Az 'aguse.jp'-n keresztül vizsgáljuk a saját domain webhely szerverkezelőjét

Az úgynevezett saját domainen működő weboldalakon található cikkekkel kapcsolatban, ha törlési vagy a szerző IP-címének közzétételét kérjük, a kérelmek címzettjei nagyjából a következők lehetnek:
- Az oldal üzemeltetője (gyakran megegyezik a domain regisztrálójával)
- A web szerver adminisztrátora
Ez két lehetőség közül választhatunk. Például, ha törlési kérelmet nyújtunk be:
- Az oldal üzemeltetőjének kérhetjük, hogy “A Ön által üzemeltetett oldalon rágalmazás áldozata lettem, kérjük törölje a cikket”
- A web szerver adminisztrátorának kérhetjük, hogy “A Ön által kezelt szerveren hosztolt oldalon rágalmazás áldozata lettem, kérjük törölje a cikket”
Ez a helyzet. Az interneten található cikkek törlésének kérelmezője egyszerűen fogalmazva:
- Rendelkezik a cikk törlésének jogával
- A cikk interneten történő közzétételében jelentős mértékben részt vesz, és jogilag kötelező a cikk törlése
Ezt tehetjük az ilyen személyekkel szemben, és az oldal üzemeltetője és a web szerver adminisztrátora mindkettő ebbe a kategóriába tartozik. Az IP-cím közzétételének kérelme is, bár a logikai struktúra eltér, ugyanazt a következtetést vonja maga után.
Mit jelent a “webszerver adminisztrátorának vizsgálata”
De ki is pontosan az a “webszerver adminisztrátor”, aki egy saját domain névvel működő weboldalt kezel? Például, ki az a személy a mi weboldalunkon (a Monolis Jogi Iroda weboldala) esetében?
A saját domain névvel működő weboldalak esetében, a weboldalt kezelő webszerver adminisztrátorának azonosítására, az “aguse.jp” nevű webes szolgáltatást használva, bemutatjuk a vizsgálati módszert.
A weboldal üzemeltetőjének és a domain regisztrálójának vizsgálata
Ahogy azt a bevezetőben is említettük, legyen szó cikk törlési kérelméről vagy IP-cím közzétételi kérelméről, ha a weboldal üzemeltetője ismert, akkor lehetséges a kérelmet közvetlenül az üzemeltetőhöz intézni. Egyedi domain esetén a weboldal üzemeltetője általában megegyezik a domain regisztrálójával. Az egyedi domain regisztrálójával kapcsolatos információkat pedig a “whois” rendszer segítségével lehet vizsgálni. Ezt a módszert egy másik cikkben részletesen ismertetjük.
https://monolith.law/reputation/ansi-whois-howto[ja]
Web szerver adminisztrátorok vizsgálati módszerei
Sok esetben az egyedi domain névvel rendelkező weboldalakat úgynevezett bérelt szerverek segítségével üzemeltetik. Az “egyedi domain névvel rendelkező weboldalak” létrehozása nagyjából a következő lépésekből áll:
- Elsőként, egyedi domain nevet szereznek be olyan domain regisztrációs szolgáltatásoktól (domain regisztrátoroktól), mint a “onamae.com” vagy a “GoDaddy”.
- Második lépésként, szerződést kötnek egy bérelt szerver szolgáltatóval, mint például a “Sakura Internet”, és biztosítanak egy web szervert, ahol a weboldalukat tárolják.
- Végül, beállítják, hogy az adott domain URL-jére történő hozzáférés esetén a felhasználó a megfelelő web szerverhez kapcsolódjon.
Ez a folyamat a weboldalak létrehozásának.
Az “aguse.jp” használata
Ezután, a webes szerverek vizsgálatához, a széles körben használt “aguse.jp” nevű webes szolgáltatást fogjuk használni.
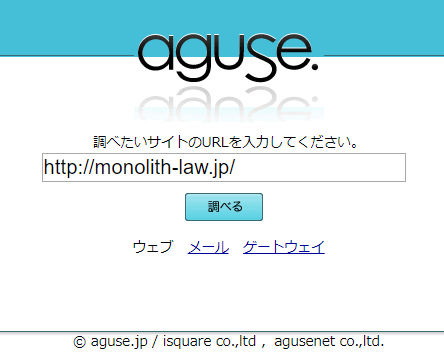
Az “aguse.jp” használata egyszerű. Először is, a kezdőlapon be kell írni a vizsgálandó URL-t. Ebben az esetben a szükséges információ a URL
http://www.Monolith-law.jp/article/index.html
“www.Monolith-law.jp” részéig van. Ezt a részt “hosztnév”-nek hívjuk.
A fenti példában, az “/article” alatti rész a weboldal helyét jelöli a szerveren, és nem szükséges a szerver azonosításához. Másrészről, a “www” rész a “szubdomain”, amelyet bármennyi létrehozhatunk egy egyedi domainen (Monolith-law.jp) belül, de ha a szubdomainek különböznek, akkor lehetséges, hogy a webszerverek is különböznek. Tehát, ha például,
https://monolith-law.jp
http://www2.Monolith-law.jp
http://blog.Monolith-law.jp
van több szubdomain, akkor lehetséges, hogy minden egyes szubdomainhez külön webszerver tartozik. Ez eltér a “whois” használatával végzett domain regisztrációs információk vizsgálatától.
Az “aguse.jp” vizsgálati eredmények oldalának olvasása
Ha a “Vizsgálat” gombra kattint, megjelenik a vizsgálati eredmények oldala.
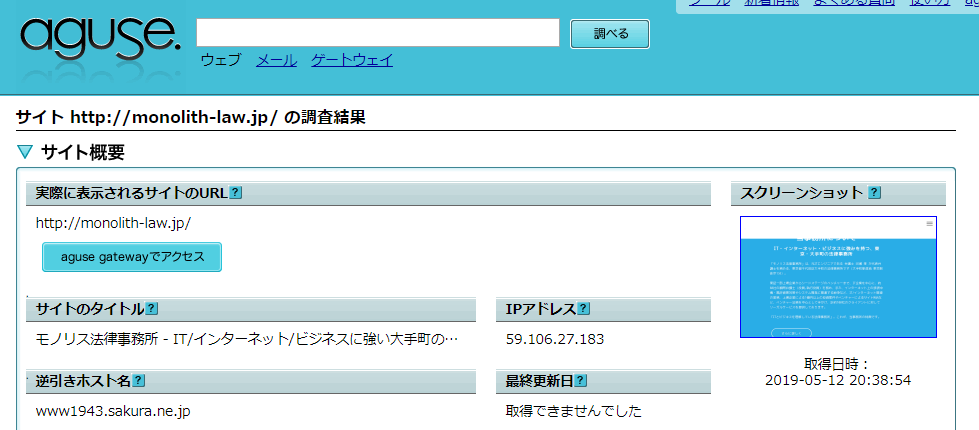
A “Fordított keresésű hosztnév” a weboldalt tároló webszerver “hosztnév”-ét mutatja.
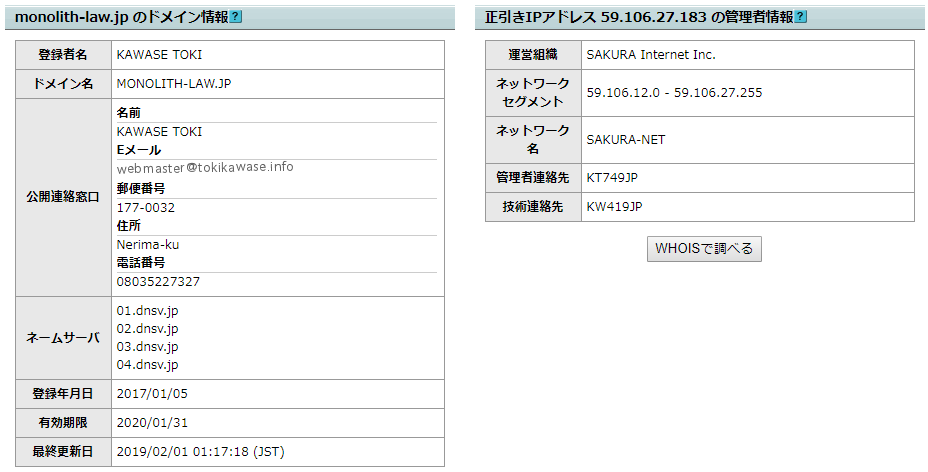
És a “Normál keresésű IP-cím ●●.●●.●●.●● adminisztrációs információi” a webszerver adminisztrációs adatait jeleníti meg.
Az adminisztrátorok vizsgálatának módszere
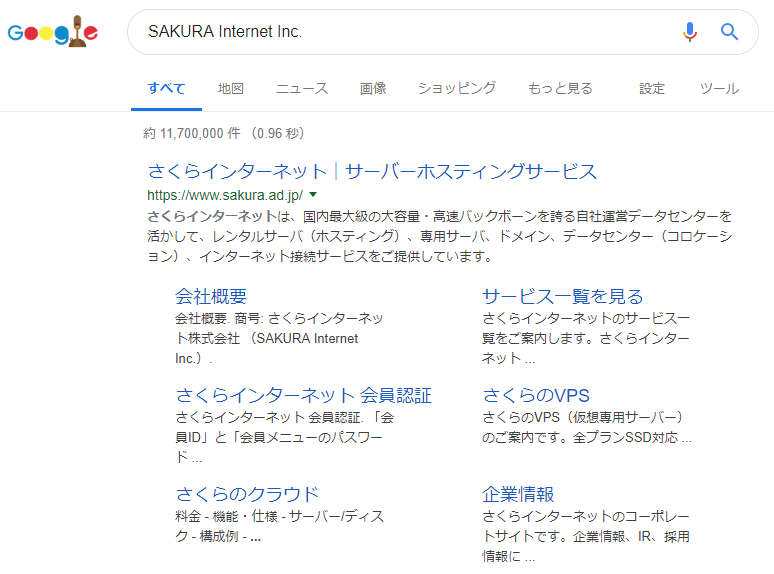
Ha a itt megjelenő szöveget beírja a Google keresőbe, képes lesz azonosítani a web szerver adminisztrátorát. Ebben az esetben kiderült, hogy a “Sakura Internet Inc.” kezeli a “www.Monolith-law.jp” weboldalt.
Hogyan végez kutatást az “aguse.jp”?
Az “aguse.jp” webes szolgáltatás használata alapvetően a fent említett módon történik, de ebben a pillanatban milyen technikai folyamatok zajlanak, és miért képesek ezzel a módszerrel megerősíteni a saját domain névvel rendelkező weboldalak szervereinek adminisztrátori adatait, ezt részletesebben is elmagyarázzuk. Végül is, ha nem értjük, hogy “mit csinálnak”, akkor képtelenek leszünk kezelni a legkisebb kivételes eseteket is.
“IP-cím” az internetes cím
Először is, a történetünk az “IP-cím” fogalmával kezdődik. Az IP-cím, amelyet “az internet címeként” is emlegetnek, az az információ, amelyet minden, az internethez csatlakoztatott gép (elvileg) egyedülállóan birtokol. Például, amikor ezt a weboldalt mobiltelefonon böngészed, a mobiltelefonodnak is van saját IP-címe.
És ahogyan a weboldalt böngésző eszköz (pl. mobiltelefon) rendelkezik saját IP-címmel, ugyanúgy a weboldal, illetve annak tárhelyszolgáltatója, a webszerver is rendelkezik saját IP-címmel. Az interneten lévő gépek közötti kommunikáció, például a “Monolith Ügyvédi Iroda weboldalának mobiltelefonon történő böngészése”, mindig az egyedi IP-címmel rendelkező gépek között zajlik.
Az IP-cím ●●.●●.●●.●●-es mobiltelefon és a
IP-cím ●●.●●.●●.●●-es webszerver között
weboldal adatokat cserélnek
Ez az, amit “weboldalak böngészése az interneten” alatt értünk.
Az “URL” és a “web szerver IP címe” kapcsolata
Ám általában, amikor az interneten böngészünk, nem vagyunk tudatában annak, hogy a megtekinteni kívánt weboldal (pontosabban a weboldalt tároló web szerver) IP címe mi. Az IP cím alapú kommunikáció főként okostelefonok és egyéb eszközök belső működésében játszik szerepet, a felhasználók pedig nem szoktak tudatában lenni az “IP cím” fogalmának. Helyette a felhasználók az URL-t szokták észben tartani.
https://monolith.law/article/index.html
A felhasználók tehát az URL-t figyelembe véve böngésznek az interneten. Amikor a felhasználó megpróbálja megnyitni a fentihez hasonló URL-t, az okostelefon vagy más eszköz a következő lépéseket végzi el:
- Elsőként megvizsgálja az adott URL (vagyis a weboldalt tároló web szerver) IP címét
- Majd ezzel az IP címmel lép kapcsolatba
Ez a folyamat zajlik le a háttérben.
Mit jelent a “forward lookup” a hostnév esetében
A fent említett 1. folyamat, vagyis a URL (pontosabban a URL “www.Monolith-law.jp” része, amit “hostnévnek” hívunk) IP-címre történő átalakítását nevezzük “forward lookup”-nak.
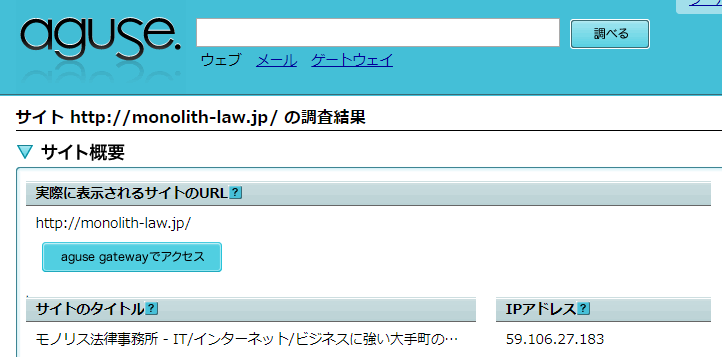
Amikor az “aguse.jp”-n keresztül vizsgáljuk a URL-t, az “IP-cím” alatt megjelenő információ az a IP-cím, amelyet a megfelelő URL (pontosabban annak hostnév része) “forward lookup” segítségével kaptunk.
Mi az IP-cím “fordított lekérdezése”?
A “normál lekérdezés” ellentéte, vagyis az IP-címek hosztnévvé történő átalakítását nevezzük “fordított lekérdezésnek”.
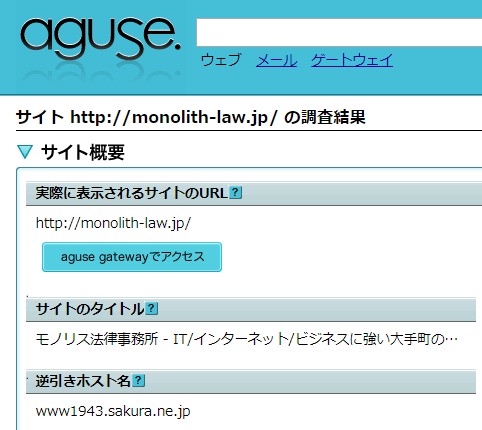
Az “aguse.jp” “fordított lekérdezésű hosztnév” megjelenítése a következő:
- Az URL-t (a hosztnév részét) egyszer normálisan lekérdezzük
- majd ezt fordítottan lekérdezzük, és előjön a hosztnév
Ez van itt.
A bonyolult rész itt az, hogy ha a “normál lekérdezés → fordított lekérdezés” folyamatot végrehajtjuk, akkor az egyedi domain oldalak esetében a bérelt szerver hosztneve jelenik meg. Ez a mechanizmus kissé bonyolult, de alább egyszerűen elmagyarázom.
Mi az a “névszerver”
Először is, a “fordított lekérdezés” nem feltétlenül szükséges az internet használatához. Ahogy azt fentebb is említettük, a normál internetes böngészés során a “URL alapján a webszerver IP-címének lekérdezése”, azaz a “normál lekérdezés” megtörténik, de a “fordított lekérdezés” nem jelenik meg a normál internetes böngészés (vagy a normál internetes kommunikáció) során. És ez a “normál lekérdezés” a “névszerver” nevű eszközt használja.
- Először is, megvizsgálja az URL (a weboldalt tároló webszerver) IP-címét
- Kommunikációt folytat az IP-címmel
Az 1. pontban történő tevékenység pontosabban:
- A névszerverhez fordul, hogy megkérdezze az általa elérni kívánt URL-t (a weboldalt tároló webszerver hosztneve)
- A névszerver válaszol az URL (a weboldalt tároló webszerver hosztneve) IP-címével
Ez a folyamat. Tehát a névszerver tulajdonképpen egy szótárként tartalmazza a “hosztnév és a hozzá tartozó IP-cím” hozzárendelési információkat.
“Névszerver” és “Gyökér névszerver”
A névszerverek számtalanul léteznek az interneten. A fent említett lekérdezési folyamatok nagy mennyiségben történnek a netezés során, és ha például “az egész internetre vonatkozóan egyetlen névszerver válaszolna minden lekérdezésre”, akkor a szerver terhelése óriási lenne. Ezért a névszerverek számtalanul léteznek, és ezeket egy “gyökér névszerver”, a névszerverek mesterének kiindulópontjától kezdve helyezik el a fastruktúrában. “A gyökér névszerver alatt vannak a névszerverek (például A, B), és a névszerver A alatt vannak más névszerverek (például C, D)…” és így tovább.
Az interneten lévő számtalan névszerver esetében ideális lenne, ha mindegyik mindig ugyanazt a szótári információt tartaná, de ha ezt megpróbálnánk megvalósítani, a szinkronizációs munka is óriási terhelést jelentene. Ezért a gyakorlatban nem történik meg a teljes szinkronizáció. “Valahol a fastruktúrában lévő névszerveren van információ, és ha van valahol információ, akkor ha sorban lekérdezzük, előbb-utóbb választ kapunk” – ez a rendszer működési elve.
Mi az az “IP-cím fordított lekérdezése”?
A “fordított lekérdezés” során a gyökér névszerverről más névszerverekhez továbbított lekérdezések történnek. Ez az a fajta lekérdezés, ami ellentétes a szokásos lekérdezéssel (a normál lekérdezés során), és azt kéri, hogy “adja meg a ●●.●●.●●.●● IP-címhez tartozó hosztnév válaszát”. A lekérdezésre adott válasz többnyire a weboldalt hosztoló webszerverrel kapcsolatos karakterlánc lesz. A fenti példában:
- Ha a “Monolith-law.jp” hosztnév “normál lekérdezését” végezzük, a válaszként kapott IP-cím “59.106.27.183”
- Ha a “59.106.27.183” IP-címet “fordított lekérdezéssel” kérdezzük le, a válaszként kapott hosztnév (nem a “Monolith-law.jp”, hanem) a “www1943.sakura.ne.jp”
lesz.
És a “weboldalt hosztoló webszerverrel kapcsolatos” hosztnév a bérelt szerver esetében tartalmazza a bérelt szerver szolgáltató által birtokolt domént, a fenti példában a “sakura.ne.jp”-t.
A bérelt szerver szolgáltatók domainjének whois információi
A bérelt szerver szolgáltatók többnyire helyes információkat regisztrálnak a whois-ba.
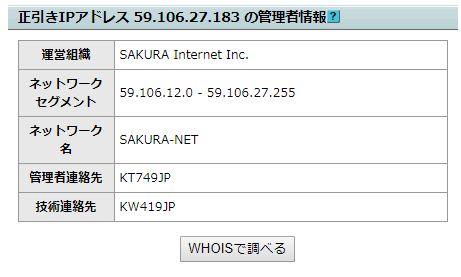
Ezért, ha ezt a domain nevet a “whois”-ben keresi, megszerezheti a bérelt szerver szolgáltatójának információit. A fenti példában, megtudhatja, hogy az “üzemeltető szervezet” a “SAKURA Internet Inc.”
Összefoglalás
Ahogy látható, egy olyan weboldal vizsgálata, amely saját domainen működik, és amelynek törlését vagy IP-címének közzétételét kérjük, és amelynek hosting szerverét egy bérelt szerver szolgáltató kezeli, rendkívül bonyolult IT-szempontból. Ebben a cikkben csak az “alapokat” tárgyaltuk, és ha olyan probléma merül fel, amelyet az alapvető ismeretekkel nem lehet megoldani, akkor a probléma megoldásának módja lesz az “alkalmazás”.
Az internetes hírnévkezelés, mint látható, rendkívül szakmai mind az IT, mind a jogi szempontból.
Category: Internet
Related Articles


A jogi kockázatok, amikor jutalmat fizetünk a szépségsebészeti véleményeket íróknak a véleményol.
Internet


Meddig engedélyezett a védjegyek hasonlósága? A hasonlóság kritériumainak és a védjegyjog megsér.
Internet
















