Vysvětlení metody prozkoumání negativních článků na internetu jako předpoklad pro opatření proti poškození pověsti

V případě, že chcete kompletně odstranit webové stránky týkající se minulých skandálů ve společnosti, výbuchů, zatčení nebo trestních činů, je nejprve nutné předpokládat, že je třeba “všechny negativní stránky a příspěvky vypsat tak, aby nebyly žádné vynechány”. Pokud tento seznam není možné vytvořit, nelze pokračovat v řešení poškození pověsti, aniž byste viděli celkový objem, a například v případě předběžných opatření nebo soudních řízení, které by měly být původně ukončeny jednou, existuje riziko, že budou muset být provedeny dvakrát kvůli přehlédnutí.
Avšak, vytvoření seznamu všech webových stránek a příspěvků, které popisují určitý fakt (například skandály ve společnosti, výbuchy, zatčení nebo trestní činy) na internetu, rozhodně není “jednoduché”. Tato část vyžaduje velmi vysokou odbornost a know-how, bez kterého není možné tuto práci provést.
Právnická kancelář Monolith je právnická kancelář specializující se na řešení poškození pověsti, která má v týmu bývalé IT inženýry a právníky, stejně jako personál specializující se na výše uvedený výzkum na internetu. Níže vysvětlíme, jak by měl být internetový výzkum prováděn.
Co jsou výsledky vyhledávání Google a jejich omezení?
Základem internetového výzkumu je nepochybně vyhledávání Google. Avšak výsledky vyhledávání na Google, když hledáte klíčová slova, která chcete najít, například v případě odstranění článků o zatčení, když hledáte klíčová slova jako “mé jméno zatčení”, mají omezení ve třech směrech.
Webové stránky, které jsou cílem vyhledávání Google
Na internetu existuje “nespočet” webových stránek. Celkový počet webových stránek na internetu je teoreticky neměřitelný, ale podle některých odhadů je počet “webových stránek” v současné době asi 1,8 miliardy.
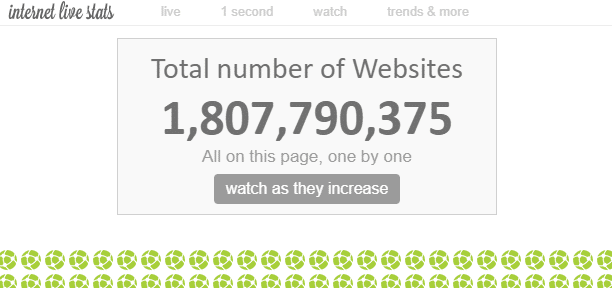
Jelikož na jedné webové stránce existuje více webových stránek, počet webových stránek je mnohem vyšší.
A co je vyhledávání Google? Jednoduše řečeno,
- Bot Google (Googlebot) prochází internetem, detekuje nové webové stránky, které lze otevřít sledováním odkazů z již známých webových stránek
- Rozumí obsahu této stránky (registrace do indexu)
- Když je vyhledávání provedeno klíčovými slovy obsaženými na této stránce, zobrazí tuto stránku ve výsledcích vyhledávání
Tento mechanismus je používán. Co chci říct je, že to, co je zobrazeno ve vyhledávání Google, jsou webové stránky, které Google zaregistroval do indexu “takto”, nikoli “všechny webové stránky”. Jinými slovy, pokud používáte vyhledávání Google, nemůžete najít “webové stránky, které Google ještě nezaregistroval do indexu”, a vůbec neexistuje způsob, jak najít všechny webové stránky na internetu bez jediného vynechání.
“Podobné” webové stránky jsou vyřazeny z výsledků vyhledávání
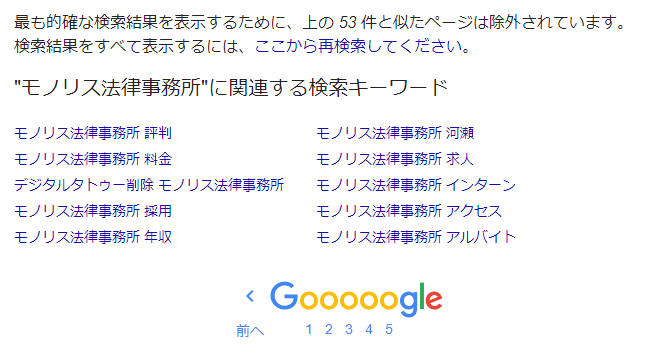
Google také nezobrazuje “všechny webové stránky obsahující vyhledávací klíčová slova” z webových stránek zaregistrovaných v indexu ve výsledcích vyhledávání. To je něco, co si můžete všimnout, pokud běžně používáte Google vyhledávání. Na poslední stránce výsledků vyhledávání se zobrazuje zpráva “Abychom zobrazili nejpřesnější výsledky vyhledávání, stránky podobné těmto ○ jsou vyřazeny”.
Například,
- určitá zpráva je poprvé zveřejněna na hlavních zpravodajských webech
- zpráva je převzata na webech, které shrnují zpravodajské články
- zpráva je také převzata na osobních webech
V takovém případě, pokud by výsledky vyhledávání zaplnily stránky se stejným obsahem, bylo by to pro uživatele nepohodlné, takže Google automaticky vyřazuje “podobné” stránky, v tomto případě 2 a 3, z výsledků vyhledávání.
To nemusí být vždy “uživatelsky přívětivé” pro ty, kteří chtějí “vymazat stránky s poškozením pověsti”. Například, pokud je výše uvedená “určitá zpráva” o vašem minulém zatčení,
Výsledky vyhledávání zobrazovaly pouze “1. článek poprvé zveřejněný na hlavním zpravodajském webu”, takže když jste odstranili pouze tuto stránku, po odstranění 1 se “2. článek převzatý na webu, který shrnuje zpravodajské články” začal zobrazovat ve výsledcích vyhledávání Google
To je možný scénář.
Tento problém lze vyřešit kliknutím na “Pro zobrazení všech výsledků vyhledávání znovu vyhledejte zde” výše uvedeném zobrazení, ale pokud neznáte tuto funkci nebo specifikaci, můžete “přehlédnout” stránky poškozující pověst.
Na počet článků zobrazovaných z jedné stránky existuje limit

Dále Google nastavuje limit na počet stránek s výsledky vyhledávání zobrazovaných z jedné webové stránky. Tato specifikace je trochu složitá, ale jednoduše řečeno, “maximální počet stránek zobrazovaných z jedné stránky je dva”.
Jinými slovy, například, i když existuje pět Q&A, ve kterých se objevuje jméno určité společnosti nebo jednotlivce na stránkách Yahoo! Chiebukuro (japonský Yahoo! Answers), ve výsledcích vyhledávání Google pro danou společnost nebo jednotlivce se zobrazí maximálně dvě stránky z Yahoo! Chiebukuro. Totéž platí pro diskusní fóra, i když existuje pět vláken na 5ch (japonské diskusní fórum) obsahujících určité klíčové slovo, ve výsledcích vyhledávání Google se zobrazí maximálně dvě. Například, pokud existují tři články o určité osobě,
- Článek o zatčení
- Článek o opětovném zatčení
- Článek o odsouzení
na stejném zpravodajském webu, alespoň jeden z nich (3-2=1) se ve výsledcích vyhledávání Google nezobrazí.
Když vyhledáváte určité klíčové slovo a stránky z jedné stránky (například Yahoo! Chiebukuro, konkrétní diskusní fórum, konkrétní zpravodajský web atd.) se ve výsledcích vyhledávání objeví ve velkém množství, je to pro uživatele nepohodlné, a proto Google má takovou specifikaci.
Avšak, tato specifikace nemusí být vždy “uživatelsky přívětivá”, pokud chcete “úplně odstranit stránky s poškozenou reputací”.
Například, pokud chcete odstranit negativní Q&A z Yahoo! Chiebukuro prostřednictvím soudního řízení, jak je uvedeno výše, a podíváte se na výsledky vyhledávání Google a rozhodnete, že “existují pouze dva cíle”, a pokračujete v procesu, po úspěšném odstranění se zobrazí některý z zbývajících tří (5-2=3) ve výsledcích vyhledávání.
Pokročilé vyhledávání na Google pomocí “vyhledávacích výrazů”
Z výše uvedených problémů je zvláště třetí problém, který vyžaduje funkci Google zvanou “vyhledávací výrazy”.
Google skutečně nastavuje limit “zásadně 2 stránky na web” pro funkci “vyhledávání stránek obsahujících dané klíčové slovo z celého internetu” (globální vyhledávání). Avšak, pokud použijete “vyhledávací výraz” ve formátu “klíčové slovo site:URL cílového webu”, můžete provést vyhledávání, které:
- Provádí vyhledávání pouze v článcích na specifikovaném cílovém webu
- V těchto výsledcích vyhledávání neexistuje limit “zásadně 2 stránky na web”
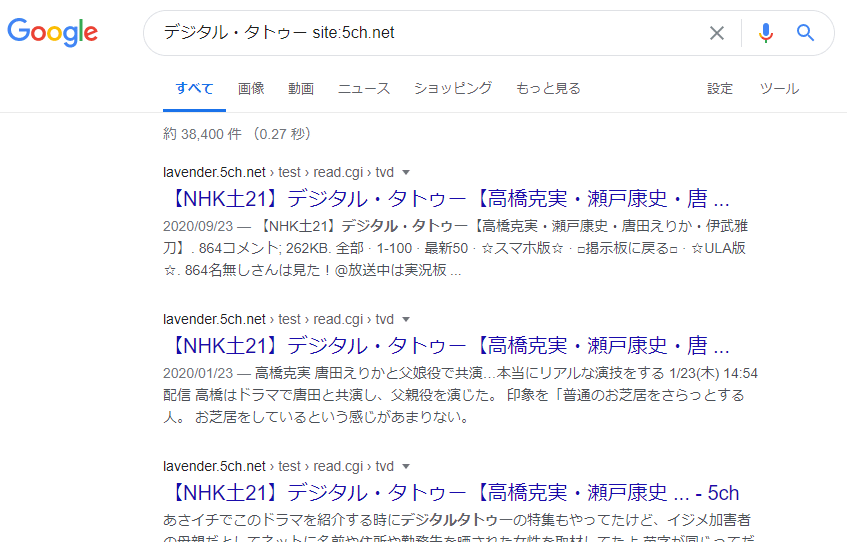
“Vyhledávací výrazy” jsou ve skutečnosti mnohem složitější a existují také vyhledávací výrazy, které se používají k řešení jiných problémů než těch, které jsou uvedeny výše.
Speciální vyhledávací prostředky pro konkrétní stránky
Například, na Yahoo! Chiebukuro (Japonská verze Yahoo! Answers) existuje vlastní vyhledávací funkce.
Toto vyhledávání není založeno na “webových stránkách, které Google (náhodou) zaregistroval do svého indexu”, ale na “výsledcích vyhledávání v databázi Yahoo! Chiebukuro, které provedl přímo vyhledávací program Yahoo! Chiebukuro”. To řeší problém, o kterém jsme hovořili na začátku, že “existují webové stránky, které Google ještě nezaregistroval do svého indexu”. To znamená, že “pokud jde o stránky na Yahoo! Chiebukuro, pokud použijete vyhledávací funkci Yahoo! Chiebukuro, můžete je všechny najít bez jakýchkoli vynechání”.
Jinými slovy,
Pokud byl na globálním vyhledávání objevena stránka Yahoo! Chiebukuro týkající se určité skutečnosti (např. skandálu společnosti, zatčení jednotlivce atd.), je možné provést úplný seznam bez vynechání pomocí vyhledávací funkce Yahoo! Chiebukuro, spíše než použitím vyhledávacího výrazu “site:”.
To je to, co to znamená.
Toto platí také pro Twitter a podobné platformy. Twitter je, vzhledem k povaze své služby, stránka, na které často existuje mnoho tweetů týkajících se daného tématu (např. skandálu společnosti, zatčení jednotlivce atd.). Tyto tweety nejsou nutně všechny zaregistrovány v indexu Google a rozhodně nejsou všechny zobrazeny na globálním vyhledávání.
Metoda počítání “1 položky” určené k odstranění

Vztah mezi správným výčtem a “URL”
Dosud jsme psali o “metodě pro nalezení co nejvíce webových stránek (URL) pomocí Google vyhledávání atd.”, ale to neznamená, že čím více jich vypíšeme, tím lépe. To proto, že cílem žádosti o odstranění není nutně “URL” jako jednotka.
V případě 5chan
Toto je záležitost, která se stává problémem zejména v případě webových stránek s diskusními fóry (jako je 5chan a jeho kopie, a další diskusní fóra).
Například, pokud hledáte určité klíčové slovo v Google pomocí vyhledávacího výrazu “site:5ch.net”, tedy hledání uvnitř 5chan, mohou se výsledky vyhledávání zobrazit jako následující URL:
- ○○○.5ch.net/test/read.cgi/○○/○○○○/40
- ○○○.5ch.net/test/read.cgi/○○/○○○○/1-100
- ○○○.5ch.net/test/read.cgi/○○/○○○○/30-
5chan má následující specifikace:
- Pokud za URL vlákna napíšete číslo odpovědi, zobrazí se pouze daná odpověď
- Pokud za URL vlákna napíšete rozsah čísel odpovědí jako “A-B”, zobrazí se pouze odpovědi v daném rozsahu
- Pokud za URL vlákna napíšete číslo odpovědi a “-“, zobrazí se všechny odpovědi od daného čísla dál
Jinými slovy, pokud je klíčové slovo napsáno pouze v odpovědi číslo 40, různé URL (webové stránky) se zobrazí jako “výsledky vyhledávání”.
Avšak, pokud podáváte žádost o odstranění na webové stránky s diskusními fóry, jednotkou žádosti je alespoň v zásadě “odpověď”. Proto, pokud chcete odstranit odpověď číslo 40, stačí extrahovat pouze
- ○○○.5ch.net/test/read.cgi/○○/○○○○/40
a další dvě URL nemusíte vypisovat.
V případě kopírovacích stránek a shrnujících stránek 5chan
A pokud k tomu přidáme, ještě složitější je, že i u stejného 5chan (a podobných), v případě kopírovacích stránek a “shrnujících stránek” se jednotkou žádosti o odstranění stává “stránka (vlákno)” místo “odpovědi”, v závislosti na stránce. “Který cíl žádosti o odstranění je pro kterou stránku” je zcela v oblasti “know-how”.
https://monolith.law/reputation/delation-of-scraping-site-roundup-website[ja]
Z tohoto důvodu,
- Pochopení jednotky právní žádosti o odstranění
- Pochopení specifikací URL určité webové stránky (například 5chan má komplikovaná pravidla, jak bylo uvedeno výše)
jsou nezbytné, jinak je “vypisování cílů odstranění při prohlížení výsledků vyhledávání” samo o sobě obtížné.
Vyhledávání mimo otevřený web

Dosud jsme hovořili o webových stránkách, které Google může indexovat,
- Google je určitě neindexuje
- Ale měli bychom je zvážit jako cíl pro žádosti o odstranění v rámci řízení reputačního rizika
Existují také skupiny stránek.
Google z technických důvodů nezahrnuje do vyhledávání žádné webové stránky (otevřený web), které může kdokoli vidět bez přihlášení. Existují však například placené webové služby, které umožňují hromadné vyhledávání a prohlížení starších novinových článků (a proto je nelze vidět bez registrace uživatele nebo přihlášení).
Například v případě odstranění článků o zatčení je třeba pečlivě prozkoumat i výše uvedené databázové stránky s novinami. Společnosti, které provádějí průzkumy týkající se důvěryhodnosti firem nebo jednotlivců, často využívají tyto databázové stránky s novinami.
Podrobněji o databázových stránkách s novinami se dočtete v následujícím článku.
https://monolith.law/reputation/criminal-record-newspaper-database[ja]
Shrnutí
Jak bylo uvedeno výše, “sestavení seznamu cílů pro žádosti o odstranění jako opatření proti poškození pověsti na internetu” je velmi specializovaná činnost. Naše kancelář provádí takové sestavení seznamu cílových článků při přijímání opatření proti poškození pověsti, ale tato práce předpokládá odbornost v oblasti IT a internetu.
Odstranění stránek (nebo příspěvků na diskusních fórech) jako opatření proti poškození pověsti na internetu je činnost, kterou může provádět pouze právník.
https://monolith.law/reputation/hiben-koui[ja]
Na druhou stranu, toto sestavení seznamu je, jak bylo vysvětleno v tomto článku, činnost, která vyžaduje velmi vysokou úroveň znalostí v oblasti IT a internetu. To je jeden z hlavních důvodů, proč byste měli požádat právní kancelář s vysokou odborností v oblasti IT a internetu o opatření proti poškození pověsti. Opakuji, pokud je tento seznam nedostatečný, může dojít k problémům, jako jsou:
- I když jsou všechny stránky na seznamu odstraněny, mohou se v globálních výsledcích vyhledávání objevit další stránky, které nebyly zobrazeny v době sestavení seznamu, což vyžaduje další odstranění a původní rozpočet je značně nesprávný.
- Co se týče soudních řízení, místo jednoho by mohlo být potřeba dvě nebo tři, což by vyžadovalo nadměrné náklady.
- Neuvědomíte si existenci stránek mimo otevřený web, jako jsou databáze novin, a například “problém” s “hledáním článků o zatčení, které brání zaměstnání”, nebude vyřešen.
To jsou důvody, proč mohou nastat takové problémy.
Category: Internet
Related Articles





Jaká je definice internetového stalkera? Vysvětlení kritérií, která policie používá k zahájení v.
Internet

Žádost o zveřejnění informací o odesílateli k identifikaci přispěvatelů na Mamastadium (Mamasta)
Internet














