Kan generering av "stemmer" med AI føre til brudd på opphavsretten? (#1 Utvikling og læringstrinn)

Med utviklingen av generativ AI er det nå mulig å enkelt lære opp og generere ‘stemmer’ av eksisterende sangere og stemmeskuespillere. I forretningsverdenen har dette åpnet for muligheter som å utvikle apper, skape spill og animasjoner ved å lære AI ‘stemmer’ og generere nye ‘stemmer’.
Å lære en generativ AI ‘stemmen’ til eksisterende sangere og stemmeskuespillere og generere nye ‘stemmer’ kan potensielt være en ulovlig handling, som for eksempel brudd på opphavsretten.
I realiteten har det ennå ikke kommet en klar tolkning av disse problemstillingene. Hva slags juridiske rettigheter innebærer en ‘stemme’, og i hvilke tilfeller kan det oppstå problemer med opphavsretten?
I denne artikkelen vil vi diskutere disse spørsmålene, og vi vil gjøre det i to deler. I denne første delen vil vi forklare potensielle rettighetsbrudd som kan oppstå i utviklings- og læringsfasen av generativ AI. Juridiske problemstillinger knyttet til generering og bruk vil bli forklart i denne artikkelen (#2 Generering og bruk)[ja]. Vi anbefaler at du leser begge delene for en fullstendig forståelse.
Tre juridiske rettigheter knyttet til menneskers «stemme» under japansk lov
Hvilke juridiske rettigheter har menneskers «stemme»? Når vi vurderer dette spørsmålet, er det nødvendig å ha to perspektiver på «stemmen»:
- Hva stemmen sier,
- Hvordan stemmen høres ut.
Med andre ord kan vi skille mellom det første punktet, som er et spørsmål om «innholdet» i stemmen, og det andre punktet, som er et spørsmål om «lyden» av stemmen.
For eksempel, hvis forskjellige stemmeskuespillere sier replikken «god morgen», vil innholdet i det første punktet være det samme, men lyden i det andre punktet vil variere.
Med disse perspektivene i betraktning, kan vi under gjeldende japansk lov identifisere følgende tre juridiske rettigheter som kan oppstå i forbindelse med menneskers «stemme»:
| ① Opphavsrett | Kan oppstå i forbindelse med stemmens «innhold» |
| ② Nærliggende rettigheter (begrenset til utøveres rettigheter) | Kan oppstå i forbindelse med både stemmens «innhold» og «lyd» |
| ③ Publisitetsrett | Kan oppstå i forbindelse med stemmens «lyd» |
Om opphavsrett i Japan
Opphavsrett oppstår når innholdet i en stemme kvalifiserer som et åndsverk under japansk lov.
For eksempel, hvis man leser opp en kjent roman, kan stemmen inneha opphavsrett. Det er imidlertid viktig å merke seg at i slike tilfeller tilhører opphavsretten forfatteren av romanen, og ikke personen som er “stemmens eier” eller den som uttaler ordene. Det betyr at hvis man skaper en syntetisk stemme som leser opp innholdet av en kjent roman ved hjelp av generativ AI, kan denne handlingen potensielt krenke opphavsretten til forfatteren av romanen.
Derimot, hvis innholdet i en stemme består av vanlig dagligdags samtale fra en gjennomsnittsperson, oppstår det ikke opphavsrett. Dette skyldes at alminnelige dagligdagse samtaler i seg selv ikke regnes som åndsverk og derfor ikke er beskyttet av opphavsrettsloven.
Om naborettigheter i Japan
Naborettigheter (begrenset til rettighetene til utøvere) kan oppstå i tilfeller der innholdet i en stemme tilsvarer et åndsverk, og stemmen er en del av en fremføring, som for eksempel opplesning.
Som nevnt i avsnittet om opphavsrett, kan en stemme som utfører en “opplesning” – en form for “fremføring” – gi opphavsrettslige naborettigheter til oppleseren. I motsetning til opphavsretten, er det viktig å merke seg at innehaveren av naborettighetene ikke er forfatteren av romanen, men den personen som faktisk utfører opplesningen.
Om retten til publisitet under japansk lov
Retten til publisitet er en rettighet som er anerkjent av rettspraksis (Høyesterettsdom H24 (2012).2.2) og defineres som “den eksklusive retten til å utnytte den kundetiltrekkende kraften som en persons navn, portrett osv. har”.
| ▶︎ Høyesterettsdom H24 (2012).2.2 (Pink Lady-saken) ■ Domstolens avgjørelse ① Når et navn, portrett osv. brukes som et selvstendig objekt for beundring i varer osv., ② Når et navn, portrett osv. er knyttet til varer osv. med det formål å differensiere produktene, ③ Når et navn, portrett osv. brukes utelukkende som reklame for varer osv. og dermed utnytter den kundetiltrekkende kraften som navnet, portrettet osv. har, vil det utgjøre en krenkelse av retten til publisitet og være ulovlig som en urettmessig handling ■ Kommentar fra undersøkelsesdommer (Høyesterettens rettsavgjørelser, sivilrettslig del, for året 2012 (første halvdel) side 18) I denne dommen refererer “portrett osv.” til informasjon som identifiserer personen, og inkluderer for eksempel signaturer, underskrifter, stemmer, pseudonymer, kunstnernavn osv. |
I henhold til Pink Lady-saken kan også en stemme gi grunnlag for retten til publisitet. Hvis det kan fastslås at den aktuelle stemmen tilhører en person med kundetiltrekkende kraft, som en eksisterende stemmeskuespiller, skuespiller, sanger osv., vil retten til publisitet oppstå uavhengig av “innholdet”. Videre, hvis stemmen brukes på en av de tre måtene som krenker retten til publisitet som fastslått i Pink Lady-saken, vil det utgjøre en krenkelse av retten til publisitet.
Tre bruksmønstre i utviklings- og læringsfasen
Å si at man “genererer stemmer med generativ AI” krever at man deler prosessen inn i to hoveddeler:
- Utviklings- og læringsfasen
- Genererings- og bruksfasen
Fase 1 utføres av AI-utviklere, mens fase 2 utføres av brukere av AI.
Når vi visualiserer disse prosessene, ser det slik ut:
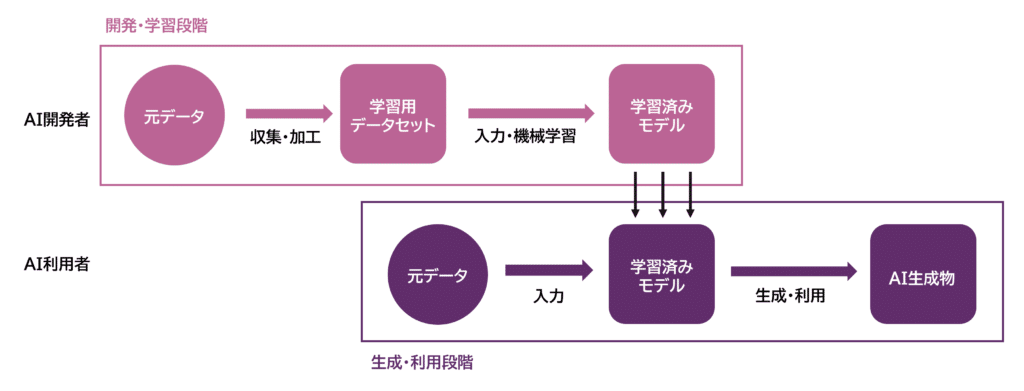
I utviklings- og læringsfasen samler og lagrer man opprinnelige stemmedata fra mennesker som læringdata for AI-utvikling, og skaper et datasett for læring. Deretter mates dette datasettet inn i AI for maskinlæring, og man skaper en trent modell. På den annen side, i genererings- og bruksfasen, mates de opprinnelige dataene inn i en generativ AI som har fullført maskinlæringen, og man genererer og bruker AI-produkter.
For utviklings- og læringsfasen kan vi forutse følgende tre bruksmønstre:
- Mønster 1: Innsamling, lagring, bearbeiding og bruk av menneskelige stemmedata som læringdata for AI-utvikling
- Mønster 2: Salg eller offentliggjøring av læringdatasett brukt i AI-utvikling
- Mønster 3: Salg eller offentliggjøring av den generative AI-en selv
I det følgende vil vi kort forklare hvilke typer rettighetsbrudd som kan oppstå i hvert av disse bruksmønstrene.
Mønster 1: Innsamling, lagring, bearbeiding og bruk av menneskelige stemmedata for AI-utvikling

Først vil vi forklare potensielle rettighetskrenkelser som kan oppstå i fasen hvor man samler, lagrer, bearbeider og bruker menneskelige stemmedata for å trene AI.
Forholdet til opphavsrett
I mønster 1 refererer bruken spesifikt til handlingen med å utvikle selve generativ AI. AI-utvikling faller under “informasjonsanalyse” i henhold til artikkel 30-4 nummer 2 i den japanske opphavsrettsloven (heretter forkortet), og derfor er bruken av nødvendige opphavsrettsbeskyttede verk i prinsippet ikke en krenkelse av opphavsretten (artikkel 30-4).
Det finnes imidlertid et betydelig unntak. Dersom det er et formål å skape AI-genererte produkter som har de essensielle uttrykksfulle egenskapene til originaldataene når man lager et datasett for trening (et formål med uttrykksproduksjon), vil artikkel 30-4 ikke være anvendelig, og bruken vil være ulovlig.
Med andre ord, hvis man bruker stemmedata fra andre stemmeskuespillere med det formål å reprodusere eller hylle en bestemt stemmeskuespillers karakteristiske stemme, kan bruken anses som en krenkelse av opphavsretten fordi det er et formål med uttrykksproduksjon.
Forholdet til nærliggende rettigheter
I forhold til nærliggende rettigheter, blir artikkel 30-4 i opphavsrettsloven også anvendt i henhold til artikkel 102, så selv om man utfører en opptreden osv. for å utvikle generativ AI, vil det i prinsippet ikke være en krenkelse av nærliggende rettigheter.
Forholdet til publisitetsrettigheter
Forholdet til publisitetsrettigheter blir relevant når man vurderer utviklingen av generativ AI med det formål å skape en spesifikk kjent persons “stemme”.
For å avgjøre om det er en krenkelse av publisitetsrettigheter, kan de tre typene av krenkelser i den velkjente Pink Lady-saken være til hjelp.
Først og fremst, selve handlingen med å utvikle generativ AI med det formål å skape en spesifikk kjent persons “stemme” faller ikke under de tre typene av krenkelser i Pink Lady-saken. Men hvis handlingen “utelukkende har som formål å utnytte kundetiltrekningskraften til et navn, portrett osv.”, kan det utgjøre en krenkelse av publisitetsrettigheter og dermed være en ulovlig handling.
For at utnyttelsen av kundetiltrekningskraften skal finne sted, må det være mulig for tredjeparter å oppfatte at det er den kjente personens stemme som brukes når man lager datasettet for trening. Hvis ikke tredjeparter, som er kunder, oppfatter dette, vil det ikke kunne oppstå noen kundetiltrekning. Imidlertid er det vanligvis ikke rom for at tredjeparter som kunder er involvert i utviklingsfasen av generativ AI.
Derfor kan man si at det er lite rom for at bruken utgjør en krenkelse av publisitetsrettigheter.
Mønster 2: Salg og offentliggjøring av treningsdatasett brukt i AI-utvikling
Her forklarer vi mulige brudd på rettigheter som kan oppstå i forbindelse med salg og offentliggjøring av treningsdatasett for AI.
Forholdet til opphavsrett
Hvis treningsdatasettet inneholder originaldata i sin opprinnelige form eller i en noe bearbeidet form, kan salg og offentliggjøring av treningsdatasettet utgjøre et brudd på overføringsretten (artikkel 26-2) eller retten til offentlig overføring (artikkel 23) av det aktuelle verket eller avledede verk (artikkel 28). Derfor vil det å gjennomføre dette uten samtykke fra opphavspersonen være et brudd på opphavsretten.
Imidlertid, som nevnt ovenfor, tillater artikkel 30-4 i visse tilfeller bruk av verk “for informasjonsanalyse” så lenge det er “innenfor nødvendige grenser, uavhengig av metoden som brukes”. Derfor, når overføring eller offentliggjøring utføres for å utvikle generativ AI, vil det ikke utgjøre et brudd på opphavsretten så lenge det er innenfor anerkjente nødvendige grenser.
Forholdet til nærliggende rettigheter
På samme måte som nevnt ovenfor, blir artikkel 30-4 anvendt i henhold til artikkel 102, så prinsipielt vil ikke salg og offentliggjøring av treningsdatasett for utvikling av generativ AI utgjøre et brudd på nærliggende rettigheter.
Forholdet til retten til publisitet
Noen treningsdatasett inneholder spesifikke kjendisers stemmer lagret i et format som kan gjengis direkte. Imidlertid brukes treningsdatasett vanligvis kun for utvikling av generativ AI og kan ikke sies å være “brukt som et produkt som i seg selv er gjenstand for uavhengig estetisk nytelse”, slik som det ble fastslått i den endelige dommen i Pink Lady-saken.
Derfor kan det sies at det er lite rom for at den aktuelle bruken utgjør et brudd på retten til publisitet.
Mønster 3: Salg og offentliggjøring av selve genererende AI

Her forklarer vi om mulige brudd på rettigheter som kan oppstå i fasen av salg og offentliggjøring av selve den opplærte modellen.
Forholdet til opphavsrett
I motsetning til datasettene som brukes til trening, kan man ikke anta at den opplærte modellen av en genererende AI inneholder deler av originaldataen (verk) som har kreativitet. Derfor kan den opplærte modellen i seg selv, det vil si selve genererende AI, ikke betraktes som et sekundært verk av originaldataen, og dermed utgjør ikke offentliggjøring eller salg av disse et brudd på opphavsretten.
Forholdet til nærliggende rettigheter
Likeledes, siden man ikke kan anta at den opplærte modellen inneholder kreative deler av originaldataen, kan salg og offentliggjøring av selve genererende AI ikke sies å krenke nærliggende rettigheter.
Forholdet til retten til publisitet
Selv en AI som kan generere en spesifikk kjendis’ stemme fritt og med høy presisjon, faller tydelig utenfor de tre typene av krenkelser som ble fastslått i den endelige dommen i Pink Lady-saken. Likevel er det vanlig at slike AI tiltrekker kunder ved å verdsette evnen til å generere en spesifikk kjendis’ stemme fritt og med høy presisjon, og kundene kjøper vanligvis den aktuelle AI fordi den kan generere en spesifikk kjendis’ stemme. Derfor kan salget av en slik AI sannsynligvis betraktes som en lignende handling til de tre krenkelsestypene og dermed utgjøre en overtredelse av retten til publisitet.
Oppsummering: Konsulter en ekspert om forholdet mellom generativ AI og opphavsrett
Hittil har vi forklart de juridiske rettighetene som menneskelige stemmer har, og de problematiske handlingene som kan oppstå når man bruker disse rettighetene, basert på konkrete eksempler.
Det er viktig å forstå at de juridiske rettighetene til en persons stemme må vurderes både med hensyn til “innhold” og “lyd”, og at det er essensielt å være bevisst på opphavsrett, tilstøtende rettigheter og publisitetsrettigheter. I denne første delen har vi fokusert på utviklings- og læringsfasen, men i den påfølgende delen vil vi forklare genererings- og bruksfasen.
Relatert artikkel: Kan generering av ‘stemme’ med AI føre til brudd på opphavsretten? (#2 Genererings- og bruksfasen)[ja]
Veiledning om tiltak fra vår advokatfirma
Monolith Advokatfirma har omfattende erfaring innen IT, spesielt internett, og juridiske tjenester. I de senere årene har generativ AI og intellektuell eiendomsrett, som opphavsrett, fått økt oppmerksomhet, og behovet for juridisk gjennomgang har blitt stadig viktigere. Vårt firma tilbyr løsninger relatert til intellektuell eiendom. Vennligst se den følgende artikkelen for detaljer.
Monolith Advokatfirmas tjenesteområder: IT- og IP-juridiske tjenester for ulike selskaper[ja]
Category: IT




















