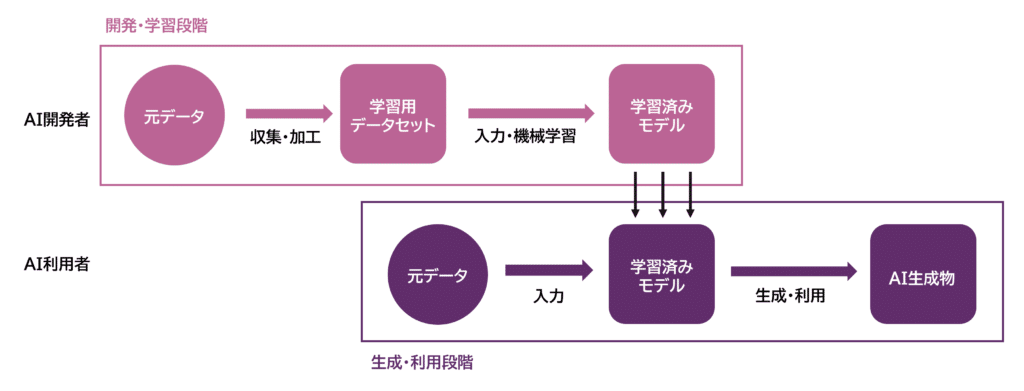
In der Entwicklungs- und Lernphase sammelt und speichert man als Trainingsdaten für die KI-Entwicklung Rohdaten menschlicher Stimmen und erstellt daraus einen Trainingsdatensatz. Anschließend werden diese Trainingsdaten in die KI eingespeist, um maschinelles Lernen durchzuführen und ein trainiertes Modell zu erstellen. In der Generierungs- und Nutzungsphase hingegen werden die Rohdaten in die fertig trainierte generative KI eingegeben, um KI-generierte Produkte zu erzeugen und zu nutzen.
Für die Entwicklungs- und Lernphase können wir die folgenden drei Nutzungsmuster annehmen:
- Muster 1: Sammeln, Speichern, Verarbeiten und Nutzen von menschlichen Stimmendaten als Trainingsdaten für die KI-Entwicklung
- Muster 2: Verkauf und Veröffentlichung von Trainingsdatensätzen, die für die KI-Entwicklung verwendet werden
- Muster 3: Verkauf und Veröffentlichung der generativen KI selbst
Im Folgenden erläutern wir kurz, welche Arten von Rechtsverletzungen in jedem dieser Nutzungsmuster potenziell auftreten können.
Muster 1: Sammlung, Speicherung, Verarbeitung und Nutzung von menschlichen Stimmendaten als Trainingsdaten für die AI-Entwicklung

Zunächst erläutern wir mögliche Rechtsverletzungen, die in der Phase der Sammlung, Speicherung, Verarbeitung und Nutzung menschlicher Stimmendaten zur Schulung von KI auftreten können.
Bezug zum Urheberrecht
Die Nutzungshandlungen von Muster 1 beziehen sich konkret auf die Entwicklung der generativen KI selbst. Die Entwicklung von KI fällt unter die “Informationsanalyse” nach Artikel 30-4, Nummer 2 des Urheberrechtsgesetzes (nachfolgend abgekürzt als Gesetz), sodass die dafür notwendige Nutzung von urheberrechtlich geschützten Werken grundsätzlich keine Urheberrechtsverletzung darstellt (Artikel 30-4).
Es gibt jedoch eine wichtige Ausnahme. Wenn das Ziel der Erstellung eines Trainingsdatensatzes darin besteht, KI-generierte Werke zu erzeugen, die die wesentlichen charakteristischen Merkmale des Originaldatums aufweisen (mit dem Ziel der Ausdrucksproduktion), dann ist Artikel 30-4 nicht anwendbar und die Handlung wird illegal.
Das bedeutet, dass die Nutzung von Stimmendaten anderer Synchronsprecher, um eine charakteristische Stimme eines bestimmten Synchronsprechers zu reproduzieren oder zu huldigen, als Ausdrucksproduktionszweck angesehen werden kann und somit die Nutzungshandlung eine mögliche Urheberrechtsverletzung darstellen könnte.
Bezug zum Leistungsschutzrecht
Auch im Zusammenhang mit dem Leistungsschutzrecht wird Artikel 102 angewendet, wodurch Artikel 30-4 des Urheberrechtsgesetzes entsprechend gilt. Daher stellt die Durchführung von Darbietungen zur Entwicklung generativer KI grundsätzlich keine Verletzung des Leistungsschutzrechts dar.
Bezug zum Recht auf Publicity
Das Recht auf Publicity wird relevant, wenn die Entwicklung von generativer KI, die darauf abzielt, die “Stimme” einer bestimmten berühmten Person zu erzeugen, in Betracht gezogen wird.
Ob eine Verletzung des Publicity-Rechts vorliegt, kann anhand der drei Kategorien von Verletzungsmustern aus dem oben genannten Pink Lady-Fall beurteilt werden.
Zunächst fällt die Entwicklungshandlung von generativer KI, die darauf abzielt, die “Stimme” einer bestimmten berühmten Person zu erzeugen, nicht unter die drei Kategorien von Verletzungsmustern aus dem Pink Lady-Fall. Wenn jedoch die Handlung ausschließlich darauf abzielt, die Kundenanziehungskraft von Namen, Porträts usw. zu nutzen, könnte sie eine Verletzung des Publicity-Rechts darstellen und eine unerlaubte Handlung bilden.
Damit die Nutzung der Kundenanziehungskraft stattfinden kann, muss während der Entwicklung der generativen KI, insbesondere bei der Erstellung des Trainingsdatensatzes, ein Dritter in der Lage sein, die Stimme als die der betreffenden berühmten Person wahrzunehmen. Wenn der Kunde als Dritter dies nicht wahrnimmt, kann keine Kundenanziehung stattfinden. Normalerweise gibt es jedoch im Entwicklungsstadium der generativen KI keinen Raum für die Beteiligung von Kunden als Dritte.
Daher kann gesagt werden, dass es kaum Raum für eine Verletzung des Publicity-Rechts durch die betreffende Nutzungshandlung gibt.
Muster 2: Verkauf und Veröffentlichung von Trainingsdatensätzen für die AI-Entwicklung
Hier erläutern wir mögliche Rechtsverletzungen, die beim Verkauf und bei der Veröffentlichung von Trainingsdatensätzen für die AI-Entwicklung auftreten können.
Beziehung zum Urheberrecht
Wenn die Originaldaten in den Trainingsdatensätzen in ihrer ursprünglichen Form oder in leicht veränderter Form gespeichert sind, kann der Verkauf und die Veröffentlichung dieser Datensätze eine Verletzung des Übertragungsrechts (Artikel 26 Absatz 2) oder des Rechts der öffentlichen Übermittlung (Artikel 23) des betreffenden Werks oder eines abgeleiteten Werks (Artikel 28) darstellen. Daher stellt dies ohne die Zustimmung des Urheberrechtsinhabers eine Urheberrechtsverletzung dar.
Dennoch bestimmt Artikel 30 Absatz 4 des japanischen Urheberrechtsgesetzes, dass im Falle der “Verwendung für Informationsanalysen” die Nutzung “in dem Maße, wie sie für notwendig erachtet wird, unabhängig von der Methode” erlaubt ist. Daher stellt die Übertragung oder Veröffentlichung zum Zweck der Entwicklung von generativen AI-Systemen keine Urheberrechtsverletzung dar, solange sie innerhalb des als notwendig erachteten Umfangs erfolgt.
Beziehung zu verwandten Schutzrechten
Wie oben erwähnt, wird Artikel 30 Absatz 4 durch Artikel 102 auf verwandte Schutzrechte angewendet, sodass der Verkauf und die Veröffentlichung von Trainingsdatensätzen für die Entwicklung von generativen AI-Systemen grundsätzlich keine Verletzung verwandter Schutzrechte darstellt.
Beziehung zum Recht auf Publicity
In den Trainingsdatensätzen sind manchmal Stimmen bestimmter Prominenter in einer direkt abspielbaren Form gespeichert. Jedoch werden Trainingsdatensätze normalerweise nur für die Entwicklung von generativen AI-Systemen verwendet und fallen nicht unter die Nutzung, wie sie im “Pink Lady”-Urteil des Obersten Gerichtshofs beschrieben wurde, bei der “der Name oder das Porträt selbst als unabhängiges Objekt der Betrachtung in Produkten oder ähnlichem verwendet wird”.
Daher kann man sagen, dass die Wahrscheinlichkeit einer Verletzung des Rechts auf Publicity in diesem Zusammenhang äußerst gering ist.
Muster 3: Verkauf und Veröffentlichung der generierenden KI selbst

In diesem Abschnitt erläutern wir mögliche Rechtsverletzungen, die beim Verkauf oder der Veröffentlichung des fertig trainierten Modells selbst auftreten können.
Beziehung zum Urheberrecht
Im Gegensatz zu Datensätzen für das Training kann bei einer generierenden KI, also einem fertig trainierten Modell, nicht davon ausgegangen werden, dass Teile des Originaldatums (Urheberwerks) mit eigener Schöpfungshöhe enthalten sind. Daher kann gesagt werden, dass die generierende KI selbst, sprich das fertig trainierte Modell, kein abgeleitetes Urheberwerk darstellt und deren Veröffentlichung oder Verkauf keine Urheberrechtsverletzung konstituiert.
Beziehung zu verwandten Schutzrechten
Wie bereits erwähnt, kann bei einem fertig trainierten Modell nicht davon ausgegangen werden, dass Teile des Originaldatums mit eigener Schöpfungshöhe enthalten sind. Daher kann gesagt werden, dass der Verkauf oder die Veröffentlichung der generierenden KI selbst keine Verletzung verwandter Schutzrechte darstellt.
Beziehung zum Recht auf Publicity
Auch wenn es sich um eine KI handelt, die die Stimme einer bestimmten berühmten Person frei und mit hoher Präzision generieren kann, ist es offensichtlich, dass dies nicht unter die drei im Pink Lady-Fall vom Obersten Gerichtshof festgestellten Verletzungsarten fällt. Allerdings ist es üblich, dass solche KIs als Wert an sich vermarktet werden, um Kunden anzuziehen, die wiederum die KI gerade deshalb kaufen, weil sie die Stimme einer bestimmten berühmten Person frei und mit hoher Präzision generieren kann. Daher ist es wahrscheinlich, dass der Verkauf einer solchen KI als eine ähnliche Handlung zu den drei Verletzungsarten als Verletzung des Rechts auf Publicity angesehen werden kann.
Zusammenfassung: Konsultieren Sie Experten bezüglich der Beziehung zwischen generativer KI und Urheberrecht
Bis hierhin haben wir die rechtlichen Rechte an der menschlichen Stimme und die Handlungen, die bei deren Nutzung problematisch werden können, anhand konkreter Beispiele erläutert.
Es ist wichtig zu verstehen, dass die rechtlichen Rechte an der menschlichen Stimme in “Inhalt” und “Ton” unterteilt werden müssen und dass Urheberrechte, verwandte Schutzrechte und das Recht auf Publicity in Betracht gezogen werden können. In diesem ersten Teil haben wir uns auf die Entwicklungs- und Lernphase konzentriert, während im zweiten Teil die Generierungs- und Nutzungsphase behandelt wird.
Verwandter Artikel: Kann die Erzeugung einer Stimme durch KI eine Urheberrechtsverletzung darstellen? (#2 Generierungs- und Nutzungsphase)[ja]
Maßnahmen unserer Kanzlei
Die Monolith Rechtsanwaltskanzlei verfügt über umfangreiche Erfahrungen in IT, insbesondere im Bereich Internetrecht und Jurisprudenz. In den letzten Jahren haben generative KI und Urheberrechte im Bereich des geistigen Eigentums zunehmend Aufmerksamkeit erregt, und die Notwendigkeit rechtlicher Überprüfungen ist stetig gestiegen. Unsere Kanzlei bietet Lösungen im Bereich des geistigen Eigentums an. Weitere Details finden Sie im folgenden Artikel.
Bereiche, die von der Monolith Rechtsanwaltskanzlei abgedeckt werden: IT- und geistiges Eigentumsrecht für verschiedene Unternehmen[ja]
Category: IT




















