Η Προϋπόθεση για τα Μέτρα Αντιμετώπισης της Φήμης: Εξηγώντας τις Μεθόδους Ελέγχου των Αρνητικών Άρθρων στο Διαδίκτυο

Όταν πρόκειται για την εκκαθάριση ιστοσελίδων που αφορούν παρελθοντικά εταιρικά σκάνδαλα, περιστατικά που προκάλεσαν σάλο, συλλήψεις ή προηγούμενες καταδίκες, πρέπει πρώτα να δημιουργήσουμε μια λίστα με όλες τις αρνητικές σελίδες και δημοσιεύσεις χωρίς να παραλείψουμε καμία. Χωρίς αυτή τη λίστα, δεν μπορούμε να προχωρήσουμε στη διαχείριση της φήμης μας ενώ παρακολουθούμε τον συνολικό όγκο των σελίδων, και υπάρχει ο κίνδυνος να χρειαστεί να επαναλάβουμε δικαστικές διαδικασίες όπως προσωρινές διαταγές ή δίκες, που θα μπορούσαν να είχαν ολοκληρωθεί με μία μόνο εμφάνιση, εξαιτίας παραλείψεων.
Ωστόσο, η δημιουργία μιας λίστας με όλες τις ιστοσελίδες και δημοσιεύσεις που αναφέρονται σε ορισμένα γεγονότα (όπως εταιρικά σκάνδαλα, περιστατικά που προκάλεσαν σάλο, συλλήψεις ή προηγούμενες καταδίκες) στο διαδίκτυο δεν είναι καθόλου “εύκολη”. Αυτή η διαδικασία απαιτεί υψηλή εξειδίκευση και know-how που δεν μπορεί να επιτευχθεί χωρίς την απαραίτητη εμπειρία.
Το Νομικό Φιρμά Monolith είναι ένα δικηγορικό γραφείο με εξειδίκευση στη διαχείριση φήμης, που διαθέτει έναν δικηγόρο-ιδιοκτήτη πρώην μηχανικό πληροφορικής και προσωπικό ειδικευμένο στην έρευνα στο διαδίκτυο. Παρακάτω, θα εξηγήσουμε πώς πρέπει να διεξάγεται η έρευνα στο διαδίκτυο.
Τι είναι τα αποτελέσματα αναζήτησης της Google και ποια είναι τα όριά τους;
Η βάση της έρευνας στο διαδίκτυο είναι, φυσικά, η αναζήτηση μέσω της Google. Ωστόσο, όταν αναζητάτε στη Google με κάποιες συγκεκριμένες λέξεις-κλειδιά, για παράδειγμα για την αφαίρεση ενός άρθρου σχετικά με σύλληψη, χρησιμοποιώντας τον συνδυασμό «το ονοματεπώνυμό μου σύλληψη», τα αποτελέσματα που θα εμφανιστούν έχουν τρία σημαντικά όρια.
Ιστοσελίδες που Εντάσσονται στην Αναζήτηση της Google
Στο διαδίκτυο υπάρχουν «αμέτρητες» ιστοσελίδες. Αν και ο συνολικός αριθμός των ιστοσελίδων στο διαδίκτυο είναι θεωρητικά αδύνατον να μετρηθεί, κατά μία εκτίμηση, ο αριθμός των «ιστοτόπων» ανέρχεται περίπου σε 1,8 δισεκατομμύρια στο παρόν στάδιο.
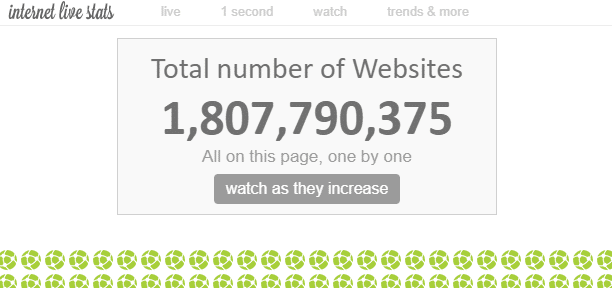
Δεδομένου ότι ένας ιστότοπος περιλαμβάνει πολλαπλές ιστοσελίδες, ο αριθμός των ιστοσελίδων είναι αναμφίβολα πολύ μεγαλύτερος.
Και η αναζήτηση της Google, απλά ειπωμένο, λειτουργεί ως εξής:
- Το bot της Google (Googlebot) σαρώνει το διαδίκτυο, ανιχνεύοντας νέες ιστοσελίδες που είναι προσβάσιμες μέσω συνδέσμων από ήδη γνωστές ιστοσελίδες
- Κατανοεί το περιεχόμενο των σελίδων (εγγραφή στον κατάλογο ή indexing)
- Και όταν γίνεται αναζήτηση με βάση κάποιες λέξεις-κλειδιά που περιέχονται σε αυτές τις σελίδες, τις εμφανίζει στα αποτελέσματα της αναζήτησης
Αυτό που θέλω να πω είναι ότι, οι ιστοσελίδες που εμφανίζονται στην αναζήτηση της Google είναι μόνο εκείνες που έχουν ενταχθεί στον κατάλογο της Google με τον παραπάνω τρόπο, και όχι «όλες οι ιστοσελίδες». Με άλλα λόγια, χρησιμοποιώντας την αναζήτηση της Google, δεν μπορείτε να βρείτε ιστοσελίδες που δεν έχουν ακόμη ενταχθεί στον κατάλογο της Google, και επιπλέον, δεν υπάρχει κανένας τρόπος να ανακαλύψετε όλες τις ιστοσελίδες του διαδικτύου χωρίς καμία παράλειψη.
Αποκλεισμός «Παρόμοιων» Ιστοσελίδων από τα Αποτελέσματα Αναζήτησης
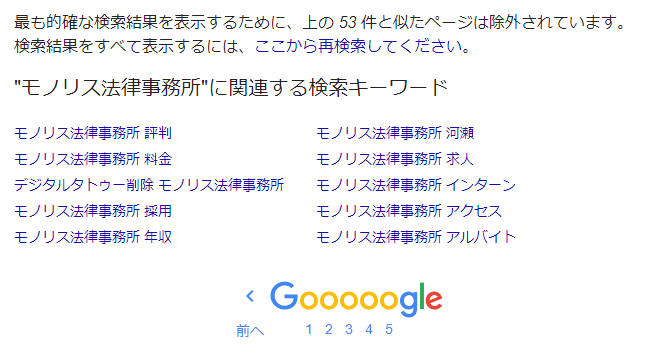
Επιπλέον, η Google δεν εμφανίζει στα αποτελέσματα αναζήτησης «όλες τις ιστοσελίδες που έχουν εγγραφεί στον κατάλογο και περιέχουν τις λέξεις-κλειδιά αναζήτησης». Αυτό μπορεί να το παρατηρήσετε κατά τη χρήση της αναζήτησης της Google. Στην τελευταία σελίδα των αποτελεσμάτων εμφανίζεται το μήνυμα «Για να παρουσιάσουμε τα πιο σχετικά αποτελέσματα αναζήτησης, έχουμε αποκλείσει κάποιες σελίδες που είναι παρόμοιες με τις παραπάνω ○ εγγραφές».
Για παράδειγμα,
- ένα νέο δημοσιεύεται αρχικά από ένα μεγάλο ειδησεογραφικό site
- στη συνέχεια αναδημοσιεύεται από υπηρεσίες που συγκεντρώνουν ειδησεογραφικά άρθρα
- και τέλος αναδημοσιεύεται και σε προσωπικές ιστοσελίδες
Σε τέτοιες περιπτώσεις, εάν οι ίδιες περιεχόμενες σελίδες κατακλύζουν τα αποτελέσματα αναζήτησης, αυτό θα ήταν δυσχερές για τους χρήστες, επομένως η Google αυτόματα αποκλείει τις «παρόμοιες» σελίδες, όπως τις 2 και 3 στο παραπάνω παράδειγμα, από τα αποτελέσματα αναζήτησης.
Αυτό δεν είναι πάντα «χρήσιμο» όταν θέλετε να εξαφανίσετε σελίδες που προκαλούν φήμες βλάβης. Για παράδειγμα, αν το παραπάνω «νέο» αφορά ένα παλιό άρθρο σχετικά με τη δική σας σύλληψη,
και το μόνο που εμφανιζόταν στα αποτελέσματα αναζήτησης ήταν «1. το αρχικό άρθρο από το μεγάλο ειδησεογραφικό site», αφού διαγράψατε εκείνη τη σελίδα, η αφαίρεση του 1 οδήγησε στην εμφάνιση του «2. άρθρου από την υπηρεσία συγκέντρωσης ειδήσεων» στα αποτελέσματα αναζήτησης της Google
Αυτό μπορεί να συμβεί και είναι ένα πρόβλημα.
Για να δείτε όλα τα αποτελέσματα αναζήτησης, μπορείτε απλώς να κάνετε κλικ στο μέρος που λέει «Κάντε εδώ επαναληπτική αναζήτηση για να εμφανίσετε όλα τα αποτελέσματα». Ωστόσο, αν δεν γνωρίζετε αυτή τη λειτουργία ή την προδιαγραφή, υπάρχει πιθανότητα να «παραβλέψετε» σελίδες που προκαλούν φήμες βλάβης.
Υπάρχει ένα όριο στον αριθμό των άρθρων που εμφανίζονται από τον ίδιο ιστότοπο

Επιπλέον, η Google έχει θέσει ένα όριο στον αριθμό των σελίδων αποτελεσμάτων αναζήτησης που εμφανίζονται από έναν μόνο ιστότοπο. Αυτή η προδιαγραφή είναι κάπως περίπλοκη, αλλά απλοποιώντας τα πράγματα, «ο μέγιστος αριθμός σελίδων που εμφανίζονται από τον ίδιο ιστότοπο είναι δύο».
Τι σημαίνει αυτό; Για παράδειγμα, αν υποθέσουμε ότι υπάρχουν πέντε ερωτήσεις και απαντήσεις (Q&A) στο Yahoo!知恵袋 (Yahoo! Chiebukuro) που αναφέρουν το όνομα μιας εταιρείας ή ενός ατόμου, όταν αναζητήσετε το όνομα αυτής της εταιρείας ή ατόμου στη Google, θα εμφανιστούν μόνο δύο σελίδες από το Yahoo! Chiebukuro στα αποτελέσματα αναζήτησης. Το ίδιο ισχύει και για τα φόρουμ, όπου αν υπάρχουν πέντε νήματα στο 5ちゃんねる (5channel) που περιέχουν ένα συγκεκριμένο κλειδί λέξη, στα αποτελέσματα αναζήτησης της Google θα εμφανιστούν το πολύ δύο.
- Άρθρο για σύλληψη
- Άρθρο για επανασύλληψη
- Άρθρο για καταδίκη
Αν υπάρχουν τρία τέτοια άρθρα σε έναν ίδιο ειδησεογραφικό ιστότοπο, τα αποτελέσματα αναζήτησης της Google θα εμφανίσουν τουλάχιστον ένα από αυτά (3-2=1).
Όταν αναζητάτε ένα συγκεκριμένο κλειδί λέξη και οι σελίδες από τον ίδιο ιστότοπο (για παράδειγμα Yahoo! Chiebukuro, συγκεκριμένο φόρουμ, συγκεκριμένος ειδησεογραφικός ιστότοπος κ.λπ.) εμφανίζονται σε μεγάλο αριθμό στα αποτελέσματα αναζήτησης, αυτό μπορεί να είναι δυσάρεστο για τους χρήστες, επομένως η Google έχει αυτή την προδιαγραφή.
Ωστόσο, αυτή η προδιαγραφή δεν είναι πάντα «εύχρηστη» όταν θέλετε να εξαλείψετε σελίδες που προκαλούν φήμη ζημιάς.
Για παράδειγμα, αν θέλετε να διαγράψετε αρνητικά Q&A από το Yahoo! Chiebukuro μέσω δικαστικής διαδικασίας και κοιτάξετε τα αποτελέσματα αναζήτησης της Google και σκεφτείτε ότι υπάρχουν μόνο δύο στοιχεία προς διαγραφή, μπορεί να καταλήξετε να προχωρήσετε με τη διαδικασία μόνο για να ανακαλύψετε ότι, μετά την επιτυχή διαγραφή, οποιοδήποτε από τα υπόλοιπα τρία (5-2=3) θα εμφανιστεί στα αποτελέσματα αναζήτησης.
Προηγμένη Αναζήτηση στην Google με τη χρήση «Αναζητητικών Εκφράσεων»
Ανάμεσα στα προβλήματα που αναφέρθηκαν παραπάνω, ιδιαίτερα για την επίλυση του τρίτου προβλήματος, απαιτείται η λειτουργία της Google που ονομάζεται «Αναζητητική Έκφραση».
Η Google, πράγματι, έχει θέσει ένα όριο «2 σελίδες ανά ιστότοπο» για τη λειτουργία της παγκόσμιας αναζήτησης, η οποία αναζητά σελίδες που περιέχουν το συγκεκριμένο κλειδί λέξη από όλο το διαδίκτυο. Ωστόσο, χρησιμοποιώντας την «Αναζητητική Έκφραση» με τη μορφή «keyword site:URL του στοχευμένου ιστότοπου», μπορείτε να κάνετε αναζήτηση:
- Μόνο μέσα στα άρθρα του συγκεκριμένου ιστότοπου που έχετε ορίσει
- Στα αποτελέσματα αυτής της αναζήτησης δεν ισχύει το όριο των «2 σελίδων ανά ιστότοπο»
Έτσι, μπορείτε να πραγματοποιήσετε την αναζήτηση.
Οι «Αναζητητικές Εκφράσεις» είναι στην πραγματικότητα πιο περίπλοκες και υπάρχουν επίσης άλλες εκφράσεις που χρησιμοποιούνται για την επίλυση διαφορετικών προβλημάτων.
Ειδικά Μέσα Αναζήτησης για Συγκεκριμένες Ιστοσελίδες
Για παράδειγμα, η Yahoo!知恵袋 (Yahoo! Chiebukuro) διαθέτει μια μοναδική λειτουργία αναζήτησης.
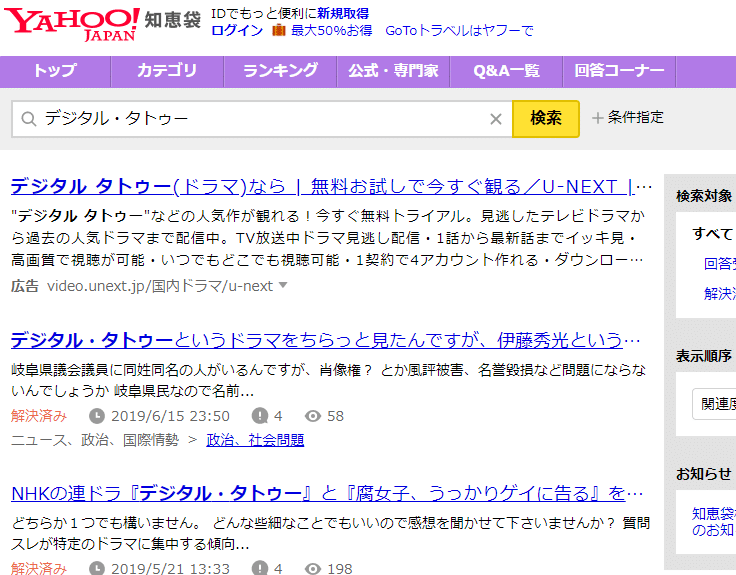
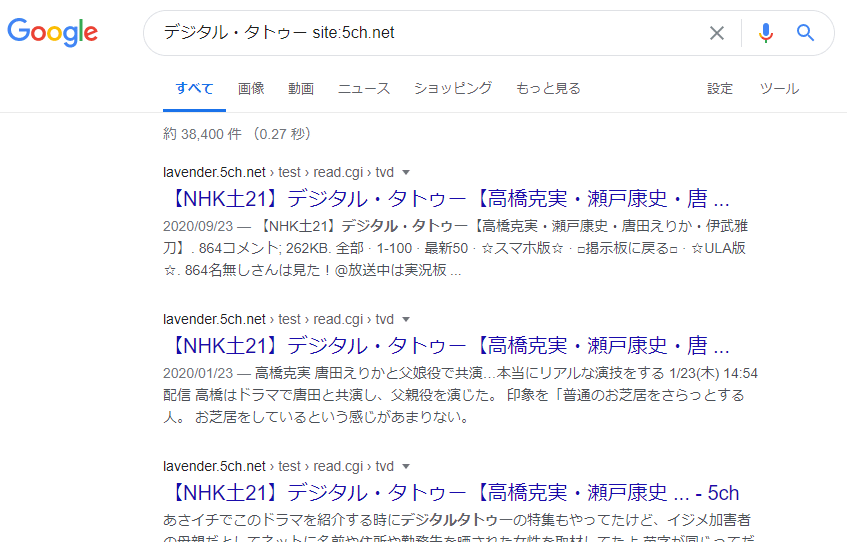
Αυτή η αναζήτηση δεν βασίζεται σε σελίδες που έχει ενδεχομένως ευρετηριαστεί η Google, αλλά στα αποτελέσματα που προκύπτουν από την άμεση αναζήτηση της βάσης δεδομένων της Yahoo!知恵袋 (Yahoo! Chiebukuro) μέσω του δικού της προγράμματος αναζήτησης. Έτσι, αντιμετωπίζεται το πρόβλημα που αναφέρθηκε πρώτα, ότι υπάρχουν ιστοσελίδες που δεν έχουν ακόμη ευρετηριαστεί από την Google. Αυτό σημαίνει ότι, αν χρησιμοποιήσετε τη λειτουργία αναζήτησης της Yahoo!知恵袋 (Yahoo! Chiebukuro), μπορείτε να βρείτε όλες τις σελίδες εντός της χωρίς να παραλείψετε καμία.
Δηλαδή,
Όταν πρόκειται για κάποιο γεγονός (όπως ένα σκάνδαλο εταιρείας, η σύλληψη ενός ατόμου κ.λπ.), και τουλάχιστον οι σελίδες της Yahoo!知恵袋 (Yahoo! Chiebukuro) εντοπίζονται στην παγκόσμια αναζήτηση, η χρήση της εσωτερικής λειτουργίας αναζήτησης της Yahoo!知恵袋 (Yahoo! Chiebukuro) είναι πιο αποτελεσματική από τη χρήση της φράσης αναζήτησης “site:” για τη δημιουργία μιας πλήρους λίστας χωρίς παραλείψεις.
Αυτό ισχύει και για το Twitter. Το Twitter, λόγω της φύσης της υπηρεσίας του, είναι μια ιστοσελίδα όπου συχνά υπάρχουν πολλά tweets σχετικά με γεγονότα που έχουν γίνει θέμα συζήτησης (όπως σκάνδαλα εταιρειών, συλλήψεις ατόμων κ.λπ.). Όχι όλα αυτά τα tweets είναι αναγκαστικά ευρετηριασμένα από την Google, και τουλάχιστον δεν εμφανίζονται όλα στην παγκόσμια αναζήτηση.
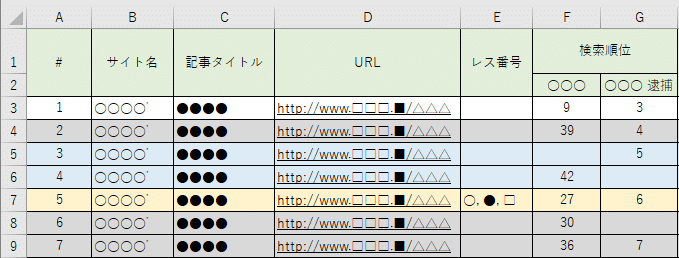
Μέθοδος Καταμέτρησης του Αντικειμένου Διαγραφής «1 Κομμάτι»

Η σχέση μεταξύ της κατάλληλης καταγραφής και των «URL»
Μέχρι στιγμής, έχουμε αναφερθεί στο πώς να συλλέξουμε όσο το δυνατόν περισσότερες ιστοσελίδες (URL) χρησιμοποιώντας την αναζήτηση της Google και άλλες μεθόδους, αλλά αυτό δεν σημαίνει ότι η απλή ποσότητα είναι αρκετή. Αυτό συμβαίνει επειδή το αντικείμενο του αιτήματος διαγραφής δεν είναι πάντα μεμονωμένα «URL».
Στην περίπτωση του 5chan
Αυτό αποτελεί ιδιαίτερο ζήτημα στις ιστοσελίδες τύπου φόρουμ (όπως το 5chan και τα αντίστοιχα αντίγραφα ή άλλα φόρουμ).
Για παράδειγμα, αν αναζητήσουμε ένα συγκεκριμένο λέξη-κλειδί στη Google με τη φράση αναζήτησης «site:5ch.net», μπορεί να εμφανιστούν URL όπως τα παρακάτω στα αποτελέσματα:
- ○○○.5ch.net/test/read.cgi/○○/○○○○/40
- ○○○.5ch.net/test/read.cgi/○○/○○○○/1-100
- ○○○.5ch.net/test/read.cgi/○○/○○○○/30-
Το 5chan επιτρέπει:
- Να εμφανίσει μόνο την απάντηση με τον αριθμό που ακολουθεί το URL του νήματος
- Να εμφανίσει μόνο τις απαντήσεις εντός ενός εύρους αριθμών που ακολουθούν το URL του νήματος, όπως «A-B»
- Να εμφανίσει τις απαντήσεις από έναν αριθμό και μετά που ακολουθούν το URL του νήματος, όπως «A-»
Αυτό σημαίνει ότι αν η λέξη-κλειδί υπάρχει μόνο στην απάντηση με αριθμό 40, διάφορα URL (ιστοσελίδες) μπορεί να εμφανιστούν στα «αποτελέσματα αναζήτησης».
Ωστόσο, όταν κάνουμε αίτημα διαγραφής σε ιστοσελίδες φόρουμ, η μονάδα του αιτήματος είναι, τουλάχιστον καταρχήν, η «απάντηση». Επομένως, αν θέλουμε να διαγράψουμε την απάντηση με αριθμό 40, αρκεί να εξάγουμε μόνο το παρακάτω URL:
- ○○○.5ch.net/test/read.cgi/○○/○○○○/40
και δεν χρειάζεται να καταγράψουμε τα άλλα δύο.
Στην περίπτωση των αντίγραφων και των συνοπτικών ιστοσελίδων του 5chan
Και για να το περιπλέξουμε ακόμη περισσότερο, ακόμα και στο ίδιο το 5chan ή στα αντίγραφα και τις συνοπτικές ιστοσελίδες του, η μονάδα του αιτήματος διαγραφής μπορεί να είναι η «σελίδα (νήμα)» και όχι η «απάντηση». Το «ποια είναι τα αντικείμενα διαγραφής για κάθε ιστοσελίδα» είναι εντελώς θέμα «know-how».
Για αυτό το λόγο,
- Η κατανόηση της νομικής μονάδας για αιτήματα διαγραφής
- Η κατανόηση των προδιαγραφών URL μιας ιστοσελίδας (για παράδειγμα, το 5chan έχει τους παραπάνω περίπλοκους κανόνες)
είναι απαραίτητες για να μπορέσει κανείς να «καταγράψει τα αντικείμενα διαγραφής ενώ παρακολουθεί τα αποτελέσματα αναζήτησης».
Αναζήτηση Εκτός Ανοιχτού Διαδικτύου

Μέχρι στιγμής, έχουμε αναφερθεί σε ιστοσελίδες που η Google θα μπορούσε να εντάξει στον κατάλογο αναζήτησής της, αλλά
- υπάρχουν ιστοσελίδες που η Google δεν θα εντάξει σίγουρα στον κατάλογο,
- οι οποίες ωστόσο πρέπει να ληφθούν υπόψη ως δυνητικοί στόχοι για αιτήματα διαγραφής στο πλαίσιο της διαχείρισης φήμης.
Η Google, λόγω των προδιαγραφών της, δεν συμπεριλαμβάνει στην αναζήτησή της ιστοσελίδες που δεν είναι προσβάσιμες από όλους χωρίς σύνδεση (ανοιχτό διαδίκτυο). Ωστόσο, υπάρχουν υπηρεσίες όπως, για παράδειγμα, πληρωμένες ιστοσελίδες που προσφέρουν τη δυνατότητα αναζήτησης και προβολής παλαιών εκδόσεων εφημερίδων, οι οποίες δεν είναι προσβάσιμες χωρίς εγγραφή χρήστη ή σύνδεση.
Στην περίπτωση διαγραφής αρθρογραφίας σχετικά με συλλήψεις, είναι απαραίτητο να εξετάσουμε και τις παραπάνω βάσεις δεδομένων εφημερίδων. Αυτό συμβαίνει επειδή πολλές εταιρείες που διενεργούν έρευνες για την πίστωση επιχειρήσεων ή ατόμων χρησιμοποιούν αυτές τις βάσεις δεδομένων.
Για περισσότερες λεπτομέρειες σχετικά με τις βάσεις δεδομένων εφημερίδων, δείτε το παρακάτω άρθρο.
Συνοπτικά
Όπως αναφέρθηκε παραπάνω, το να καταρτίσεις μια λίστα με στόχο την αίτηση διαγραφής σελίδων από το διαδίκτυο ως μέτρο αντιμετώπισης της φήμης που έχει υποστεί ζημιά, είναι μια εργασία με πολύ υψηλή εξειδίκευση. Το δικηγορικό μας γραφείο, όταν αναλαμβάνει την αντιμετώπιση τέτοιων ζημιών στη φήμη, πραγματοποιεί την καταρτιση τέτοιων λιστών στόχων, αλλά αυτή η διαδικασία βασίζεται στην εξειδίκευση σε θέματα IT και διαδικτύου.
Στην αντιμετώπιση της φήμης που έχει υποστεί ζημιά στο διαδίκτυο, η διαγραφή σελίδων (ή απαντήσεων σε φόρουμ) είναι μια εργασία που μπορεί να εκτελέσει μόνο ένας δικηγόρος.
Ωστόσο, από την άλλη πλευρά, αυτή η καταρτιση λιστών απαιτεί, όπως εξηγήθηκε συνοπτικά στο άρθρο, πολύ υψηλό επίπεδο γνώσεων σε IT και διαδίκτυο. Αυτό αποτελεί έναν από τους σημαντικούς λόγους για τους οποίους θα πρέπει να αναθέσετε την αντιμετώπιση της φήμης που έχει υποστεί ζημιά σε ένα δικηγορικό γραφείο με υψηλή εξειδίκευση σε IT και διαδίκτυο. Επαναλαμβάνω, αν η καταρτιση της λίστας δεν είναι επαρκής, τότε:
- Ακόμα και αν διαγράψετε όλες τις σελίδες που έχουν καταρτιστεί στη λίστα, μπορεί να εμφανιστούν στα αποτελέσματα παγκόσμιας αναζήτησης άλλες σελίδες που δεν ήταν ορατές κατά την καταρτιση της λίστας, και να απαιτηθεί πρόσθετη διαγραφή, κάτι που θα σημαίνει ότι ο αρχικός προϋπολογισμός ήταν πολύ λανθασμένος
- Στις δικαστικές διαδικασίες, αντί να ολοκληρωθούν σε μία φάση, μπορεί να απαιτηθούν δύο ή τρεις, αυξάνοντας έτσι το κόστος σε υπερβολικά επίπεδα
- Μπορεί να μην αντιληφθείτε την ύπαρξη σελίδων εκτός του ανοιχτού διαδικτύου, όπως ιστοσελίδες βάσεων δεδομένων εφημερίδων, και έτσι, για παράδειγμα, το πρόβλημα της αναζήτησης ενός άρθρου σύλληψης που προκαλεί εμπόδια στην απασχόληση, να μην επιλυθεί
Για αυτούς τους λόγους προκύπτουν τέτοια προβλήματα.
Category: Internet
Related Articles



Ποια είναι η παραγραφή για την αίτηση αποκάλυψης πληροφοριών του αποστολέα; Τρεις παραγραφές που.
Internet

Τι είναι το αντίστροφο ρεβάνς πορνό; Εξηγούμε τα σημεία επικοινωνίας για θύματα, την πρόληψη και.
Internet

Είναι το Χάρτης Κατοικιών ένα έργο πνευματικής ιδιοκτησίας; Εξηγώντας την δίκη της Zenrin του έτ.
Internet