Förutsättningar för åtgärder mot ryktesskador: En guide till att granska negativa artiklar på nätet

Om du vill radera webbsidor som handlar om tidigare företagsskandaler, viral kontrovers, arresteringar eller brottsregister, är det första steget att noggrant lista alla dessa negativa sidor och inlägg. Om du inte kan skapa denna lista kan du inte hantera ryktesrisker medan du tittar på den totala volymen, och det finns också en risk att du till exempel måste genomföra rättsliga förfaranden som tillfälliga åtgärder eller rättegångar två gånger istället för en gång på grund av missade saker.
Men det är inte “enkelt” att lista alla webbsidor och inlägg på internet som beskriver en viss faktum (till exempel företagsskandaler, viral kontrovers, arresteringar eller brottsregister). Denna del kräver mycket specialisering och kan inte göras utan kunskap.
Monolith Law Office är en advokatbyrå specialiserad på ryktesriskhantering, med en ledande advokat som är en före detta IT-ingenjör och personal specialiserad på internetforskning som nämnts ovan. Här förklarar vi hur internetforskning bör utföras.
Vad är Google sökresultat och dess begränsningar?
Grunden för nätverksforskning är fortfarande Google-sökning. Men i Google, när du söker efter nyckelord du vill hitta, till exempel i fallet med att ta bort arresteringsartiklar, finns det begränsningar i tre meningar för sökresultaten som visas när du söker efter nyckelord som “ditt eget namn arrestering”.
Webbsidor som är mål för Google-sökning
På internet finns det “otaliga” webbsidor. Det totala antalet webbsidor på internet är teoretiskt omätbart, men enligt vissa uppskattningar finns det för närvarande cirka 1,8 miljarder “webbplatser”.
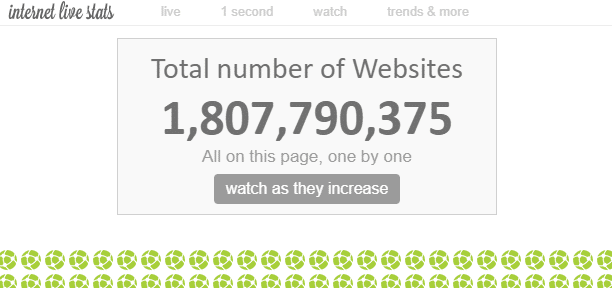
Eftersom det finns flera webbsidor inom en webbplats, är antalet webbsidor mycket större än det.
Och Google-sökning, för att uttrycka det enkelt, utförs genom följande mekanism:
- Googles bot (Googlebot) skannar internet och upptäcker nya webbsidor som kan öppnas genom att följa länkar från kända webbsidor
- Förstår innehållet på den sidan (indexregistrering)
- Visar den sidan i sökresultaten när en sökning utförs med nyckelord som finns på den sidan
Vad jag vill säga är att det som visas i Google-sökning är webbsidor som Google har indexerat “på det sättet” ovan, inte “alla webbsidor”. Med andra ord, så länge du använder Google-sökning, kan du inte hitta webbsidor som “Google ännu inte har indexerat”, och det finns ingen metod i världen för att helt och hållet söka igenom alla webbsidor på internet.
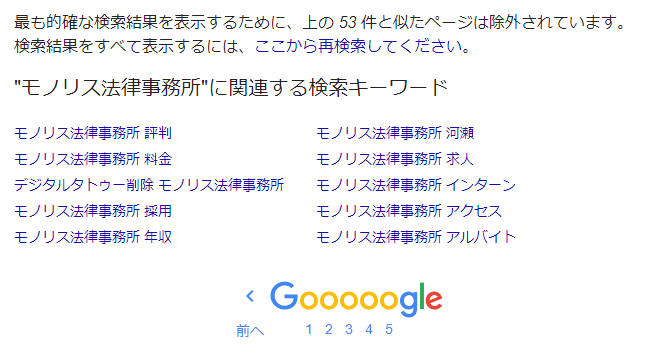
“Liknande” webbsidor utesluts från sökresultaten
Google visar inte alla webbsidor som innehåller sökordet och som är indexerade i sökresultaten. Detta är något du kanske har märkt om du använder Google-sök regelbundet. På den sista sidan i sökresultaten visas meddelandet “För att visa de mest relevanta resultaten har vi utelämnat vissa poster som är mycket lika de redan visade”.
Till exempel, om:
- en viss nyhet först publiceras på en stor nyhetssida,
- sedan återpubliceras på en nyhetssammanställningstjänst,
- och sedan återpubliceras på personliga webbplatser,
kan Google automatiskt utesluta “liknande” sidor, som nummer 2 och 3 i detta exempel, från sökresultaten för att förhindra att samma innehåll fyller upp sökresultaten och gör dem svåra att använda för användaren.
Detta är inte nödvändigtvis en “användarvänlig” funktion om du vill “radera” sidor med skadligt rykte. Till exempel, om den “vissa nyheten” ovan är en gammal arresteringsrapport om dig själv,
Om endast “1. Den ursprungliga artikeln från den stora nyhetssidan” visades i sökresultaten och du raderade den sidan, kan “2. Artikeln återpublicerad på nyhetssammanställningstjänsten” börja visas i Google-sökresultaten eftersom nummer 1 har tagits bort.
Detta kan hända.
För att lösa detta problem kan du klicka på “Sök igen med de utelämnade resultaten inkluderade” i meddelandet ovan. Men om du inte känner till denna funktion kan du missa sidor med skadligt rykte.
Det finns en gräns för antalet artiklar som visas från samma webbplats

Dessutom har Google satt en gräns för antalet sökresultatsidor som visas från en enda webbplats. Denna specifikation är lite komplicerad, men för att förenkla det, “högst två sidor visas från samma webbplats”.
Vad detta innebär är att till exempel, även om det finns fem frågor och svar där ett företags eller individs namn nämns inom Yahoo! Chiebukuro, kommer högst två sidor från Yahoo! Chiebukuro att visas i sökresultaten när du söker på det företagets eller individens namn på Google. Detta gäller även för forum, där högst två trådar från 5ch som innehåller ett visst nyckelord kommer att visas i Google-sökresultaten. Dessutom, till exempel, om en person har,
- En artikel om att bli arresterad
- En artikel om att bli återarresterad
- En artikel om att bli dömd
och alla tre artiklarna finns på samma nyhetssida, kommer minst en av dem (3-2=1) inte att visas i Google-sökresultaten.
När du söker på ett visst nyckelord och ett stort antal sidor från samma webbplats (till exempel Yahoo! Chiebukuro, ett specifikt forum, en specifik nyhetssida etc.) visas i sökresultaten, blir det obekvämt för användaren, så Google har denna specifikation.
Men denna specifikation är inte nödvändigtvis “användarvänlig” om du vill “sopa bort alla sidor med dåligt rykte”.
Till exempel, om du vill ta bort negativa frågor och svar från Yahoo! Chiebukuro genom rättsliga förfaranden och du tittar på Google-sökresultaten och bestämmer att “det finns bara två mål”, och du fortsätter med förfarandet, kommer någon av de återstående 3 av 5-2=3 att visas i sökresultaten när borttagningen lyckas.
Avancerad Google-sökning med “sökformler”
För att särskilt lösa det tredje problemet ovan, behöver vi använda en funktion i Google som kallas “sökformler”.
Google har visserligen en funktion (global sökning) som “söker sidor som innehåller den angivna nyckelordet från hela internet”, och har satt en gräns på “grundläggande 2 sidor per webbplats”. Men om du använder en “sökformel” som “nyckelord site: målwebbplatsens URL”, kan du:
- Utföra sökningar endast inom artiklarna på den angivna målwebbplatsen
- Det finns ingen gräns på “grundläggande 2 sidor per webbplats” för dessa sökresultat
Detta gör att du kan utföra sådana sökningar.
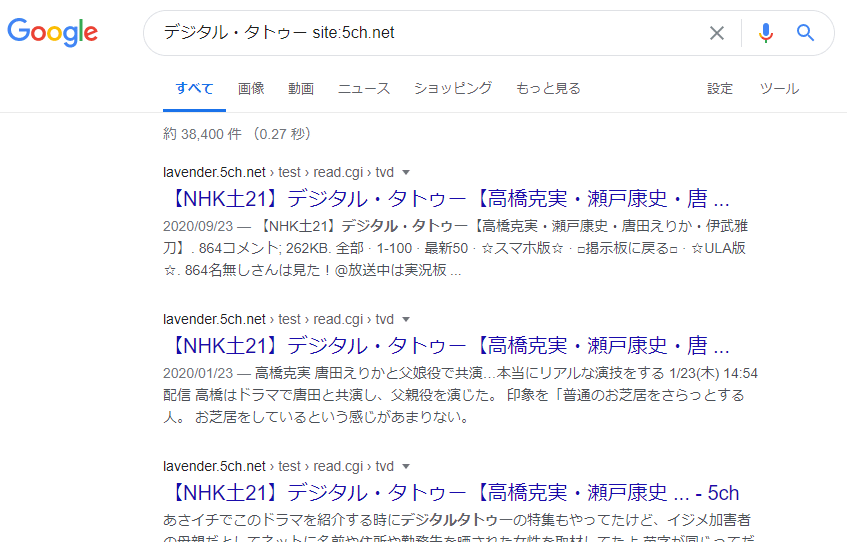
“Sökformler” är faktiskt mer komplexa, och det finns också sökformler som används för att lösa problem utöver de ovan nämnda.
Särskilda sökmetoder för specifika webbplatser
Till exempel har Yahoo! Chiebukuro (Yahoo! Answers) en unik sökfunktion.
Denna sökning är inte baserad på “webbsidor som Google (slumpmässigt) har indexerat”, utan på “resultatet av en sökning som Yahoo! Chiebukuro’s sökprogram har gjort direkt i Yahoo! Chiebukuro’s databas”. Detta löser problemet vi nämnde tidigare, att “det finns webbsidor som Google ännu inte har indexerat”. Med andra ord, om det är en sida inom Yahoo! Chiebukuro, kan du hitta allt utan att missa något genom att bara använda Yahoo! Chiebukuro’s sökfunktion.
Med andra ord,
Om det finns en viss fakta (företagets skandal, en individs arrestering etc.) och åtminstone en sida på Yahoo! Chiebukuro hittas i en global sökning, kan du göra en mer omfattande lista genom att använda Yahoo! Chiebukuro’s sökfunktion snarare än att använda “site:” sökformeln.
Detta gäller också för Twitter. På grund av naturen hos Twitter-tjänsten finns det ofta flera tweets om en viss händelse (företagets skandal, en individs arrestering etc.). Inte alla dessa tweets är nödvändigtvis indexerade av Google, och de visas inte alla i en global sökning.
Räknesätt för “1 objekt” som ska tas bort

Förhållandet mellan en korrekt lista och “URL”
Hittills har vi skrivit om “hur man hittar så många webbsidor (URL) som möjligt med hjälp av Google-sökning etc.”, men det betyder inte nödvändigtvis att det är bra om du kan lista upp många. Detta beror på att objektet för borttagningsbegäran inte nödvändigtvis tar “URL” som enhet.
I fallet med 5ch (5chan)
Detta är en fråga som särskilt uppstår när det gäller webbplatser för meddelandetavlor (som 5ch och dess kopia webbplatser, och andra meddelandetavlor).
Till exempel, om du söker efter ett visst nyckelord på Google med sökformeln “site:5ch.net”, det vill säga, söker inom 5ch, kan följande URL visas som sökresultat.
- ○○○.5ch.net/test/read.cgi/○○/○○○○/40
- ○○○.5ch.net/test/read.cgi/○○/○○○○/1-100
- ○○○.5ch.net/test/read.cgi/○○/○○○○/30-
5ch har följande specifikationer:
- Om du skriver in svarsnumret efter tråd-URL:en visas endast det svaret
- Om du skriver in ett intervall av svarsnummer som “A-B” efter tråd-URL:en visas endast svaren inom det intervallet
- Om du skriver in ett startnummer för svaret och “-” efter tråd-URL:en visas svaren från och med det svaret
Med andra ord, bara för att det specifika nyckelordet är skrivet i svarsnummer 40, visas olika URL:er (webbsidor) i “sökresultaten”.
Men när du begär att ta bort från en meddelandetavla, är enheten för det du begär att ta bort, åtminstone i princip, “svar”. Därför, om du vill ta bort svarsnummer 40, behöver du bara extrahera
- ○○○.5ch.net/test/read.cgi/○○/○○○○/40
URL, och du behöver inte lista upp de andra två.
I fallet med 5ch kopia webbplatser och sammanfattningssidor
För att tillägga, även om det är samma 5ch (serie), i fallet med dess kopia webbplatser och “sammanfattningssidor”, beroende på webbplatsen, är enheten för borttagningsbegäran inte “svar” utan “sida (tråd)”. “Vilket objekt för borttagningsbegäran gäller vilken webbplats” är helt och hållet inom området för “know-how”.
https://monolith.law/reputation/delation-of-scraping-site-roundup-website[ja]
Därför,
- Förståelse för enheten för laglig borttagningsbegäran
- Förståelse för URL-specifikationen för en viss webbplats (till exempel har 5ch komplexa regler som ovan)
Om du inte har det, blir det svårt att “lista upp objekt för borttagning medan du tittar på sökresultaten”.
Sökningar utanför öppna webben

Hittills har vi diskuterat webbplatser som Google potentiellt kan indexera, men det finns också webbplatser som:
- Google definitivt inte kommer att indexera
- Men bör övervägas för borttagningsbegäran som en del av rykteshanteringsåtgärder
Dessa webbplatser existerar också.
Google indexerar endast webbplatser som är öppna för alla att se (öppna webben) utan att behöva logga in. Men det finns till exempel webbtjänster som låter dig söka och läsa gamla tidningsartiklar mot en avgift (och därför kan du inte se dem utan att registrera dig eller logga in).
Till exempel, i fallet med att ta bort arresteringsartiklar, är det nödvändigt att noggrant granska tidningsdatabaswebbplatserna. Detta beror på att företag som undersöker företags och individers kreditvärdighet ofta använder dessa tidningsdatabaswebbplatser.
Mer information om tidningsdatabaswebbplatser finns i följande artikel.
https://monolith.law/reputation/criminal-record-newspaper-database[ja]
Sammanfattning
Som vi har sett ovan är det att “sammanställa en lista över objekt att begära borttagning från på internet som en del av rykteshantering” en mycket specialiserad uppgift. Vårt kontor utför denna typ av listning av artiklar när vi tar hand om rykteshantering, men detta arbete förutsätter en expertis inom IT och internet.
Att ta bort sidor (eller forum inlägg) på internet som en del av rykteshantering är en uppgift som endast advokater kan utföra.
https://monolith.law/reputation/hiben-koui[ja]
Å andra sidan är denna listning, som vi har förklarat i denna artikel, en uppgift som kräver mycket avancerad kunskap om IT och internet. Detta är en av de stora anledningarna till att man bör anlita en advokatbyrå med avancerad expertis inom IT och internet för att hantera rykteshantering. Om listningen, som vi har nämnt ovan, är bristfällig, kan följande problem uppstå:
- Även om alla listade sidor tas bort, kan andra sidor som inte visades i de globala sökresultaten vid listningstidpunkten visas i sökresultaten, vilket kräver ytterligare borttagning och gör att den ursprungliga budgetberäkningen blir helt fel.
- Rättsliga förfaranden som ursprungligen skulle ha kunnat slutföras på en gång kan kräva två eller tre omgångar, vilket leder till överdrivna kostnader.
- Man kanske inte märker existensen av sidor utanför det öppna webben, som tidningsdatabaser, och problemet med att till exempel “inte kunna få ett jobb på grund av att arresteringsartiklar söks upp” löses inte.
Dessa är de problem som kan uppstå.
Category: Internet
Related Articles

Hur kan man undvika att ens eget namn visas i sökresultat? En förklaring av hur man tar bort det.
Internet

【Snabb rapport】Nu kan du posta 'Försök att sjunga' även på Threads! Slutförde licensavtal med JA.
Internet


















