Kan het genereren van 'stemmen' met AI leiden tot auteursrechtschending? (#2 Generatie- & Gebruiksfase)

Door de ontwikkeling van generatieve AI-technologie is het nu mogelijk om de ‘stemmen’ van bestaande zangers en stemacteurs eenvoudig te leren en te genereren. Ook in de zakelijke wereld is het mogelijk geworden om generatieve AI ‘stemmen’ te laten leren en nieuwe ‘stemmen’ te creëren, bijvoorbeeld in app-ontwikkeling, game-ontwikkeling en het maken van animaties.
Het laten leren en genereren van nieuwe ‘stemmen’ door generatieve AI, gebaseerd op de ‘stemmen’ van bestaande zangers en stemacteurs, kan mogelijk een inbreuk op auteursrechten of andere illegale activiteiten vormen. In werkelijkheid is de interpretatie van dergelijke kwesties momenteel nog niet duidelijk vastgesteld.
Hier bespreken we de mogelijkheid van inbreuk op auteursrechten, naburige rechten en publiciteitsrechten in de generatie- en gebruiksfase van generatieve AI. De juridische kwesties in de ontwikkelings- en leerfase worden uitgelegd in dit artikel (#1 Ontwikkelings- en leerfase)[ja]. Wij nodigen u uit om dit ook te raadplegen.
Drie Gebruikspatronen in de Fase van Creatie en Gebruik
Wanneer we spreken over ‘het genereren van stemmen met AI’, moeten we dit proces in twee fasen onderverdelen:
- De ontwikkelings- en leerfase
- De creatie- en gebruiksfase
Fase 1 wordt uitgevoerd door AI-ontwikkelaars, terwijl fase 2 gewoonlijk wordt uitgevoerd door AI-gebruikers.
Als we deze processen visualiseren, ziet het er als volgt uit:
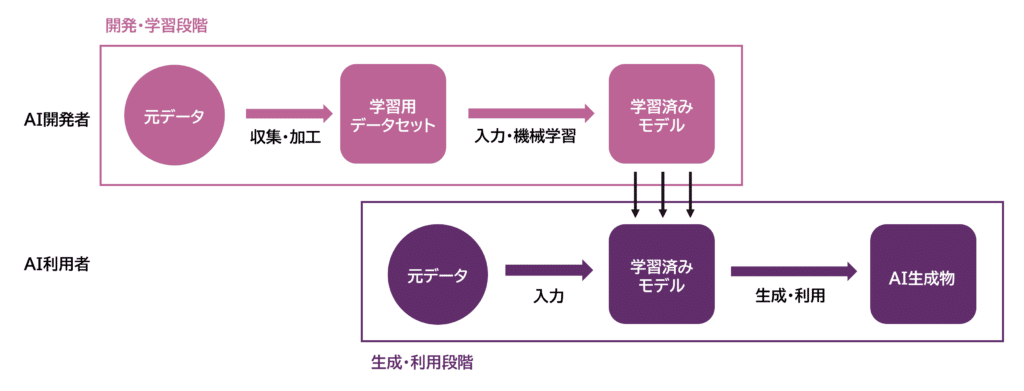
Tijdens de ontwikkelings- en leerfase verzamelen en accumuleren we oorspronkelijke stemgegevens van mensen als leerdata voor AI-ontwikkeling en creëren we een dataset voor training. Vervolgens voeren we machine learning uit met deze dataset om een getraind model te ontwikkelen. Dit wordt normaal gesproken gedaan door AI-ontwikkelaars.
In de creatie- en gebruiksfase voeren we de oorspronkelijke gegevens in een AI die klaar is met machine learning om AI-gegenereerde producten te creëren en te gebruiken. Dit wordt gewoonlijk uitgevoerd door AI-gebruikers.
Er zijn drie mogelijke gebruikspatronen in de creatie- en gebruiksfase:
- Patroon 1: Het invoeren van menselijke stemmen in AI om AI-gegenereerde producten te creëren die verschillen van de oorspronkelijke stemgegevens
- Patroon 2: Het invoeren van menselijke stemmen in AI om AI-gegenereerde producten te creëren die identiek of vergelijkbaar zijn met de oorspronkelijke stemgegevens
- Patroon 3: Het invoeren van niet-stemgegevens in AI om AI-gegenereerde producten te creëren die identiek of vergelijkbaar zijn met de stemgegevens van een bestaand persoon
Hieronder volgt een korte uitleg over hoe elk van deze gebruikspatronen mogelijk inbreuk kan maken op rechten.
Patroon 1: Menselijke stemmen invoeren in AI om verschillende output te genereren

Eerst zullen we de mogelijke inbreuken op rechten bespreken die kunnen voorkomen wanneer men menselijke stemmen invoert in AI om een output te genereren die verschilt van de ingevoerde stemgegevens.
De relatie met auteursrechten
Specifiek bij patroon 1 kunt u zich een situatie voorstellen waarbij de stemgegevens van een bepaalde zanger worden ingevoerd in een AI die stemmen kan identificeren, of waarbij de stem van een bepaalde zanger en de stem van een AI-gebruiker tegelijkertijd worden ingevoerd om een zangstem te genereren die lijkt op die van de betreffende zanger.
In relatie tot auteursrechten wordt het invoeren van bestaande werken in AI problematisch. Deze handeling valt onder ‘informatieanalyse’ (Artikel 30-4, lid 2 van de Auteursrechtwet (hierna “de wet” genoemd)) en is daarom toegestaan binnen de grenzen die noodzakelijk worden geacht voor dergelijke informatieanalyse. Daarom, als de informatieanalyse noodzakelijk is, wordt het gebruik van auteursrechtelijk beschermde werken binnen de erkende grenzen niet beschouwd als een inbreuk op het auteursrecht.
De relatie met naburige rechten
In relatie tot naburige rechten wordt Artikel 102 toegepast, wat betekent dat de bepalingen van Artikel 30-4 van de auteursrechten ook van toepassing zijn. Daarom vormt de bovengenoemde invoerhandeling in principe geen inbreuk op naburige rechten.
De relatie met publiciteitsrechten
In het geval van patroon 1, laten we aannemen dat de stem die wordt ingevoerd die van een bepaalde beroemdheid is. Als de stemgegevens van een specifieke beroemdheid worden gebruikt, kan dit, zoals uitgelegd in Deel 1 (Ontwikkeling & Leerfase)[ja], een inbreuk op publiciteitsrechten vormen en daarmee een onrechtmatige daad zijn als het valt onder een van de drie besproken inbreuktypes.
In dit geval, zelfs als de ingevoerde stemgegevens die van een specifieke beroemdheid zijn, blijft de handeling beperkt tot het invoeren en analyseren van de stemgegevens door de genererende AI, en valt het dus niet onder de drie besproken inbreuktypes.
Daarom kan worden gesteld dat er geen ruimte is voor inbreuk op publiciteitsrechten in deze gebruikshandeling.
Patroon 2: Menselijke stemmen invoeren in AI om identieke of vergelijkbare data te genereren
Patroon 2 houdt in dat je specifieke zangstemdata van een zanger, samen met de songteksten en melodiegegevens, invoert om zangstemdata te genereren die met de stem van die zanger de betreffende songteksten en melodie zingt. Dit kan grofweg in de volgende drie stappen worden verdeeld:
- Het invoeren van stemdata in AI
- Het genereren van AI-creaties op basis van deze data
- Het gebruik van de gegenereerde AI-creaties
Met deze stappen als uitgangspunt analyseren we de relatie met de volgende rechten:
De relatie met auteursrechten
Allereerst, wat betreft de relatie met auteursrechten, kunnen alle drie de stappen – invoeren, genereren en gebruiken – mogelijke auteursrechtinbreuken vormen.
Om te beginnen met stap 1, het invoeren. Net als bij patroon 1, valt het invoeren van data in principe niet onder auteursrechtinbreuk volgens artikel 30-4. Echter, er is een belangrijke uitzondering op deze regel. Als het doel van het genereren van AI-creaties is om essentiële kenmerken van de originele expressie te behouden (met als doel expressie-output), dan is artikel 30-4 niet van toepassing en wordt het als illegaal beschouwd. In het geval van patroon 2 wordt vaak bevestigd dat er een doel voor expressie-output is, wat betekent dat de kans op auteursrechtinbreuk hoog is.
Vervolgens stap 2, het genereren. In het geval van patroon 2 worden data gegenereerd die identiek of vergelijkbaar zijn met bestaande auteursrechtelijk beschermde stemdata, wat een inbreuk op het reproductierecht (artikel 21) vormt. Daarom is de kans op auteursrechtinbreuk hoog.
Ten slotte stap 3, het gebruik. Het gebruik van de in stap 2 gegenereerde data die identiek of vergelijkbaar zijn met bestaande auteursrechtelijk beschermde werken, vormt een inbreuk op het reproductierecht (artikel 21) of het recht op openbare mededeling (artikel 23). Daarom is de kans op auteursrechtinbreuk hoog.
De relatie met naburige rechten
Wat betreft de relatie met naburige rechten, zijn er nog onzekere en complexe kwesties die in de praktijk moeten worden onderzocht.
In de huidige situatie wordt artikel 30-4, dat betrekking heeft op auteursrechten, bij analogie toegepast volgens artikel 102, dus de kans op inbreuk op naburige rechten is in principe laag.
De relatie met publiciteitsrechten
Bij de stappen 1 tot en met 3, is er voor het invoeren in stap 1 en het genereren in stap 2 vrijwel geen ruimte voor inbreuk op publiciteitsrechten, aangezien deze niet vallen onder de drie typen van inbreuk.
Echter, wat betreft het gebruik in stap 3, als de manier van gebruik commerciële verkoop of soortgelijk commercieel gebruik betreft, dan valt dit wel onder de drie typen van inbreuk, waardoor de kans op inbreuk op publiciteitsrechten hoog is.
Patroon 3: Niet op menselijke stemdata gebaseerde gegevens invoeren in AI om identieke of soortgelijke stemdata van bestaande personen te genereren

De relatie met auteursrechten
Patroon 3 betreft bijvoorbeeld het invoeren van de naam van een specifieke stemacteur om vervolgens AI-gegenereerde spraakdata van die stemacteur te creëren. De vraag is of het AI-gegenereerde werk afhankelijkheid vertoont ten opzichte van bestaande auteursrechtelijk beschermde werken.
De conclusie is dat, wanneer een AI-gebruiker met de intentie om identieke of soortgelijke AI-gegenereerde werken te produceren, bewust gebruikmaakt van bestaande auteursrechtelijk beschermde werken, er sprake is van afhankelijkheid. Dit is de heersende opvatting.
Bijvoorbeeld, als een AI-gebruiker met het doel om de stem van een bepaalde stemacteur te repliceren, een AI-gegenereerd werk produceert, valt dit hieronder. Daarom is in dergelijke gevallen de kans op schending van auteursrechten groot.
De relatie met naburige rechten
Zelfs als AI wordt gebruikt om een uitvoering identiek of soortgelijk aan een bestaande uitvoering te genereren, wordt deze handeling niet beschouwd als een ‘opname’ van de bestaande uitvoering, en daarom is er geen sprake van inbreuk op naburige rechten.
De relatie met publiciteitsrechten
Wat betreft publiciteitsrechten, ontstaan er problemen wanneer de gegenereerde stem commercieel wordt gebruikt. In de praktijk zijn er veel gedetailleerde scenario’s denkbaar, maar het is voldoende om alleen de conclusie te begrijpen.
De conclusie is dat wanneer een AI-gebruiker met de intentie om een stem identiek of soortgelijk aan die van een bepaalde beroemdheid te genereren en te gebruiken, dit doet, er sprake is van inbreuk op publiciteitsrechten. Voor gevallen waarin dit onbedoeld gebeurt, is de situatie complex en is er in de praktijk nog veel ruimte voor discussie, dus dat laten we hier buiten beschouwing.
Conclusie: Raadpleeg een expert over de relatie tussen generatieve AI en auteursrechten
Tot dusver hebben we de juridische rechten van de menselijke stem besproken en de handelingen die problematisch kunnen zijn wanneer deze rechten worden gebruikt, aan de hand van specifieke voorbeelden.
Wat betreft de juridische rechten van de menselijke stem, is het belangrijk om onderscheid te maken tussen ‘inhoud’ en ‘geluid’, en om rekening te houden met auteursrechten, naburige rechten en publiciteitsrechten.
Bij de handelingen die problematisch kunnen zijn, moeten we ons richten op wat precies het probleem vormt. Wat betreft het genereren van stemmen met behulp van generatieve AI, zijn er zowel in de praktijk als in de zakenwereld diverse discussies gaande. Wanneer u een nieuw bedrijf start, is het belangrijk om de bovenstaande punten in acht te nemen en zorgvuldig gebruik te maken van generatieve AI.
Gerelateerd artikel: Kan het genereren van een ‘stem’ met AI leiden tot auteursrechtinbreuk? (#1 Ontwikkeling & Training fase)[ja]
Maatregelen van ons kantoor
Monolith Advocatenkantoor is een juridische firma met uitgebreide ervaring in zowel IT, met name het internet, als in de rechtspraktijk. In de recente jaren hebben generatieve AI en intellectuele eigendomsrechten rond auteursrecht steeds meer aandacht gekregen, waardoor de noodzaak voor juridische controle blijft toenemen. Ons kantoor biedt oplossingen met betrekking tot intellectueel eigendom. De details vindt u in het onderstaande artikel.
Expertisegebieden van Monolith Advocatenkantoor: IT- en intellectueel eigendomsrecht voor diverse ondernemingen[ja]
Category: IT




















