Menguraikan Metode Penelitian Artikel Negatif di Internet sebagai Prasyarat untuk Manajemen Risiko Reputasi

Dalam kasus membersihkan halaman web yang berhubungan dengan skandal perusahaan masa lalu, insiden viral, penangkapan, atau catatan kriminal, langkah pertama yang harus dilakukan adalah “mendaftar semua halaman dan postingan negatif tanpa ada yang terlewat”. Jika Anda tidak dapat membuat daftar ini, Anda tidak akan dapat melanjutkan langkah-langkah manajemen risiko reputasi sambil melihat volume keseluruhan, dan misalnya, dalam hal prosedur pengadilan seperti injungsi sementara atau pengadilan, Anda mungkin perlu melakukannya dua kali karena Anda melewatkan sesuatu, yang seharusnya diselesaikan dalam satu kali.
Namun, mendaftar semua halaman web dan postingan yang mencantumkan fakta tertentu (misalnya skandal perusahaan, insiden viral, penangkapan, atau catatan kriminal) di internet bukanlah tugas yang “mudah”. Bagian ini memerlukan keahlian yang sangat tinggi dan tidak dapat dilakukan tanpa pengetahuan khusus.
Kantor hukum Monolith adalah kantor hukum yang memiliki keahlian dalam manajemen risiko reputasi, dengan staf yang ahli dalam penelitian internet seperti pengacara utama yang merupakan mantan insinyur IT. Berikut ini adalah penjelasan tentang bagaimana penelitian internet harus dilakukan.
Apa itu Hasil Pencarian Google dan Batasannya?
Dasar dari penelitian online adalah, tentu saja, pencarian Google. Namun, dalam hasil pencarian Google, ada batasan dalam tiga aspek ketika Anda mencari kata kunci yang Anda inginkan, misalnya dalam kasus penghapusan artikel penangkapan, dengan mencari kata kunci seperti “nama Anda ditangkap”.
Halaman Web yang Menjadi Target Pencarian Google
Di internet, ada ‘tak terhitung’ jumlah halaman web. Meskipun secara teoritis tidak mungkin untuk mengukur jumlah total halaman web di internet, ada pendapat yang mengatakan bahwa jumlah ‘situs web’ saat ini adalah sekitar 1,8 miliar.
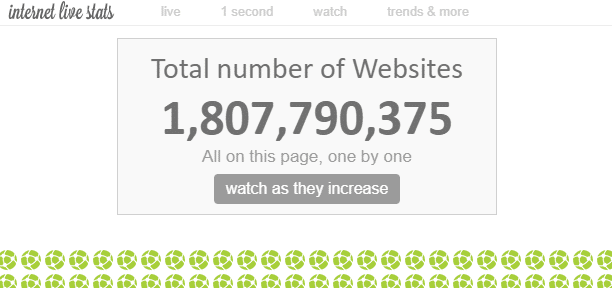
Mengingat bahwa ada beberapa halaman web dalam satu situs web, jumlah halaman web pasti jauh lebih banyak dari itu.
Dan pencarian Google, untuk menyederhanakannya, dilakukan dengan cara:
- Bot Google (Googlebot) menjelajahi internet, mendeteksi halaman web baru yang dapat dibuka dengan mengikuti tautan dari halaman web yang sudah diketahui
- Memahami konten halaman tersebut (pendaftaran indeks)
- Menampilkan halaman tersebut dalam hasil pencarian ketika pencarian dilakukan dengan kata kunci yang terdapat dalam halaman tersebut
Yang ingin saya katakan adalah, halaman web yang ditampilkan dalam pencarian Google adalah halaman web yang telah diindeks oleh Google ‘seperti di atas’, bukan ‘semua halaman web’. Dengan kata lain, selama Anda menggunakan pencarian Google, Anda tidak dapat menemukan ‘halaman web yang belum diindeks oleh Google’, dan tidak ada cara untuk mencari semua halaman web di internet tanpa melewatkan satu pun.
“Halaman Web yang ‘Mirip’ Dikeluarkan dari Hasil Pencarian”
Google tidak menampilkan “semua halaman web yang berisi kata kunci pencarian dan telah terdaftar di indeks” dalam hasil pencariannya. Ini mungkin sesuatu yang Anda sadari saat menggunakan pencarian Google secara normal. Ini adalah pesan yang ditampilkan di halaman terakhir hasil pencarian, “Untuk menampilkan hasil pencarian yang paling akurat, halaman yang mirip dengan ○ di atas telah dikeluarkan.”
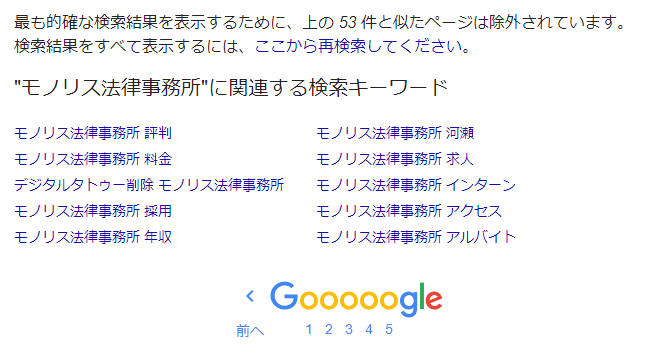
Misalnya,
- Berita tertentu disiarkan pertama kali di situs berita besar
- Berita tersebut kemudian diterbitkan ulang di layanan yang merangkum artikel berita
- Berita tersebut juga diterbitkan ulang di situs pribadi dan sejenisnya
Dalam kasus seperti ini, jika halaman dengan konten yang sama memenuhi hasil pencarian, ini akan sulit digunakan oleh pengguna, jadi Google secara otomatis mengeluarkan “halaman yang mirip”, dalam kasus ini 2 dan 3, dari hasil pencarian.
Ini bukanlah fitur yang selalu “mudah digunakan” jika Anda ingin “menghilangkan halaman yang merusak reputasi”. Misalnya, jika “berita tertentu” di atas adalah artikel tentang penangkapan Anda di masa lalu,
Hanya “1. Artikel asli dari situs berita besar” yang ditampilkan dalam hasil pencarian, jadi ketika Anda menghapus hanya halaman itu, “2. Artikel yang diterbitkan ulang di layanan yang merangkum artikel berita” muncul dalam hasil pencarian Google karena 1 telah dihapus
Ini adalah situasi yang mungkin terjadi.
Masalah ini dapat diselesaikan dengan mengklik bagian “Untuk menampilkan semua hasil pencarian, cari lagi dari sini” yang ditampilkan di atas, tetapi jika Anda tidak mengetahui fitur atau fungsi ini, Anda mungkin “melewatkan” halaman yang merusak reputasi.
Ada batas maksimum untuk jumlah artikel yang ditampilkan dari satu situs yang sama

Selain itu, Google menetapkan batas maksimum untuk jumlah halaman hasil pencarian yang ditampilkan dari satu situs web. Spesifikasi ini sedikit rumit, tetapi untuk menyederhanakannya, “maksimum 2 halaman ditampilkan dari satu situs yang sama”.
Artinya, misalnya, meskipun ada 5 Q&A di mana nama perusahaan atau individu muncul di dalam Yahoo! Chiebukuro, dalam hasil pencarian Google untuk nama perusahaan atau individu tersebut, maksimum 2 halaman dari Yahoo! Chiebukuro akan ditampilkan. Hal yang sama berlaku untuk forum, meskipun ada 5 thread 5chan yang berisi kata kunci tertentu, maksimum 2 thread akan ditampilkan dalam hasil pencarian Google. Misalnya, jika seseorang memiliki,
- Artikel tentang penangkapan
- Artikel tentang penangkapan kembali
- Artikel tentang vonis bersalah
dan ada 3 artikel di situs berita yang sama, setidaknya satu dari mereka (3-2=1) tidak akan ditampilkan dalam hasil pencarian Google.
Ketika mencari kata kunci tertentu, jika banyak halaman dari situs yang sama (misalnya Yahoo! Chiebukuro, forum tertentu, situs berita tertentu, dll.) muncul dalam hasil pencarian, ini akan menjadi tidak nyaman bagi pengguna, jadi Google memiliki spesifikasi ini.
Namun, spesifikasi ini juga tidak selalu “mudah digunakan” ketika Anda ingin “membersihkan halaman dengan reputasi buruk”.
Misalnya, jika Anda ingin menghapus Q&A negatif dari Yahoo! Chiebukuro melalui prosedur pengadilan, dan Anda melihat hasil pencarian Google dan memutuskan bahwa “hanya ada 2 target” dan melanjutkan prosedur, ketika penghapusan berhasil, salah satu dari 3 sisa (5-2=3) akan ditampilkan dalam hasil pencarian.
Pencarian Google Lanjutan Menggunakan “Query”
Dari masalah-masalah yang telah disebutkan di atas, fungsi “Query” dari Google sangat diperlukan untuk menyelesaikan masalah ketiga.
Google memang memiliki fungsi untuk “mencari halaman yang mengandung kata kunci tertentu dari seluruh internet” (pencarian global), tetapi ada batas maksimum “2 halaman per situs”. Namun, jika Anda menggunakan “Query” seperti “kata kunci site:URL situs target”, Anda dapat:
- Melakukan pencarian hanya pada artikel dalam situs target yang ditentukan
- Hasil pencarian tersebut tidak memiliki batas “2 halaman per situs”
Anda dapat melakukan pencarian seperti ini.
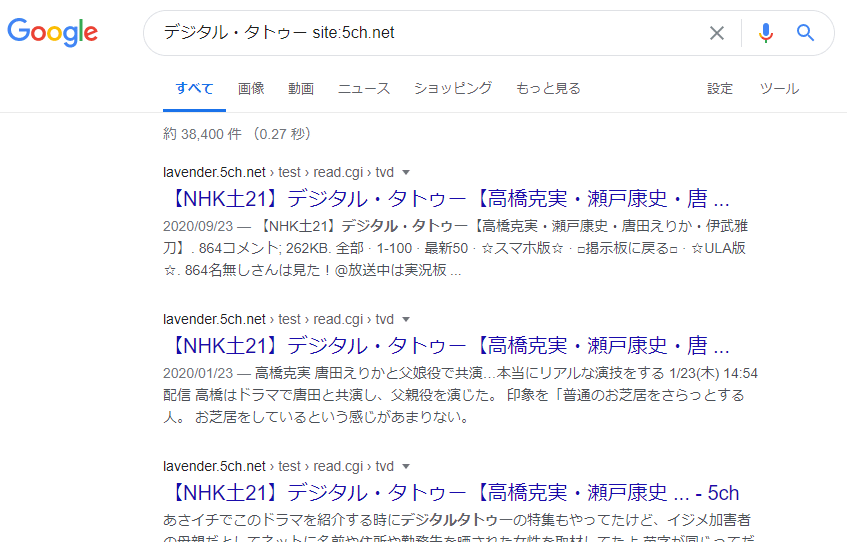
“Query” sebenarnya lebih kompleks, dan ada berbagai jenis query yang dapat digunakan untuk menyelesaikan masalah lainnya.
Metode Pencarian Khusus untuk Situs Tertentu
Sebagai contoh, Yahoo! Chiebukuro (Yahoo! Answers Jepang) memiliki fungsi pencarian khususnya sendiri.
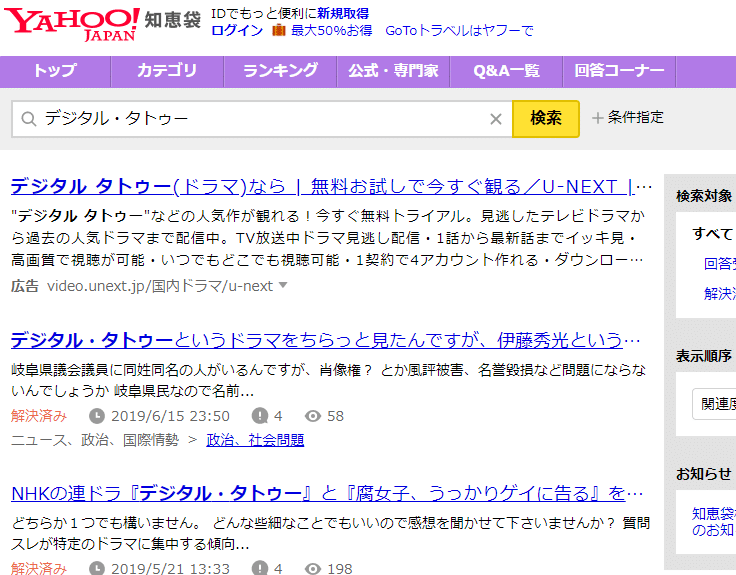
Pencarian ini bukanlah “halaman web yang (kebetulan) diindeks oleh Google”, melainkan “hasil pencarian dari database Yahoo! Chiebukuro yang langsung dicari oleh program pencarian Yahoo! Chiebukuro”. Ini menjadi solusi untuk masalah yang disebutkan sebelumnya, yaitu “ada halaman web yang belum diindeks oleh Google”. Artinya, “jika itu adalah halaman di dalam Yahoo! Chiebukuro, selama kita menggunakan fungsi pencarian Yahoo! Chiebukuro, kita dapat menemukan semuanya tanpa kehilangan apa pun”.
Dengan kata lain,
Tentang suatu fakta (misalnya skandal perusahaan, penangkapan individu, dll.), setidaknya jika halaman Yahoo! Chiebukuro ditemukan dalam pencarian global, menggunakan fungsi pencarian di dalam Yahoo! Chiebukuro daripada menggunakan formula pencarian “site:” akan memungkinkan kita untuk membuat daftar tanpa kehilangan apa pun.
Itulah maksudnya.
Hal yang sama berlaku untuk Twitter dan lainnya. Twitter, karena sifat layanannya, adalah situs di mana seringkali ada banyak tweet tentang fakta yang menjadi topik (misalnya skandal perusahaan, penangkapan individu, dll.). Namun, tidak semua tweet tersebut selalu diindeks oleh Google, dan setidaknya tidak semuanya ditampilkan dalam pencarian global.
Cara Menghitung ‘1 Kasus’ yang Akan Dihapus

Hubungan antara Penyusunan Daftar yang Tepat dan ‘URL’
Sampai sejauh ini, kami telah menulis tentang ‘cara mengumpulkan sebanyak mungkin halaman web (URL) menggunakan Google Search dan sejenisnya’, namun, bukan berarti semakin banyak yang dapat Anda daftar, semakin baik. Ini karena target permintaan penghapusan tidak selalu menggunakan ‘URL’ sebagai unitnya.
Kasus 5ch (Forum Diskusi Online Jepang)
Ini adalah masalah yang muncul terutama dalam kasus situs-situs forum seperti 5ch dan situs-situs salinan serta situs-situs forum lainnya.
Misalnya, jika Anda mencari kata kunci tertentu di Google dengan formula pencarian ‘site:5ch.net’, yaitu, mencari dalam 5ch, ada kasus di mana URL seperti berikut ditampilkan sebagai hasil pencarian:
- ○○○.5ch.net/test/read.cgi/○○/○○○○/40
- ○○○.5ch.net/test/read.cgi/○○/○○○○/1-100
- ○○○.5ch.net/test/read.cgi/○○/○○○○/30-
5ch memiliki spesifikasi seperti:
- Jika Anda menulis nomor respons setelah URL thread, hanya respons tersebut yang ditampilkan
- Jika Anda menulis rentang nomor respons seperti ‘A-B’ setelah URL thread, hanya respons dalam rentang tersebut yang ditampilkan
- Jika Anda menulis titik awal nomor respons dan ‘-‘ setelah URL thread, semua respons setelah respons tersebut ditampilkan
Dengan kata lain, hanya karena kata kunci tertentu ditulis dalam respons nomor 40, berbagai URL (halaman web) ditampilkan dalam ‘hasil pencarian’.
Namun, ketika mengajukan permintaan penghapusan ke situs forum, unit target permintaan tersebut, setidaknya secara prinsip, adalah ‘respons’. Oleh karena itu, jika Anda ingin menghapus respons nomor 40, cukup ekstrak
- ○○○.5ch.net/test/read.cgi/○○/○○○○/40
URL ini saja, dan Anda tidak perlu mencantumkan dua yang lainnya.
Kasus Situs Salinan 5ch dan Situs Ringkasan
Sebagai tambahan, meskipun ini cerita yang agak rumit, bahkan dalam kasus 5ch (dan sejenisnya), dalam kasus situs salinan dan ‘situs ringkasan’, tergantung pada situsnya, unit permintaan penghapusan bukan ‘respons’ tetapi ‘halaman (thread)’. ‘Apa yang menjadi target permintaan penghapusan situs mana’ sepenuhnya berada dalam wilayah ‘pengetahuan khusus’.
https://monolith.law/reputation/delation-of-scraping-site-roundup-website[ja]
Oleh karena itu,
- Pemahaman tentang unit permintaan penghapusan hukum
- Pemahaman tentang spesifikasi URL situs web tertentu (misalnya, 5ch memiliki aturan rumit seperti di atas)
jika tidak ada, ‘mendaftar target penghapusan saat melihat hasil pencarian’ itu sendiri akan menjadi sulit.
Pencarian di Luar Web Terbuka

Sampai sejauh ini, kami telah menjelaskan tentang situs-situs yang mungkin diindeks oleh Google, namun,
- Google tidak akan mengindeks dengan pasti
- Namun harus dipertimbangkan sebagai target permintaan penghapusan dalam manajemen risiko reputasi
Ada juga kelompok situs seperti itu.
Google, berdasarkan spesifikasi di atas, hanya menargetkan situs web yang dapat dilihat oleh siapa saja tanpa perlu login (web terbuka). Namun, misalnya, di dunia ini, ada juga layanan web berbayar yang memungkinkan Anda untuk mencari dan melihat sekaligus artikel lama dari surat kabar (oleh karena itu, Anda tidak dapat melihatnya tanpa mendaftar atau login).
Misalnya, dalam kasus penghapusan artikel penangkapan, perlu juga untuk memeriksa situs database surat kabar di atas. Ini karena banyak perusahaan yang melakukan penelitian tentang kredit perusahaan dan individu menggunakan situs database surat kabar tersebut.
Untuk detail tentang situs database surat kabar, silakan lihat artikel di bawah ini.
https://monolith.law/reputation/criminal-record-newspaper-database[ja]
Kesimpulan
Seperti yang telah dijelaskan di atas, “mendaftar permintaan penghapusan sebagai tindakan penanggulangan reputasi buruk dari internet” adalah tugas yang sangat memerlukan keahlian khusus. Kantor kami melakukan daftar artikel target seperti yang dijelaskan di atas saat menerima tindakan penanggulangan reputasi buruk, tetapi pekerjaan ini didasarkan pada keahlian khusus dalam IT dan internet.
Penghapusan halaman (atau postingan forum) sebagai tindakan penanggulangan reputasi buruk di internet adalah tugas yang hanya dapat dilakukan oleh pengacara.
https://monolith.law/reputation/hiben-koui[ja]
Namun, di sisi lain, daftar ini, seperti yang dijelaskan dalam artikel ini, adalah tugas yang sangat memerlukan pengetahuan IT dan internet. Ini adalah salah satu alasan besar mengapa Anda harus meminta tindakan penanggulangan reputasi buruk kepada kantor hukum yang memiliki keahlian tinggi dalam IT dan internet. Meskipun ini mungkin berulang, jika daftar seperti ini tidak cukup,
- meskipun Anda telah membersihkan semua halaman yang terdaftar, halaman lain yang tidak ditampilkan dalam hasil pencarian global saat daftar mungkin ditampilkan dalam hasil pencarian, dan penghapusan tambahan diperlukan, membuat perkiraan anggaran awal menjadi sangat salah
- prosedur pengadilan yang seharusnya diselesaikan dalam satu kali menjadi perlu dua atau tiga kali, dan biaya yang berlebihan diperlukan
- Anda mungkin tidak menyadari keberadaan halaman di luar web terbuka, seperti situs database surat kabar, dan misalnya, “masalah” seperti “kesulitan mendapatkan pekerjaan karena artikel penangkapan dicari” tidak dapat diselesaikan
masalah seperti ini dapat terjadi.
Category: Internet