Uitleg over de methode voor het nauwkeurig onderzoeken van negatieve artikelen op het internet als voorwaarde voor reputatieschadebeheer

Als u webpagina’s wilt opruimen die betrekking hebben op eerdere bedrijfsschandalen, brandgebeurtenissen, arrestaties of strafbladen, is de eerste stap om ervoor te zorgen dat u een volledige lijst maakt van alle negatieve pagina’s en berichten. Zonder deze lijst kunt u geen reputatieschadebeheer uitvoeren terwijl u het totale volume bekijkt, en er is ook een risico dat u bijvoorbeeld gerechtelijke procedures zoals voorlopige maatregelen en rechtszaken moet herhalen, die in principe in één keer hadden kunnen worden afgehandeld, omdat u iets over het hoofd heeft gezien.
Echter, het is absoluut niet ‘gemakkelijk’ om alle webpagina’s en berichten die een bepaald feit (zoals bedrijfsschandalen, brandgebeurtenissen, arrestaties of strafbladen) vermelden, op te sommen op het internet. Dit is een zeer gespecialiseerde taak die niet kan worden uitgevoerd zonder de nodige kennis en ervaring.
Monolith Law Office is een advocatenkantoor gespecialiseerd in reputatieschadebeheer, met een team dat bestaat uit een voormalige IT-ingenieur als hoofdadvocaat en medewerkers die gespecialiseerd zijn in internetonderzoek, zoals hierboven beschreven. Hieronder leggen we uit hoe internetonderzoek moet worden uitgevoerd.
Wat zijn de Google-zoekresultaten en hun beperkingen?
De basis van internetonderzoek is toch wel Google-zoeken. Echter, er zijn beperkingen aan de zoekresultaten die worden weergegeven wanneer je zoekt naar de trefwoorden die je wilt vinden op Google, bijvoorbeeld in het geval van het verwijderen van arrestatieartikelen, zoals ‘mijn naam arrestatie’. Deze beperkingen bestaan op drie manieren.
Webpagina’s die onderwerp zijn van Google-zoekopdrachten
Op het internet bestaan er ‘ontelbare’ webpagina’s. Hoewel het theoretisch onmogelijk is om het totale aantal webpagina’s op het internet te meten, wordt er geschat dat er momenteel ongeveer 1,8 miljard ‘websites’ zijn.
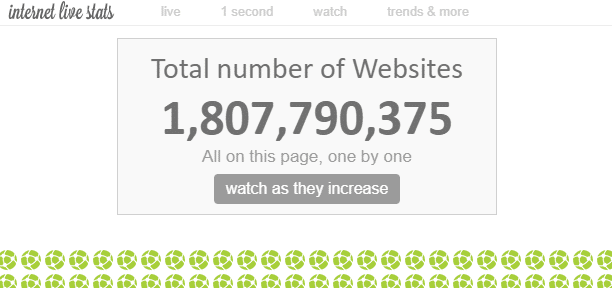
Aangezien er meerdere webpagina’s binnen één website bestaan, is het aantal webpagina’s veel groter dan dat.
En Google zoeken is, eenvoudig gezegd,
- Google’s bot (Googlebot) scant het internet, detecteert nieuwe webpagina’s die kunnen worden geopend door links te volgen vanuit bekende webpagina’s
- Begrijpt de inhoud van die pagina (indexregistratie)
- Toont die pagina in de zoekresultaten wanneer er naar de op die pagina opgenomen trefwoorden wordt gezocht
Dit is hoe het werkt. Wat ik wil zeggen is dat wat wordt weergegeven in Google-zoeken, strikt genomen, ‘webpagina’s waarvoor Google indexregistratie heeft uitgevoerd zoals hierboven’, en niet ‘alle webpagina’s’. Met andere woorden, zolang je Google-zoeken gebruikt, kun je ‘webpagina’s die Google nog niet heeft geïndexeerd’ niet vinden, en er is geen manier om alle webpagina’s op het internet zonder uitzondering te doorzoeken.
‘Vergelijkbare’ webpagina’s worden uitgesloten van de zoekresultaten
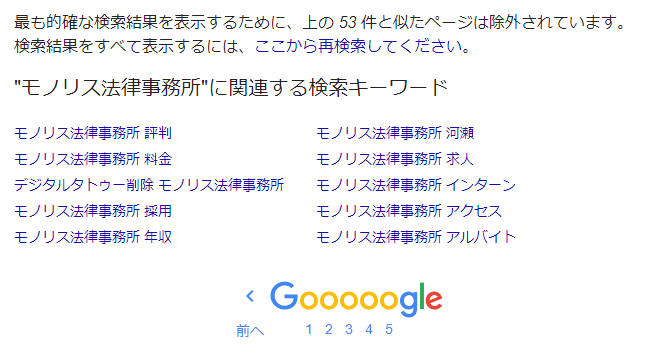
Google toont niet alle webpagina’s die in de index zijn geregistreerd en de zoekwoorden bevatten in de zoekresultaten. Dit is iets wat u misschien al heeft opgemerkt als u Google Search regelmatig gebruikt. Op de laatste pagina van de zoekresultaten staat: “Om de meest relevante resultaten te tonen, zijn pagina’s die vergelijkbaar zijn met de bovenstaande uitgesloten.”
Bijvoorbeeld,
- Een nieuwsbericht wordt voor het eerst gepubliceerd op een grote nieuwssite
- Het nieuwsartikel wordt overgenomen door diensten die nieuwsartikelen verzamelen
- Het wordt ook overgenomen op persoonlijke sites, enz.
In dergelijke gevallen, als pagina’s met dezelfde inhoud de zoekresultaten vullen, wordt het moeilijk voor de gebruiker om te gebruiken. Daarom sluit Google ‘vergelijkbare’ pagina’s, zoals 2 en 3 in het bovenstaande geval, automatisch uit van de zoekresultaten.
Dit is niet noodzakelijkerwijs een ‘gebruiksvriendelijke’ specificatie als u ‘pagina’s met reputatieschade wilt verwijderen’. Stel bijvoorbeeld dat het bovengenoemde ‘nieuws’ uw vorige arrestatieartikel is,
Alleen het ‘1. Artikel van de eerste uitzending op de grote nieuwssite’ werd weergegeven in de zoekresultaten, dus toen die pagina werd verwijderd, begon het ‘2. Artikel overgenomen op de nieuwsartikelverzamelservice’ te verschijnen in de Google-zoekresultaten omdat 1 was verwijderd.
Dit is een mogelijke situatie.
Dit probleem kan worden opgelost door op het gedeelte ‘Klik hier om alle zoekresultaten opnieuw te zoeken’ in de bovenstaande weergave te klikken, maar als u deze specificatie of functie niet kent, kunt u mogelijk ‘reputatieschadepagina’s’ over het hoofd zien.
Er is een limiet aan het aantal artikelen dat vanuit dezelfde site wordt weergegeven

Bovendien stelt Google een limiet aan het aantal zoekresultatenpagina’s dat wordt weergegeven vanuit één website. Deze specificatie is een beetje ingewikkeld, maar simpel gezegd, “het maximum aantal pagina’s dat wordt weergegeven vanuit dezelfde site is twee”.
Wat betekent dit? Bijvoorbeeld, zelfs als er vijf Q&A’s zijn waarin de naam van een bedrijf of persoon verschijnt op Yahoo! Chiebukuro (Yahoo! Answers), worden er maximaal twee pagina’s van Yahoo! Chiebukuro weergegeven in de zoekresultaten wanneer je de naam van dat bedrijf of persoon zoekt op Google. Dit geldt ook voor forums, zelfs als er vijf threads zijn op 5channel (een Japans forum) die een bepaald trefwoord bevatten, worden er maximaal twee weergegeven in de Google-zoekresultaten.
- Artikel over arrestatie
- Artikel over herarrestatie
- Artikel over veroordeling
Als er drie artikelen op dezelfde nieuwssite staan, wordt ten minste één van hen (3-2=1) niet weergegeven in de Google-zoekresultaten.
Als er veel pagina’s van dezelfde site (bijvoorbeeld Yahoo! Chiebukuro, een specifiek forum, een specifieke nieuwssite, enz.) in de zoekresultaten staan wanneer je een bepaald trefwoord zoekt, is dit onhandig voor de gebruiker, dus Google heeft deze specificatie.
Echter, deze specificatie is niet noodzakelijkerwijs “gemakkelijk te gebruiken” als je “alle pagina’s met reputatieschade wilt verwijderen”.
Bijvoorbeeld, als je negatieve Q&A’s van Yahoo! Chiebukuro wilt verwijderen via een gerechtelijke procedure, en je kijkt naar de Google-zoekresultaten en besluit dat “er zijn slechts twee doelen” en gaat verder met de procedure, dan zal een van de resterende 5-2=3 items worden weergegeven in de zoekresultaten na succesvolle verwijdering.
Geavanceerd Google zoeken met behulp van ‘zoekoperators’
Van de bovengenoemde problemen is de functie ‘zoekoperators’ van Google vooral nodig om het derde probleem op te lossen.
Google stelt inderdaad een limiet van ‘in principe 2 pagina’s per site’ voor de functie ‘zoeken naar pagina’s met het betreffende trefwoord van over het hele internet’ (globaal zoeken). Echter, door de ‘zoekoperator’ ‘trefwoord site:URL van de doelsite’ te gebruiken, kunt u:
- Alleen zoeken binnen de artikelen van de opgegeven doelsite
- Er is geen limiet van ‘in principe 2 pagina’s per site’ voor deze zoekresultaten
een dergelijke zoekopdracht uitvoeren.
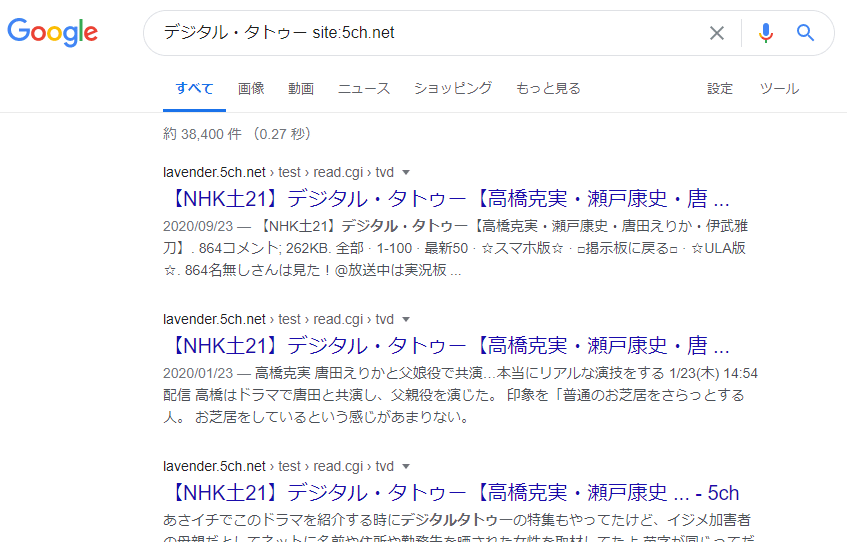
‘Zoekoperators’ zijn in werkelijkheid veel complexer en er bestaan ook zoekoperators die worden gebruikt om andere problemen dan de bovengenoemde op te lossen.
Speciale zoekmethoden voor specifieke sites
Bijvoorbeeld, Yahoo! Chiebukuro (Yahoo! Answers in Japan) heeft een unieke zoekfunctie.
Deze zoekfunctie zoekt niet in ‘webpagina’s die Google (toevallig) heeft geïndexeerd’, maar in ‘de database van Yahoo! Chiebukuro, rechtstreeks door het zoekprogramma van Yahoo! Chiebukuro’. Dit lost het eerder genoemde probleem op dat ‘er webpagina’s bestaan die Google nog niet heeft geïndexeerd’. Met andere woorden, als het een pagina binnen Yahoo! Chiebukuro is, kan alles zonder uitzondering worden gevonden door de zoekfunctie van Yahoo! Chiebukuro te gebruiken.
Dus,
Als er een feit (een bedrijfsschandaal, een individuele arrestatie, enz.) is waarvoor een pagina op Yahoo! Chiebukuro is gevonden in een globale zoekopdracht, dan kan een volledige lijst worden gemaakt zonder iets te missen door de zoekfunctie van Yahoo! Chiebukuro te gebruiken in plaats van de ‘site:’ zoekopdracht.
Dat is het punt.
Hetzelfde geldt voor Twitter. Vanwege de aard van de dienst, zijn er vaak meerdere tweets over een bepaald feit (een bedrijfsschandaal, een individuele arrestatie, enz.). Niet alle van deze tweets zijn noodzakelijkerwijs geïndexeerd door Google, en niet alle worden noodzakelijkerwijs weergegeven in een globale zoekopdracht.
Hoe het aantal ‘1 item’ voor verwijdering wordt geteld

De relatie tussen een juiste lijst en ‘URL’
Tot nu toe hebben we geschreven over ‘hoe je zoveel mogelijk webpagina’s (URL’s) kunt vinden met behulp van Google-zoekopdrachten’, maar dat betekent niet noodzakelijk dat het beter is om zoveel mogelijk te lijsten. Dit komt omdat het doelwit van een verwijderingsverzoek niet noodzakelijkerwijs ‘URL’ als eenheid heeft.
In het geval van 5chan (5ちゃんねる)
Dit is een kwestie die vooral problematisch is bij forumsites (zoals 5chan en zijn kloonsites, en andere forumsites).
Bijvoorbeeld, als je een bepaald trefwoord zoekt in Google met de zoekopdracht ‘site:5ch.net’, oftewel, zoeken binnen 5chan, kunnen de volgende soorten URL’s worden weergegeven als zoekresultaten:
- ○○○.5ch.net/test/read.cgi/○○/○○○○/40
- ○○○.5ch.net/test/read.cgi/○○/○○○○/1-100
- ○○○.5ch.net/test/read.cgi/○○/○○○○/30-
5chan heeft de volgende specificaties:
- Als je het reactienummer na de URL van de thread schrijft, wordt alleen die reactie weergegeven
- Als je een bereik van reactienummers zoals ‘A-B’ na de URL van de thread schrijft, worden alleen de reacties binnen dat bereik weergegeven
- Als je een startpunt van reactienummers en een ‘-‘ na de URL van de thread schrijft, worden alle reacties vanaf dat nummer weergegeven
Met andere woorden, als het trefwoord alleen in reactie nummer 40 is geschreven, worden verschillende URL’s (webpagina’s) weergegeven in de ‘zoekresultaten’.
Echter, wanneer je een verwijderingsverzoek indient voor een forumsite, is de eenheid van het doelwit van het verzoek in principe de ‘reactie’. Daarom, als je reactie nummer 40 wilt verwijderen, hoef je alleen maar de volgende URL te extraheren:
- ○○○.5ch.net/test/read.cgi/○○/○○○○/40
En je hoeft de laatste twee niet te vermelden.
In het geval van 5chan kloonsites en samenvattingssites
Om nog ingewikkelder te maken, zelfs binnen dezelfde 5chan (serie), is de eenheid van het verwijderingsverzoek voor kloonsites en ‘samenvattingssites’ niet de ‘reactie’, maar de ‘pagina (thread)’. Welke eenheid het doelwit is van het verwijderingsverzoek voor welke site is volledig een kwestie van ‘knowhow’.
https://monolith.law/reputation/delation-of-scraping-site-roundup-website[ja]
Daarom, zonder:
- Begrip van de eenheid van het wettelijke verwijderingsverzoek
- Begrip van de URL-specificaties van een bepaalde website (zoals de complexe regels van 5chan hierboven)
is het moeilijk om ‘het doelwit van verwijdering op te sommen terwijl je naar de zoekresultaten kijkt’.
Zoeken buiten het open web

Tot nu toe hebben we het gehad over sites die Google mogelijk indexeert, maar er zijn ook sites die:
- Google zal zeker niet indexeren
- Maar ze moeten wel in overweging worden genomen als doelwit voor verwijderingsverzoeken in het kader van reputatieschadebeheer
Google indexeert alleen websites die voor iedereen zichtbaar zijn zonder in te loggen (het open web). Er zijn echter ook diensten op deze wereld, zoals “betaalde webdiensten waar je oude krantenartikelen in bulk kunt zoeken en bekijken (en dus moet je je registreren of inloggen om ze te kunnen zien)”.
Bijvoorbeeld, in het geval van het verwijderen van arrestatieartikelen, is het noodzakelijk om ook de bovengenoemde krantendatabasesites zorgvuldig te onderzoeken. Dit komt omdat veel bedrijven die de kredietwaardigheid van bedrijven of individuen onderzoeken, gebruik maken van deze krantendatabasesites.
Voor meer informatie over krantendatabasesites, zie het onderstaande artikel.
https://monolith.law/reputation/criminal-record-newspaper-database[ja]
Samenvatting
Zoals hierboven beschreven, is het opstellen van een lijst met doelen voor verwijderingsverzoeken als onderdeel van reputatieschadebeheer op het internet een zeer gespecialiseerde taak. Ons kantoor voert dergelijke lijstwerkzaamheden uit bij het behandelen van reputatieschade, maar deze taak vereist een hoge mate van expertise op het gebied van IT en internet.
Het verwijderen van pagina’s (of berichten op forums) als onderdeel van reputatieschadebeheer op het internet is een taak die alleen door een advocaat kan worden uitgevoerd.
https://monolith.law/reputation/hiben-koui[ja]
Aan de andere kant is deze lijstwerkzaamheid, zoals uitgelegd in dit artikel, een taak die een zeer hoge mate van IT- en internetkennis vereist. Dit is een van de grote redenen waarom het raadzaam is om reputatieschadebeheer toe te vertrouwen aan een advocatenkantoor met geavanceerde expertise op het gebied van IT en internet. Als de bovengenoemde lijstwerkzaamheid te licht wordt opgevat, kunnen de volgende problemen ontstaan:
- Zelfs als alle opgelijste pagina’s zijn verwijderd, kunnen andere pagina’s die niet werden weergegeven in de wereldwijde zoekresultaten op het moment van de lijstwerkzaamheid, in de zoekresultaten verschijnen, waardoor extra verwijdering nodig is en de oorspronkelijke budgetberekening aanzienlijk onjuist blijkt te zijn.
- Wat betreft de gerechtelijke procedures, hoewel ze in principe in één keer zouden moeten worden afgehandeld, kunnen ze twee of drie keer nodig zijn, wat leidt tot buitensporige kosten.
- Het niet opmerken van het bestaan van pagina’s buiten het open web, zoals krantendatabasesites, kan ertoe leiden dat problemen zoals “moeilijkheden bij het vinden van werk vanwege arrestatieartikelen” niet worden opgelost.
Dit zijn de redenen waarom dergelijke problemen kunnen ontstaan.
Category: Internet
Related Articles

Wat zijn de belangrijke punten in de gebruiksvoorwaarden van YouTube? Een advocaat legt uit wat .
Internet




Wat zijn de methoden om recensies van ziekenhuizen te verwijderen en wat is reputatieschadebehee.
Internet















