Kann die Erzeugung von "Stimmen" mit KI Urheberrechtsverletzungen darstellen? (#2 Erzeugungs- und Nutzungsphase)

Durch die Entwicklung von generativer KI-Technologie ist es nun möglich, die Stimmen existierender Sänger oder Synchronsprecher einfach zu lernen und zu generieren. Auch im Geschäftsumfeld, bei der Entwicklung von Apps, Spielen oder der Erstellung von Animationen, ist es möglich geworden, generativer KI Stimmen beizubringen und neue Stimmen zu erzeugen.
Das Lernen und Generieren der Stimmen existierender Sänger oder Synchronsprecher durch generative KI kann möglicherweise eine Verletzung von Urheberrechten oder anderen rechtswidrigen Handlungen darstellen. Tatsächlich ist die Auslegung solcher Probleme unter dem aktuellen Stand noch nicht eindeutig geklärt.
Hier erläutern wir die Möglichkeit von Urheberrechtsverletzungen, verwandten Schutzrechten und Verletzungen des Rechts am eigenen Bild bei der Erzeugung und Nutzung durch generative KI. Rechtliche Probleme in der Entwicklungs- und Lernphase werden in diesem Artikel (Teil #1 Entwicklungs- und Lernphase)[ja] erörtert. Bitte ziehen Sie diesen ebenfalls zurate.
Drei Nutzungsmuster in der Erzeugungs- und Nutzungsphase
Wenn wir von “Stimmerzeugung durch generative KI” sprechen, müssen wir den Prozess in die folgenden zwei Phasen unterteilen:
- Entwicklungs- und Lernphase
- Erzeugungs- und Nutzungsphase
Phase 1 wird von KI-Entwicklern durchgeführt, während Phase 2 von KI-Nutzern gehandhabt wird.
Visualisiert sieht dieser Prozess wie folgt aus:
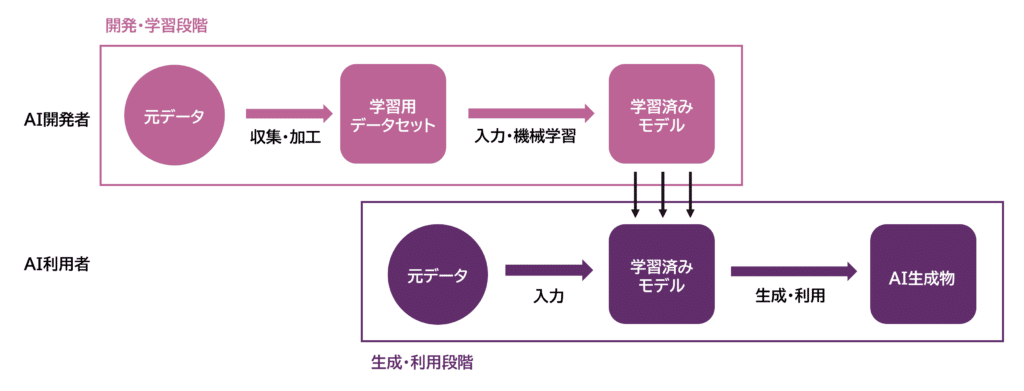
In der Entwicklungs- und Lernphase sammeln und speichern KI-Entwickler Originaldaten menschlicher Stimmen als Lernmaterial für die KI-Entwicklung und erstellen einen Lern-Datensatz. Anschließend wird dieser Lern-Datensatz in die KI eingespeist, um maschinelles Lernen durchzuführen und ein trainiertes Modell zu erstellen. Diese Schritte werden üblicherweise von KI-Entwicklern durchgeführt.
In der Erzeugungs- und Nutzungsphase geben KI-Nutzer die Originaldaten in die fertig trainierte generative KI ein, um KI-Erzeugnisse zu generieren und zu nutzen. Diese Schritte werden üblicherweise von KI-Nutzern durchgeführt.
Für die Erzeugungs- und Nutzungsphase können wir die folgenden drei Nutzungsmuster annehmen:
- Muster 1: Eingabe menschlicher Stimmen in die KI, um ein von den Originalstimmendaten verschiedenes KI-Erzeugnis zu generieren
- Muster 2: Eingabe menschlicher Stimmen in die KI, um ein mit den Originalstimmendaten identisches oder ähnliches KI-Erzeugnis zu generieren
- Muster 3: Eingabe von Nicht-Stimmendaten in die KI, um ein mit den Stimmdaten einer real existierenden Person identisches oder ähnliches KI-Erzeugnis zu generieren
Im Folgenden erläutern wir kurz, welche Arten von Rechtsverletzungen durch jedes dieser Nutzungsmuster potenziell verursacht werden könnten.
Muster 1: Eingabe menschlicher Stimmen in KI zur Erzeugung unterschiedlicher Outputs

Zunächst erläutern wir mögliche Rechtsverletzungen, die auftreten können, wenn eine menschliche Stimme in eine KI eingegeben wird, um ein davon unterschiedliches Erzeugnis zu generieren.
Bezug zum Urheberrecht
Bei Muster 1 stellen Sie sich konkret vor, dass die Gesangsstimme eines bestimmten Sängers in eine KI eingegeben wird, die entweder die Stimme identifizieren kann oder die Stimme des KI-Nutzers zusammen mit der des Sängers eingibt, um eine dem Sänger ähnliche Gesangsstimme zu erzeugen.
In Bezug auf das Urheberrecht wird die Eingabe bestehender Werke in eine KI problematisch. Diese Handlung fällt unter “Informationsanalyse” (gemäß Artikel 30-4 Absatz 2 des japanischen Urheberrechtsgesetzes), sodass Werke für solche Informationsanalysen in dem Maße genutzt werden dürfen, wie es als notwendig erachtet wird. Daher stellt die Nutzung von Werken, sofern sie für die Informationsanalyse notwendig ist und innerhalb des anerkannten Rahmens bleibt, keine Urheberrechtsverletzung dar.
Bezug zum Leistungsschutzrecht
Auch im Zusammenhang mit dem Leistungsschutzrecht wird Artikel 102 angewendet, der die Bestimmungen des Urheberrechts in Artikel 30-4 entsprechend anwendet. Daher stellt die oben beschriebene Eingabeaktion grundsätzlich keine Verletzung des Leistungsschutzrechts dar.
Bezug zum Recht auf Publicity
Im Falle von Muster 1 nehmen wir an, dass die vor der Eingabe verwendete menschliche Stimme die eines bestimmten Prominenten ist. Wenn die Stimmdaten eines bestimmten Prominenten verwendet werden, kann dies, wie im Teil 1 (Entwicklungs- und Lernphase)[ja] erläutert, eine Verletzung des Rechts auf Publicity darstellen und somit eine unerlaubte Handlung bilden.
In unserem aktuellen Beispiel würde jedoch selbst wenn die eingegebenen Stimmendaten von einem bestimmten Prominenten stammen, die Nutzung auf die Eingabe und Analyse durch die generierende KI beschränkt bleiben und somit nicht unter die drei Kategorien der Verletzungsmuster fallen.
Daher kann gesagt werden, dass es keinen Spielraum für eine Verletzung des Rechts auf Publicity gibt.
Muster 2: Eingabe menschlicher Stimmen in KI zur Erzeugung identischer oder ähnlicher Daten
Muster 2 bezieht sich auf das Eingeben von Gesangsdaten eines bestimmten Sängers sowie von Liedtexten und Melodiedaten in eine KI, um Gesangsdaten zu erzeugen, die mit der Stimme des betreffenden Sängers die entsprechenden Liedtexte und Melodien wiedergeben. Dies lässt sich grob in die folgenden drei Kategorien unterteilen:
- Die Handlung des Eingebens von Stimmendaten in die KI
- Die Erzeugung von KI-generierten Werken basierend auf diesen Daten
- Die Nutzung der entsprechenden KI-generierten Werke
Auf dieser Grundlage werden wir die Beziehung zu den folgenden Rechten analysieren.
Beziehung zum Urheberrecht
Zunächst zum Urheberrecht: Alle drei Handlungen – Eingabe, Erzeugung und Nutzung – können potenziell urheberrechtswidrig sein.
Beginnen wir mit der Eingabe. Wie bei Muster 1 ist die Eingabehandlung grundsätzlich nach Artikel 30-4 des japanischen Urheberrechtsgesetzes nicht als Urheberrechtsverletzung anzusehen.
Es gibt jedoch eine bedeutende Ausnahme zu diesem Grundsatz. Wenn das Ziel der Erzeugung von KI-generierten Werken darin besteht, die wesentlichen Ausdrucksmerkmale der Originaldaten zu reproduzieren (Ausdrucksoutput-Zweck), findet Artikel 30-4 keine Anwendung und die Handlung wird illegal. Im Falle von Muster 2 wird ein Ausdrucksoutput-Zweck meist bejaht, was bedeutet, dass die Wahrscheinlichkeit einer Urheberrechtsverletzung hoch ist.
Als Nächstes zur Erzeugung. Bei Muster 2 werden Daten erzeugt, die den existierenden urheberrechtlich geschützten Stimmendaten ähnlich oder identisch sind, was eine Verletzung des Vervielfältigungsrechts (Artikel 21) darstellt. Daher ist die Wahrscheinlichkeit einer Urheberrechtsverletzung hoch.
Zuletzt zur Nutzung. Die Nutzung von Werken, die in Schritt 2 erzeugt wurden und die existierenden urheberrechtlich geschützten Werken ähnlich oder identisch sind, stellt eine Verletzung des Vervielfältigungsrechts (Artikel 21) oder des Rechts der öffentlichen Übertragung (Artikel 23) dar. Daher ist die Wahrscheinlichkeit einer Urheberrechtsverletzung hoch.
Beziehung zu verwandten Schutzrechten
Im Hinblick auf verwandte Schutzrechte gibt es in der Praxis noch unbestimmte und komplexe Fragestellungen, die einer Prüfung bedürfen.
Derzeit wird, wie oben erwähnt, Artikel 102 angewendet, der Artikel 30-4 des Urheberrechtsgesetzes entsprechend anwendet, sodass die Wahrscheinlichkeit einer Verletzung verwandter Schutzrechte grundsätzlich gering sein dürfte.
Beziehung zum Recht auf Publicity
Bei den Handlungen von 1 bis 3 ist es so, dass bei der Eingabe und Erzeugung, also bei 1 und 2, kaum Raum für eine Verletzung des Publicity-Rechts besteht, da sie nicht unter die drei Kategorien von Verletzungsmustern fallen.
Bei der Nutzung jedoch, also bei 3, wenn diese Nutzung kommerziell, wie zum Beispiel für den Verkauf, erfolgt, fällt sie unter die drei Kategorien von Verletzungsmustern, was die Wahrscheinlichkeit einer Verletzung des Publicity-Rechts erhöht.
Muster 3: Eingabe von Nicht-Stimmendaten in KI zur Erzeugung von identischen oder ähnlichen Stimmendaten realer Personen

Beziehung zum Urheberrecht
Muster 3 bezieht sich beispielsweise auf das Eingeben eines bestimmten Synchronsprechernamens, um Sprachdaten dieses Synchronsprechers zu generieren. Hierbei stellt sich die Frage, ob das von der KI erzeugte Produkt eine Abhängigkeit von einem bestehenden urheberrechtlich geschützten Werk aufweist.
Zusammenfassend lässt sich sagen, dass, wenn ein KI-Nutzer unter der Absicht, ein identisches oder ähnliches KI-Erzeugnis zu einem bestehenden Werk zu schaffen, die KI verwendet und sich dieses Werkes bewusst ist, eine Abhängigkeit angenommen wird. Dies ist die vorherrschende Meinung.
Ein Beispiel hierfür wäre, wenn ein KI-Nutzer mit dem Ziel, die Stimme eines bestimmten Synchronsprechers zu imitieren, ein KI-Erzeugnis erstellt. In solchen Fällen ist die Wahrscheinlichkeit einer Urheberrechtsverletzung hoch.
Beziehung zum verwandten Schutzrecht
Auch wenn eine KI dazu verwendet wird, eine Darbietung zu erzeugen, die identisch oder ähnlich zu einer bestehenden Darbietung ist, wird diese Handlung nicht als “Aufnahme” der bestehenden Darbietung angesehen und stellt daher keine Verletzung verwandter Schutzrechte dar.
Beziehung zum Recht auf Publicity
Im Zusammenhang mit dem Recht auf Publicity entstehen Probleme, wenn die generierte Stimme kommerziell genutzt wird. In der Praxis sind viele detaillierte Unterscheidungen möglich, aber es genügt, sich auf das Wesentliche zu konzentrieren.
Zusammenfassend gilt, dass, wenn ein KI-Nutzer mit der Absicht, eine identische oder ähnliche Stimme einer bestimmten bekannten Persönlichkeit zu erzeugen, diese realisiert und nutzt, dies eine Verletzung des Rechts auf Publicity darstellt. Für Fälle, in denen dies unbeabsichtigt geschieht, ist die Situation komplex und es gibt in der Praxis noch viel Diskussionsbedarf, weshalb dieser Artikel darauf nicht weiter eingeht.
Zusammenfassung: Konsultieren Sie Experten bezüglich der Beziehung zwischen generativer KI und Urheberrecht
Bis hierhin haben wir die rechtlichen Ansprüche, die mit der menschlichen Stimme verbunden sind, und die problematischen Handlungen, die bei deren Nutzung auftreten können, anhand konkreter Beispiele erläutert.
Bei den rechtlichen Ansprüchen der menschlichen Stimme ist es wichtig, zwischen ‘Inhalt’ und ‘Ton’ zu unterscheiden und das Urheberrecht, verwandte Schutzrechte und das Recht auf Publicity in Betracht zu ziehen.
Bei den problematischen Handlungen müssen wir genau hinsehen, was jeweils das Problem darstellt. Die Erzeugung von Stimmen durch generative KI ist sowohl in der Praxis als auch im Geschäftsleben ein viel diskutiertes Thema. Wenn Sie ein neues Geschäft starten, sollten Sie die oben genannten Punkte beachten und darauf achten, generative KI korrekt zu nutzen.
Verwandter Artikel: Wird die Erzeugung von ‘Stimmen’ durch KI zum Urheberrechtsverstoß? (#1 Entwicklungs- und Lernphase)[ja]
Vorstellung der Maßnahmen unserer Kanzlei
Die Monolith Rechtsanwaltskanzlei vereint umfangreiche Erfahrungen in IT, insbesondere im Bereich Internet, mit juristischer Expertise. In den letzten Jahren haben generative KI-Systeme und Urheberrechte im Bereich des geistigen Eigentums zunehmend Aufmerksamkeit erlangt, wodurch die Notwendigkeit für rechtliche Überprüfungen stetig steigt. Unsere Kanzlei bietet Lösungen im Bereich des geistigen Eigentums an. Weitere Details finden Sie im folgenden Artikel.
Die Fachgebiete der Monolith Rechtsanwaltskanzlei: IT- und geistiges Eigentumsrecht für Unternehmen[ja]
Category: IT




















