AIで「声」を生成すると著作権侵害になる?(#1 開発・学習段階編)

生成AIの発展により、実在する歌手や声優の「声」を簡単に学習・生成することが可能になっています。ビジネスシーンでも、アプリ開発、ゲームクリエイトやアニメ作成の場面で、AIに「声」を学習させ、新たな「声」を生成することが可能になりました。
実在する歌手や声優の「声」を生成AIに学習させ、新たな「声」を生成することは、著作権侵害等の違法行為になる可能性があります。
実際のところ、こうした問題について、現状、明確な解釈は出ていません。そもそも、「声」の有する法的権利はどのようなもので、どのような場合に著作権法上、問題となるのでしょうか。
ここでは、具体的な利用パターンを想定しながら、この問題を前後編にわたって解説していきます。前編にあたる本稿では、生成AIの開発・学習段階で起こりうる権利侵害について解説します。生成・利用段階での法的問題点はこちらの記事(#2 生成・利用段階編)で解説しております。ぜひ併せてご参照ください。
この記事の目次
人の「声」を取り巻く3つの法的権利
人の「声」はどのような法的権利を有しているのでしょうか。この問題を考える上で「声」に対して2つの視点を持つ必要があります。
- その声が何を喋っているか、
- その声がどのような音声で喋っているか
つまり、1つ目は、声の「内容」の問題、2つ目は、声の「音」の問題と切り分けることができます。
例えば、同じ「おはようございます」というセリフを違う声優が演じている場合、1つ目の内容は同じですが、2つ目の音が異なるということになります。
これらの視点のもと、現行法上、人の「声」に発生しうる法的権利は以下の3つがあると考えられます。
| ①著作権 | 声の「内容」について生じ得る |
| ②著作隣接権(実演家の権利に限る) | 声の「内容」「音」について生じ得る |
| ③パブリシティ権 | 声の「音」について生じ得る |
著作権について
著作権は、その声の「内容」が著作物に該当する場合に発生します。
例えば、有名小説を朗読する場合、その声には、著作権が発生する可能性があります。ただ、注意しなければならないのは、このような場合の著作権者は、当該小説の執筆者であり、「声の主=発声者」ではないことです。すなわち、生成AIで有名な小説の内容を朗読する合成音声を作成した場合、当該行為は、小説の執筆者の著作権を侵害する可能性があります。
これに対し、その声の内容が一般人のありふれた日常会話などを内容とする場合、その声には著作権は発生しません。これは、ありふれた日常会話がそもそも著作物にあたらず、著作権法の保護対象ではないためです。
著作隣接権について
著作隣接権(実演家の権利に限る)は、その声の内容が著作物に該当するような場合であって、その声が朗読などの形態を伴っている場合に発生し得ます。
上記著作権の項でも触れたような場合、その声は「朗読」という「実演」を行っていることになるため、朗読者に著作隣接権が生じる可能性があります。上記著作権の場合とは異なり、著作隣接権者はあくまで小説の執筆者ではなく、実際に発声している朗読者であることに注意をする必要があります。
パブリシティ権について
パブリシティ権とは「人の氏名、肖像等が有する顧客誘引力を排他的に利用する権利」として、判例法理(最判H24.2.2)によって認められた権利です。
| ▶︎最判H24.2.2(ピンクレディー事件) ■判示内容 ①氏名、肖像等それ自体を独立して鑑賞の対象となる商品等として使用し、 ②商品等の差別化を図る目的で氏名、肖像等を商品等に付し、 ③氏名、肖像等を商品等の広告として使用するなど、専ら氏名、肖像等の有する顧客吸引力の利用を目的とする場合には、パブリシティ権侵害として不法行為上違法となる ■調査官解説(最高裁判所判例解説・民事篇平成24年度(上)18頁)本判決の3類型にいう「肖像等」とは、本人の人物識別情報をいうものであり、例えば、サイン、署名、声、ペンネーム、芸名等を含むものである |
ピンクレディー事件によれば、声にもパブリシティ権が発生する余地があります。そして、当該声が、実在の声優や俳優、歌手などのような顧客吸引力がある人物のものであるものと認定できれば、その「内容」に関わらず、パブリシティ権が発生します。そして、ピンクレディー事件の判示した3つの侵害態様のいずれかの態様で当該声を利用すれば、パブリシティ権侵害に該当します。
開発・学習段階での3つの利用パターン
単に「生成AIで声を生成する」と言っても、その工程は以下の2つに分けて考える必要があります。
- 開発・学習段階
- 生成・利用段階
そして、1はAI開発者によって、2はAI利用者によって行われる工程になります。
これらの工程を図式化すると以下の通りです。
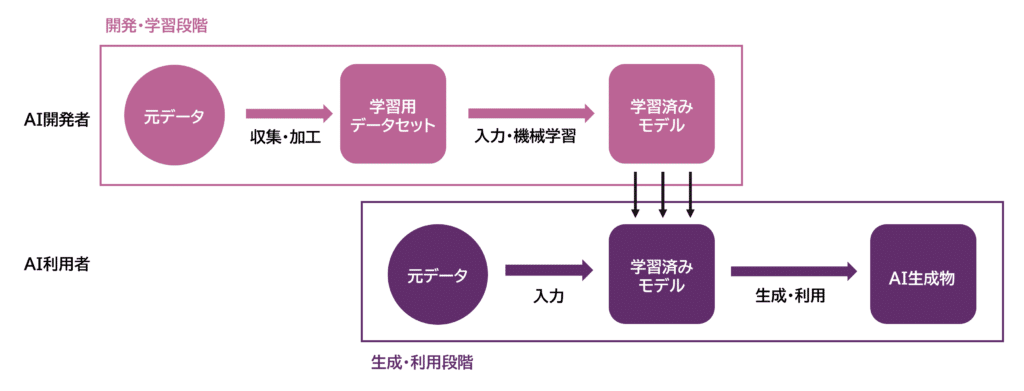
開発・学習段階では、AI開発の学習用データとして、人の声の元データを収集・蓄積し、学習用データセットを作成します。その後、学習用データセットをAIに入力し、機械学習を行い、学習済みのモデルを作成します。一方、生成・利用段階では、元データを機械学習を終えた生成AIに入力し、AI生成物を生成・利用します。
開発・学習段階の利用パターンとしては以下の3パターンを想定することができます。
- パターン1:AI開発のための学習用データとして人の声データを収集・蓄積・加工・利用する行為
- パターン2:AI開発に用いられる学習用データセットの販売・公開行為
- パターン3:生成AIそのものの販売・公開行為
以下、それぞれの利用パターンにおいて、どのような権利侵害を引き起こす可能性があるかについて簡単に解説していきます。
パターン1:AI開発のための学習用データとして人の声データを収集・蓄積・加工・利用する

まず、AIを学習させるための人の声をデータを収集・蓄積・加工し、学習に利用する段階において起こりうる権利侵害について解説します。
著作権との関係
パターン1の利用行為は、具体的に言うと、生成AIそのものを開発する行為がこれに当たります。そして、AIの開発は著作権法(法名以下略)第30条の4第2号の「情報解析」に当たるため、それに必要な著作物の利用行為は原則著作権侵害とはなりません(第30条の4)。
もっとも上記には重大な例外があります。それは、学習用データセットを作成する上で、元データが有する表現上の本質的特徴を有するAI生成物を生成する目的(表現出力目的)がある場合には、30条の4は適法されず、違法となることです。
すなわち、ある特定の声優が有している特徴的な声を再現、またはオマージュするような場合に、他の声優の声データを利用した場合、表現出力目的があるとして、当該利用行為は著作権侵害に該当する可能性があります。
著作隣接権との関係
著作隣接権との関係でも、第102条により著作権についての規定である第30条の4が準用されていますので、生成AIを開発するために実演等を行っても原則として、著作隣接権侵害には当たりません。
パブリシティ権との関係
パブリシティ権との関係が問題となる場面は、顧客吸引力のある特定の著名人の「声」の生成を目的とした生成AIの開発が想定されます。
パブリシティ権侵害を構成するか否かについては、上掲ピンクレディ事件の侵害態様3類型が参考になります。
まず、特定の著名人の「声」の生成を目的とした生成AIの開発行為それ自体は、上掲ピンクレディ事件の侵害態様3類型には該当しません。もっとも、当該行為が「専ら氏名、肖像等の有する顧客吸引力の利用を目的とする場合」に該当すれば、パブリシティ権侵害として不法行為を構成し得ます。
顧客吸引力の利用が生じ得るためには、生成AIの開発段階、とりわけ学習用データセットを作成する際に、第三者が当該著名人の声であることを知覚する必要があります。顧客たる第三者が知覚しなければ、そもそも顧客誘引は生じ得ないためです。しかし、通常生成AIの開発段階において顧客たる第三者が介在する余地はありません。
したがって、当該利用行為はパブリシティ権侵害となる余地はほとんどないと言えます。
パターン2:AI開発に用いられる学習用データセットの販売・公開
ここでは、AI学習用データセットの販売・公開の段階において起こりうる権利侵害について解説します。
著作権との関係
学習用データセットの中に、元データがそのままの形式、あるいは多少加工された形で保存されている場合、学習用データセットの販売・公開行為は、当該著作物、あるいは二次的著作物(第28条)の譲渡権侵害(第26条の2)、公衆送信権侵害(第23条)を構成します。そのため、著作権者の同意なく行うと著作権侵害となります。
もっとも、上記同様第30条の4は、「情報解析の用に供する場合」には「その必要と認められる限度において、いずれの方法によるかを問わず、利用することができる」と定めています。そのため、生成AIを開発するために譲渡や公開を行う場合には、必要と認められる限度である限り、著作権侵害とはなりません。
著作隣接権との関係
上記同様、第102条により著作権についての規定である第30条の4が準用されていますので、生成AIを開発するための学習用データセットの公開・販売を行っても原則著作隣接権侵害となりません。
パブリシティ権との関係
学習用データセットの中には、特定の著名人の声がそのまま再生できる形式で保存されています。しかし、学習用データセットは通常生成AIの開発のために用いられるに過ぎず、ピンクレディ事件の最判が判示した「氏名、肖像等それ自体を独立して鑑賞の対象となる商品等として使用」する場合とは言えません。
したがって、当該利用行為はパブリシティ権侵害となる余地はほとんどないと言えます。
パターン3:生成AIそのものの販売・公開

ここでは、学習済みモデルそのものの販売・公開の段階において起こりうる権利侵害について解説します。
著作権との関係
生成AIそのものには学習用データセットとは異なり、学習済みモデルの中に元データ(著作物)の創作性を有する部分が残っていることは観念し得ません。そのため、生成AIそれ自体、すなわち学習済みモデルは、元データの二次的著作物とはいえずこれらの公開・販売は著作権侵害を構成しないと言えます。
著作隣接権との関係
上記同様、学習済みモデルの中に元データの創作性を有する部分が残っていることは観念し得ないため、生成AIそのものの販売・公開を行っても著作隣接権を侵害しないと言えます。
パブリシティ権との関係
特定の著名人の声を自由かつ高精度に生成できるAIであっても、ピンクレディー事件の最判が判示した侵害態様3類型に該当しないことは明らかです。もっともこのようなAIは、特定の著名人の声を自由かつ高精度に生成できるAIであることをバリューとして顧客を吸引するのが通常であり、また顧客も当該AIが特定の著名人の声を自由かつ高精度に生成できることを理由に当該AIを購入するのが通常です。そのため、このようなAIの販売は、侵害態様3類型の類似行為としてパブリシティ権侵害となる可能性が高いと言えます。
まとめ:生成AIと著作権の関係については専門家に相談を
ここまで、人の声の有する法的権利、そしてそれらを利用する場合に問題となる行為について具体的事例を踏まえて解説してきました。
人の声の法的権利については、「内容」と「音」に分けて考える必要があること、著作権、著作隣接権、パブリシティ権を観念し得ることが重要です。ここでは前編として開発・学習段階に絞って解説をしてきましたが、後編では生成・利用段階について解説していきます。
関連記事:AIで「声」を生成すると著作権侵害になる?(#2 生成・利用段階編)
当事務所による対策のご案内
モノリス法律事務所は、IT、特にインターネットと法律の両面に豊富な経験を有する法律事務所です。近年、生成AIや著作権をめぐる知的財産権は注目を集めており、リーガルチェックの必要性はますます増加しています。当事務所では知的財産に関するソリューション提供を行っております。下記記事にて詳細を記載しております。
モノリス法律事務所の取扱分野:各種企業のIT・知財法務



































