Wstępne założenia dotyczące zarządzania ryzykiem reputacyjnym: Wyjaśnienie metody analizy negatywnych artykułów w Internecie

W przypadku chęci usunięcia ze stron internetowych wszelkich informacji dotyczących przeszłych skandali w firmie, wybuchów gniewu, aresztowań czy przestępstw, pierwszym krokiem jest stworzenie pełnej listy tych negatywnych stron i postów. Bez takiej listy nie jest możliwe przeprowadzenie skutecznych działań mających na celu zarządzanie ryzykiem związanym z reputacją, patrząc na całość problemu. Na przykład, jeśli przeoczymy coś podczas tworzenia listy, może to prowadzić do konieczności przeprowadzenia dwukrotnie takich procedur sądowych jak tymczasowe postanowienia czy procesy, które powinny zostać zakończone za pierwszym razem.
Jednakże, stworzenie pełnej listy wszystkich stron internetowych i postów, które zawierają informacje na temat pewnych faktów (na przykład skandali w firmie, wybuchów gniewu, aresztowań czy przestępstw) nie jest zadaniem „łatwym”. Ta część pracy wymaga wysokiej specjalizacji i nie jest możliwa do wykonania bez odpowiedniej wiedzy i doświadczenia.
Kancelaria prawna Monolis, z zespołem składającym się z byłych inżynierów IT i specjalistów od badań internetowych, jest specjalistą w dziedzinie zarządzania ryzykiem związanym z reputacją. Poniżej wyjaśniamy, jak powinno być przeprowadzane badanie internetowe.
Co to są wyniki wyszukiwania Google i jakie mają ograniczenia?
Podstawą badań w internecie jest niewątpliwie wyszukiwarka Google. Jednakże, wyniki wyszukiwania w Google dla słów kluczowych, które chcesz znaleźć, na przykład w przypadku usunięcia artykułów o aresztowaniu, takich jak “moje nazwisko aresztowanie”, mają ograniczenia w trzech aspektach.
Strony internetowe objęte wyszukiwarką Google
W Internecie istnieje “niezliczona” ilość stron internetowych. Teoretycznie niemożliwe jest zmierzenie całkowitej liczby stron internetowych w Internecie, ale według niektórych źródeł, liczba “witryn internetowych” wynosi obecnie około 1,8 miliarda.
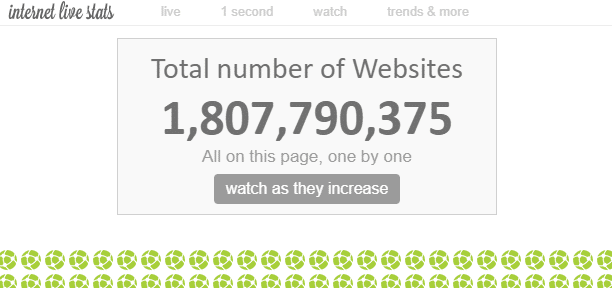
Na jednej stronie internetowej istnieje wiele stron, więc liczba stron internetowych jest znacznie większa.
A wyszukiwanie w Google, mówiąc prosto, polega na:
- Przeszukiwaniu Internetu przez bota Google (Googlebot), wykrywaniu nowych stron internetowych, które można otworzyć, podążając za linkami ze znanych stron internetowych
- Zrozumieniu zawartości tej strony (rejestracja w indeksie)
- Wyświetleniu tej strony w wynikach wyszukiwania, gdy wyszukiwanie jest przeprowadzane za pomocą słów kluczowych zawartych na tej stronie
Co chcę powiedzieć, to to, że strony wyświetlane w wyszukiwarce Google to strony, które Google zarejestrował w indeksie w powyższy sposób, a nie “wszystkie strony internetowe”. Innymi słowy, jeśli korzystasz z wyszukiwarki Google, nie możesz znaleźć “stron internetowych, które Google jeszcze nie zarejestrował w indeksie”, a co więcej, nie istnieje sposób na znalezienie wszystkich stron internetowych w Internecie bez żadnych wyjątków.
“Podobne” strony internetowe są wykluczane z wyników wyszukiwania
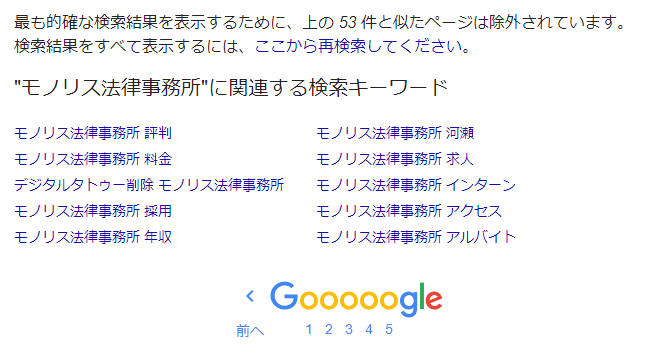
Google nie wyświetla we wynikach wyszukiwania “wszystkich stron internetowych zawierających słowo kluczowe, które są zarejestrowane w indeksie”. Można to zauważyć podczas normalnego korzystania z wyszukiwarki Google. Na ostatniej stronie wyników wyszukiwania pojawia się komunikat: “Aby wyświetlić najdokładniejsze wyniki wyszukiwania, strony podobne do powyższych ○ zostały wykluczone”.
Na przykład,
- Wiadomość jest pierwotnie dystrybuowana na dużym portalu informacyjnym
- Wiadomość jest następnie przenoszona na serwisy agregujące artykuły
- Wiadomość jest również przenoszona na strony osobiste itp.
W takim przypadku, jeśli strony o tej samej treści zapełnią wyniki wyszukiwania, będzie to niewygodne dla użytkowników. Dlatego Google automatycznie wyklucza “podobne” strony z wyników wyszukiwania, w tym przypadku 2 i 3.
Nie zawsze jest to “użyteczna” funkcja, zwłaszcza gdy chcesz usunąć strony z negatywnymi opiniami. Na przykład, jeśli powyższa “wiadomość” dotyczy twojego poprzedniego aresztowania,
Wyniki wyszukiwania wyświetlały tylko “1. Artykuł pierwotnie dystrybuowany przez duży portal informacyjny”, więc usunąłeś tylko tę stronę. Po usunięciu 1, “2. Artykuł przeniesiony na serwis agregujący artykuły” zaczyna pojawiać się w wynikach wyszukiwania Google.
To jest możliwe.
Problem ten można rozwiązać, klikając na “Aby wyświetlić wszystkie wyniki wyszukiwania, wyszukaj ponownie stąd”, ale jeśli nie znasz tej funkcji, możesz “przegapić” strony z negatywnymi opiniami.
Istnieje limit liczby artykułów wyświetlanych z tej samej strony

Dodatkowo, Google ustala limit dla liczby stron wyników wyszukiwania wyświetlanych z jednej strony internetowej. Ta funkcja jest nieco skomplikowana, ale mówiąc prosto, “maksymalnie dwie strony są wyświetlane z tej samej strony”.
Co to oznacza? Na przykład, nawet jeśli na stronie Yahoo! Chiebukuro (Japoński Yahoo! Answers) istnieje pięć Q&A, w których pojawia się nazwa firmy lub osoby, w wynikach wyszukiwania Google dla tej firmy lub osoby, strony z Yahoo! Chiebukuro są wyświetlane maksymalnie na dwóch stronach. To samo dotyczy forów dyskusyjnych, nawet jeśli istnieje pięć wątków na 5ch (Japoński odpowiednik Reddit) zawierających pewne słowo kluczowe, w wynikach wyszukiwania Google wyświetlane są maksymalnie dwa. Na przykład, jeśli ta sama osoba ma:
- Artykuł o aresztowaniu
- Artykuł o ponownym aresztowaniu
- Artykuł o wyroku skazującym
Jeśli te trzy artykuły istnieją na tej samej stronie z wiadomościami, co najmniej jeden z nich (3-2=1) nie będzie wyświetlany w wynikach wyszukiwania Google.
Kiedy wyszukujesz pewnego słowa kluczowego, jeśli strony z tej samej strony (na przykład Yahoo! Chiebukuro, określone forum dyskusyjne, określona strona z wiadomościami itp.) są wyświetlane w dużej ilości w wynikach wyszukiwania, jest to niewygodne dla użytkownika, dlatego Google ma taką funkcję.
Jednak ta funkcja nie jest zawsze “łatwa do użycia”, zwłaszcza gdy chcesz “usunąć wszystkie strony z negatywnymi opiniami”.
Na przykład, jeśli chcesz usunąć negatywne Q&A z Yahoo! Chiebukuro za pomocą procedury sądowej, patrząc na wyniki wyszukiwania Google, możesz stwierdzić, że “jest tylko dwa cele” i kontynuować procedurę. Jednak po udanym usunięciu, jedno z pozostałych trzech (5-2=3) może zacząć pojawiać się w wynikach wyszukiwania.
Zaawansowane wyszukiwanie w Google za pomocą “wzorców wyszukiwania”
Z powyższych problemów, szczególnie trzeci problem, można rozwiązać za pomocą funkcji Google zwanej “wzorcem wyszukiwania”.
Google rzeczywiście ma funkcję, która “wyszukuje strony zawierające dany słowo kluczowe z całego Internetu” (wyszukiwanie globalne), ale ustala limit “podstawowo 2 strony na stronę”. Jednak, jeśli użyjesz “wzorca wyszukiwania” w formie “słowo kluczowe site:URL docelowej strony”,
- możesz przeprowadzić wyszukiwanie tylko w artykułach na określonej stronie docelowej
- nie ma limitu “podstawowo 2 strony na stronę” w wynikach tego wyszukiwania
Można przeprowadzić takie wyszukiwanie.
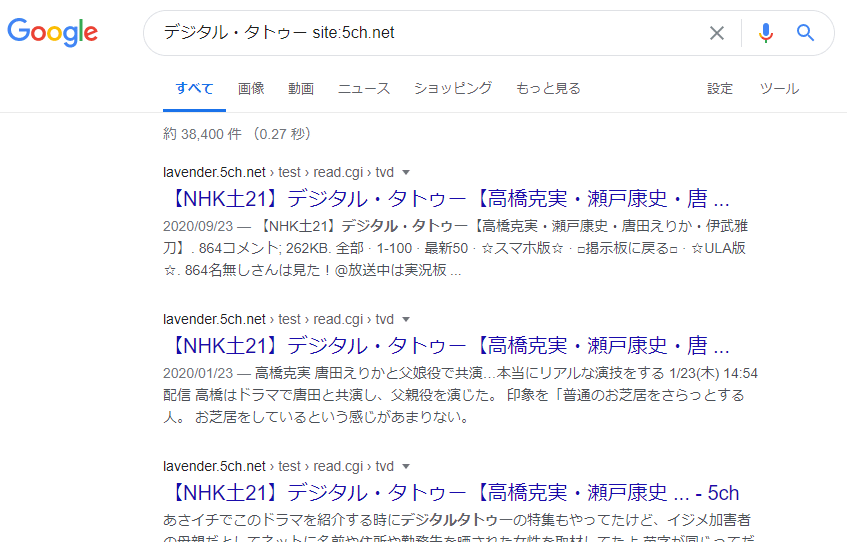
“Wzorce wyszukiwania” są w rzeczywistości bardziej skomplikowane, a istnieją również wzorce wyszukiwania używane do rozwiązywania problemów innych niż te wymienione powyżej.
Szczególne metody wyszukiwania dla określonych stron
Na przykład, Yahoo! Chiebukuro (Japoński Yahoo! Answers) posiada unikalną funkcję wyszukiwania.
Ta funkcja wyszukiwania nie polega na “stronach internetowych, które Google (przypadkiem) zaindeksował”, ale na “wynikach wyszukiwania bezpośrednio w bazie danych Yahoo! Chiebukuro przez program wyszukiwania Yahoo! Chiebukuro”. Rozwiązuje to problem, o którym wspomniałem na początku, że “istnieją strony internetowe, które Google jeszcze nie zaindeksował”. Oznacza to, że “jeśli strona jest na Yahoo! Chiebukuro, można ją znaleźć bez żadnych braków, używając tylko funkcji wyszukiwania Yahoo! Chiebukuro”.
W skrócie,
Jeśli strony Yahoo! Chiebukuro zostały znalezione w globalnym wyszukiwaniu na temat pewnego faktu (niewłaściwe działania firmy, aresztowanie osoby itp.), korzystanie z funkcji wyszukiwania Yahoo! Chiebukuro jest bardziej efektywne niż korzystanie z formuły wyszukiwania “site:”, aby uzyskać kompletną listę bez żadnych braków.
To jest właśnie to, co chciałem powiedzieć.
To samo dotyczy Twittera. Ze względu na charakter tej usługi, Twitter jest stroną, na której często pojawiają się wiele tweetów na temat danego faktu (niewłaściwe działania firmy, aresztowanie osoby itp.). Nie wszystkie te tweety są koniecznie zarejestrowane w indeksie Google, a przynajmniej nie wszystkie są wyświetlane w globalnym wyszukiwaniu.
Metoda liczenia “1” elementu do usunięcia

Związek między odpowiednim wykazem a “URL”
Do tej pory pisałem o “metodzie wyłapywania jak najwięcej stron internetowych (URL) za pomocą Google Search itp.”, ale to nie oznacza, że im więcej wylistujesz, tym lepiej. To dlatego, że jednostką wniosku o usunięcie nie jest koniecznie “URL”.
W przypadku 5ch.net
To jest problem, który pojawia się szczególnie w przypadku stron typu forum (takich jak 5ch.net, jego strony kopii, inne fora itp.).
Na przykład, jeśli wyszukasz pewne słowo kluczowe w Google za pomocą formuły wyszukiwania “site:5ch.net”, czyli wyszukujesz wewnątrz 5ch.net, mogą pojawić się takie URL w wynikach wyszukiwania:
- ○○○.5ch.net/test/read.cgi/○○/○○○○/40
- ○○○.5ch.net/test/read.cgi/○○/○○○○/1-100
- ○○○.5ch.net/test/read.cgi/○○/○○○○/30-
5ch.net ma takie funkcje, że:
- Jeśli po URL wątku wpiszesz numer odpowiedzi, wyświetli tylko tę odpowiedź
- Jeśli po URL wątku wpiszesz zakres numerów odpowiedzi w formacie “A-B”, wyświetli tylko odpowiedzi w tym zakresie
- Jeśli po URL wątku wpiszesz numer odpowiedzi i “-“, wyświetli wszystkie odpowiedzi od tego numeru
W rezultacie, jeśli słowo kluczowe jest napisane tylko w odpowiedzi numer 40, różne URL (strony internetowe) są wyświetlane jako “wyniki wyszukiwania”.
Jednakże, kiedy składasz wniosek o usunięcie z forum, jednostką wniosku jest zasadniczo “odpowiedź”. Dlatego, jeśli chcesz usunąć odpowiedź numer 40, wystarczy wyodrębnić tylko
- ○○○.5ch.net/test/read.cgi/○○/○○○○/40
URL, a nie musisz wykazywać dwóch pozostałych.
W przypadku stron kopii 5ch.net i stron zbiorczych
Dodatkowo, co jest jeszcze bardziej skomplikowane, nawet w przypadku tego samego 5ch.net (i podobnych), w przypadku stron kopii i “stron zbiorczych”, jednostką wniosku o usunięcie jest “strona (wątek)”, a nie “odpowiedź”. To, co jest celem wniosku o usunięcie z której strony, jest całkowicie w obszarze “know-how”.
W związku z tym,
- Zrozumienie jednostki prawnej wniosku o usunięcie
- Zrozumienie specyfikacji URL danej strony internetowej (na przykład 5ch.net ma skomplikowane zasady, jak opisano powyżej)
jest niezbędne, aby “wykazać cele usunięcia podczas przeglądania wyników wyszukiwania” było możliwe.
Wyszukiwanie poza otwartym internetem

Do tej pory omówiliśmy strony, które Google może potencjalnie zaindeksować, ale istnieją również strony:
- które Google na pewno nie zaindeksuje,
- które jednak powinny być brane pod uwagę jako potencjalne cele do usunięcia w ramach zarządzania ryzykiem reputacyjnym.
Google, ze względu na swoje specyfikacje, nie uwzględnia w swoich wyszukiwaniach stron internetowych, które są dostępne dla wszystkich bez logowania (otwarty internet). Jednak na świecie istnieją również takie usługi internetowe, które umożliwiają wyszukiwanie i przeglądanie archiwalnych artykułów z gazet za opłatą (a więc nie można ich zobaczyć bez rejestracji lub logowania).
Na przykład, w przypadku usuwania artykułów o aresztowaniach, konieczne jest również dokładne sprawdzenie powyższych stron z bazami danych gazet. Firmy badające kredytową wiarygodność firm i osób fizycznych często korzystają z tych stron z bazami danych gazet.
Szczegółowe informacje na temat stron z bazami danych gazet znajdują się w poniższym artykule.
Podsumowanie
Jak widać powyżej, “tworzenie listy celów do usunięcia w ramach zarządzania ryzykiem reputacyjnym w Internecie” to zadanie wymagające wysokiej specjalizacji. Nasza kancelaria wykonuje takie listy celów podczas podejmowania działań związanych z zarządzaniem ryzykiem reputacyjnym, ale ta praca zakłada specjalizację w dziedzinie IT i Internetu.
Usunięcie strony (lub odpowiedzi na forum) w ramach zarządzania ryzykiem reputacyjnym w Internecie to zadanie, które może wykonać tylko prawnik.
Z drugiej strony, tworzenie tej listy, jak wyjaśniono w tym artykule, jest zadaniem, które wymaga bardzo zaawansowanej wiedzy z zakresu IT i Internetu. To jest jeden z głównych powodów, dla których powinniśmy zlecić zarządzanie ryzykiem reputacyjnym kancelarii prawniczej, która posiada zaawansowaną specjalizację w dziedzinie IT i Internetu. Jeśli lista jest niedokładna, mogą wystąpić następujące problemy:
- Nawet jeśli usuniemy wszystkie strony z listy, inne strony, które nie były wyświetlane w wynikach globalnego wyszukiwania podczas tworzenia listy, mogą pojawić się w wynikach wyszukiwania, co wymaga dodatkowego usuwania i sprawia, że początkowe oszacowanie budżetu jest znacznie błędne.
- Procedury sądowe, które powinny zakończyć się po jednym razie, stają się konieczne dwa lub trzy razy, co generuje nadmierne koszty.
- Nie zauważamy istnienia stron poza otwartym internetem, takich jak bazy danych gazet, co oznacza, że nie rozwiązujemy “problemów”, takich jak “trudności w znalezieniu pracy z powodu wyszukiwania artykułów o aresztowaniu”.
Właśnie dlatego mogą wystąpić takie problemy.
Category: Internet




















