Forklaring av metoder for å undersøke negative artikler på nettet som en forutsetning for tiltak mot rykteskader

Når det gjelder å eliminere nettsider som inneholder informasjon om tidligere bedriftsskandaler, branner, arrestasjoner eller tidligere strafferegistre, er det først og fremst nødvendig å lage en omfattende liste over alle slike negative sider og innlegg. Uten denne listen kan du ikke håndtere omdømmeskade mens du ser på det totale volumet, og for eksempel, i tilfelle midlertidige tiltak eller rettssaker, kan det være nødvendig å gjennomføre prosedyren to ganger i stedet for en gang på grunn av oversettelse.
Imidlertid er det absolutt ikke “enkelt” å lage en liste over alle nettsider og innlegg som beskriver en viss faktum (for eksempel bedriftsskandaler, branner, arrestasjoner eller tidligere strafferegistre) på internett. Denne delen krever høy spesialisering og kan ikke gjøres uten kunnskap.
Monolith Law Office er et advokatfirma som spesialiserer seg på omdømmeskade, med en administrerende advokat som er en tidligere IT-ingeniør og ansatte som spesialiserer seg på nettforskning som nevnt ovenfor. Vi vil forklare hvordan nettforskning skal utføres nedenfor.
Hva er Google-søkeresultater og deres begrensninger?
Basen for nettforskning er utvilsomt Google-søk. Imidlertid har søkeresultatene som vises når du søker etter nøkkelordene du vil finne på Google, for eksempel ved å søke etter “mitt navn arrestasjon” for å slette arrestasjonsartikler, begrensninger i tre betydninger.
Nettsider som er mål for Google-søk
På internett finnes det et “utall” nettsider. Selv om det teoretisk sett er umulig å måle det totale antallet nettsider på internett, er det en teori som sier at antallet “nettsteder” for øyeblikket er omtrent 1,8 milliarder.
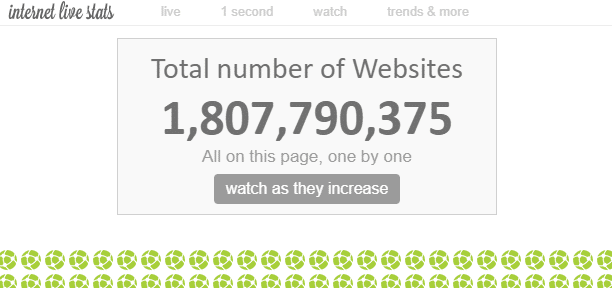
Siden det er flere nettsider innenfor ett nettsted, vil antallet nettsider være mye høyere enn dette.
Og Google-søk, for å si det enkelt, utføres ved hjelp av følgende mekanisme:
- Googles bot (Googlebot) skanner internett og oppdager nye nettsider som kan åpnes ved å følge lenker fra kjente nettsider
- Forstår innholdet på siden (indeksering)
- Når et søk utføres med nøkkelordene som er inkludert på siden, vises siden i søkeresultatene
Det jeg prøver å si er at det som vises i Google-søk er nettsider som Google har indeksert “på denne måten”, ikke “alle nettsider”. Med andre ord, så lenge du bruker Google-søk, kan du ikke finne nettsider som “Google ennå ikke har indeksert”, og det finnes ingen metode i denne verden for å søke gjennom alle nettsider på internett uten å gå glipp av noen.
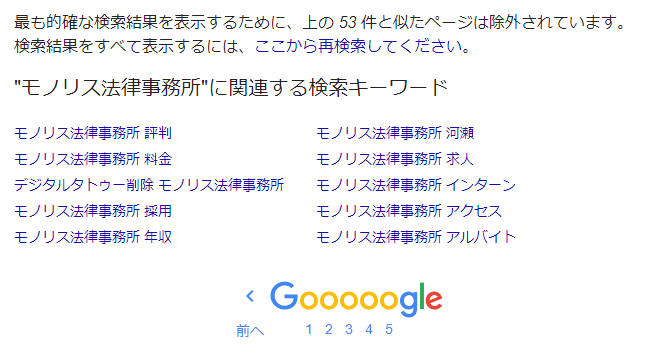
“Lignende” nettsider blir ekskludert fra søkeresultater
Google inkluderer ikke “alle nettsider som inneholder søkeordet og er indeksert” i søkeresultatene. Dette er noe du kanskje har lagt merke til hvis du bruker Google-søk regelmessig. På den siste siden av søkeresultatene vises meldingen “For å vise de mest relevante søkeresultatene, er sider som ligner på de ○ ovenfor ekskludert”.
For eksempel, hvis:
- En nyhet først blir publisert på en stor nyhetsside
- Nyhetsartikkelen blir deretter repostet på en nyhetssammendragstjeneste
- Artikkelen blir også repostet på personlige nettsteder
I slike tilfeller, for å unngå at søkeresultatene blir oversvømmet med sider med samme innhold, som kan være vanskelig for brukerne, ekskluderer Google “lignende” sider. I det ovennevnte eksempelet ville det være punkt 2 og 3.
Dette er ikke nødvendigvis en “brukervennlig” funksjon hvis du ønsker å fjerne alle sider med skadelig omtale. For eksempel, hvis den ovennevnte “nyheten” er en gammel arrestasjonsrapport om deg selv,
Hvis bare “1. Den opprinnelige artikkelen fra den store nyhetssiden” ble vist i søkeresultatene, og du sletter bare den siden, kan “2. Repostet artikkel på nyhetssammendragstjenesten” begynne å vises i Google-søkeresultatene fordi 1 er fjernet.
Dette er en mulig situasjon.
Dette problemet kan løses ved å klikke på “For å vise alle søkeresultater, søk på nytt her” i meldingen ovenfor, men hvis du ikke kjenner til denne funksjonen, kan du risikere å “overse” sider med skadelig omtale.
Det er en grense for antall artikler som vises fra samme nettsted

I tillegg har Google satt en grense for antall søkeresultatsider som vises fra ett enkelt nettsted. Denne spesifikasjonen er litt komplisert, men for å si det enkelt, “maksimalt to sider vises fra samme nettsted”.
For å forklare hva dette betyr, for eksempel, selv om det er fem Q&A der et selskaps eller en persons navn dukker opp på Yahoo! Chiebukuro (Yahoo! Answers), vil maksimalt to sider fra Yahoo! Chiebukuro vises i søkeresultatene når du søker etter det aktuelle selskapet eller personens navn på Google. Dette gjelder også for fora, selv om det er fem tråder på 5ch (et populært japansk forum) som inneholder et bestemt nøkkelord, vil maksimalt to vises i Google-søkeresultatene. For eksempel, hvis en person har,
- En artikkel om arrestasjon
- En artikkel om gjenarrestasjon
- En artikkel om en skyldig dom
og det er tre artikler på samme nyhetsside, vil minst en av dem (3-2=1) ikke vises i Google-søkeresultatene.
Når du søker etter et bestemt nøkkelord, hvis sider fra samme nettsted (for eksempel Yahoo! Chiebukuro, et bestemt forum, en bestemt nyhetsside, etc.) vises i stort antall i søkeresultatene, er det upraktisk for brukeren, så Google har denne spesifikasjonen.
Imidlertid er denne spesifikasjonen ikke nødvendigvis “brukervennlig” hvis du vil “fjerne alle sider med dårlig omdømme”.
For eksempel, hvis du vil fjerne negative Q&A fra Yahoo! Chiebukuro gjennom rettslige prosedyrer, og du ser på Google-søkeresultatene og bestemmer at “det er bare to mål”, og fortsetter med prosedyrene, vil en av de gjenværende tre (5-2=3) vises i søkeresultatene når slettingen er vellykket.
Avansert Google-søk ved bruk av “søkeuttrykk”
Av problemene nevnt ovenfor, er det spesielt det tredje problemet som krever bruk av Google-funksjonen “søkeuttrykk”.
Google har satt en grense på “grunnleggende 2 sider per nettsted” for sin funksjon som “søker etter sider som inneholder det aktuelle nøkkelordet fra hele internettet” (global søk). Men ved å bruke “søkeuttrykket” “nøkkelord site:målnettstedets URL”, kan du:
- Søke bare innenfor artiklene på det angitte målnettstedet
- Det er ingen “grunnleggende 2 sider per nettsted” grense for disse søkeresultatene
Dette lar deg utføre slike søk.
“Søkeuttrykk” er faktisk mer komplekse, og det finnes også søkeuttrykk som brukes for å løse andre problemer enn de nevnte ovenfor.
Spesial søkeverktøy for bestemte nettsteder
For eksempel har Yahoo! Chiebukuro (Yahoo! Answers) en unik søkefunksjon.
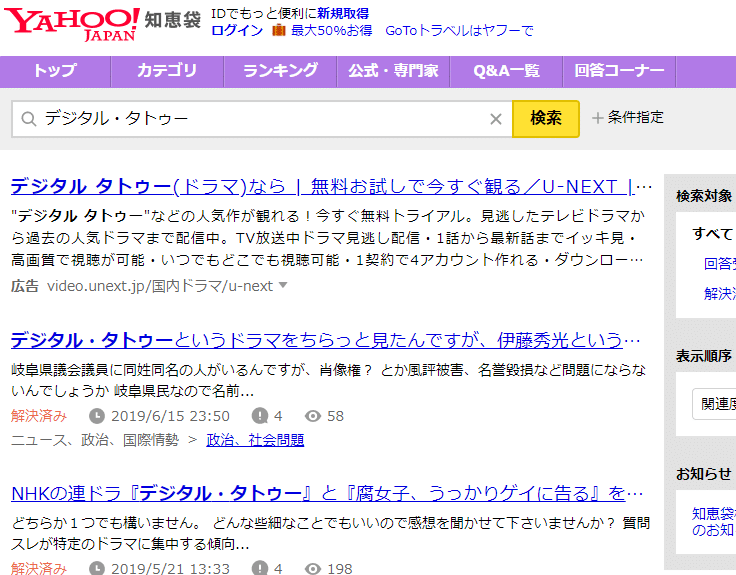
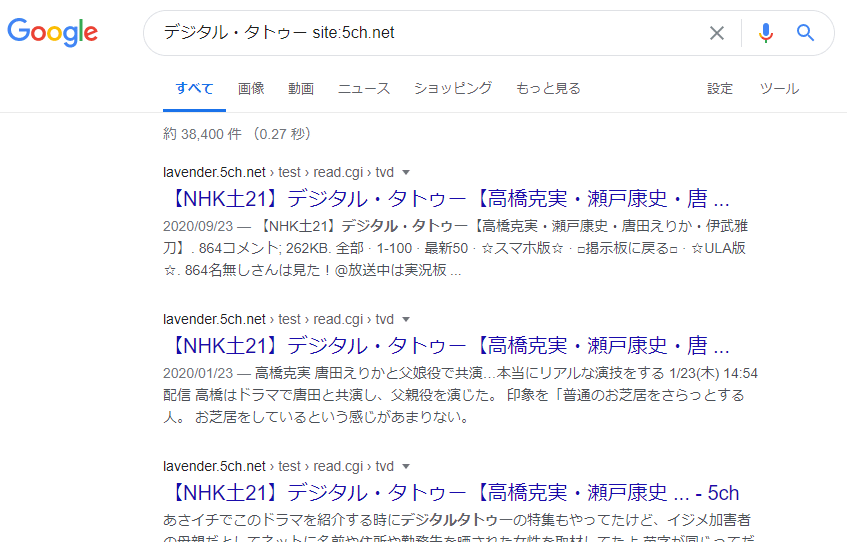
Dette søket er ikke basert på “websider som Google tilfeldigvis har indeksert”, men er resultatet av at “Yahoo! Chiebukuro’s søkeprogram direkte søker i Yahoo! Chiebukuro’s database”. Dette løser problemet vi nevnte tidligere, at “det finnes websider som Google ennå ikke har indeksert”. Med andre ord, hvis det er en side inne i Yahoo! Chiebukuro, kan du finne den uten å gå glipp av noe, så lenge du bruker søkefunksjonen i Yahoo! Chiebukuro.
Det vil si,
Når det gjelder en viss faktum (selskapets skandale, enkeltpersoners arrestasjon osv.), hvis en side på Yahoo! Chiebukuro blir funnet i et globalt søk, kan du lage en mer komplett liste ved å bruke søkefunksjonen i Yahoo! Chiebukuro, i stedet for å bruke “site:” søkeformelen.
Dette er poenget.
Dette gjelder også for Twitter. På grunn av naturen til tjenesten, er det ofte flere tweets om et bestemt emne (selskapets skandale, enkeltpersoners arrestasjon osv.) på Twitter. Ikke alle disse tweetene er nødvendigvis indeksert av Google, og de vises ikke nødvendigvis alle i et globalt søk.
Tellingsmetode for “1 sak” som skal slettes

Forholdet mellom en passende oppføring og “URL”
Til nå har vi skrevet om “hvordan finne så mange nettsider (URLer) som mulig ved hjelp av Google-søk”, men det betyr ikke nødvendigvis at det er bedre jo flere du kan liste opp. Dette er fordi målet for sletteforespørsler ikke nødvendigvis er “URL” som enhet.
I tilfellet med 5ch.net
Dette er et problem som spesielt oppstår i tilfelle av forumnettsteder (som 5ch.net, dets klon-nettsteder, og andre forumnettsteder).
For eksempel, hvis du søker etter et bestemt nøkkelord på Google med søkeformelen “site:5ch.net”, det vil si, søker innenfor 5ch.net, kan du få søkresultater som viser URLer som følgende:
- ○○○.5ch.net/test/read.cgi/○○/○○○○/40
- ○○○.5ch.net/test/read.cgi/○○/○○○○/1-100
- ○○○.5ch.net/test/read.cgi/○○/○○○○/30-
5ch.net har følgende funksjoner:
- Hvis du skriver inn responsnummeret etter tråd-URLen, vises bare den responsen
- Hvis du skriver inn et område av responsnumre som “A-B” etter tråd-URLen, vises bare responsene i det området
- Hvis du skriver inn et startpunkt for responsnummeret og “-” etter tråd-URLen, vises responsene fra det nummeret og utover
Med andre ord, selv om det bare er skrevet et nøkkelord i respons nummer 40, vil forskjellige URLer (websider) vises i “søkeresultatene”.
Men når du sender en sletteforespørsel til et forumnettsted, er enheten for forespørselen i det minste i prinsippet “respons”. Derfor, hvis du vil slette respons nummer 40, trenger du bare å trekke ut følgende URL:
- ○○○.5ch.net/test/read.cgi/○○/○○○○/40
Det er ikke nødvendig å liste opp de to siste.
I tilfellet med 5ch.net klon-nettsteder og sammendragsnettsteder
For å legge til, selv om det er litt komplisert, selv innenfor 5ch.net (og lignende), avhengig av nettstedet, kan enheten for sletteforespørselen være “side (tråd)” i stedet for “respons” for klon-nettsteder og “sammendragsnettsteder”. Hvilken enhet som er målet for sletteforespørselen for hvilket nettsted, er helt innenfor området “know-how”.
https://monolith.law/reputation/delation-of-scraping-site-roundup-website[ja]
Derfor,
- Forståelse av enheten for juridiske sletteforespørsler
- Forståelse av URL-spesifikasjonene for et bestemt nettsted (for eksempel har 5ch.net kompliserte regler som nevnt ovenfor)
Uten disse, vil det være vanskelig å “liste opp målene for sletting mens du ser på søkeresultatene”.
Søk utenfor åpen web

Vi har så langt forklart om nettsteder som Google potensielt kan indeksere, men det finnes også nettsteder som:
- Google definitivt ikke vil indeksere
- Men bør vurderes for fjerningsforespørsler som en del av omdømmehåndtering
Google indekserer kun nettsteder som er tilgjengelige for alle uten å logge inn (åpen web). Men det finnes også tjenester på nettet som lar deg søke og lese gamle avisartikler mot betaling (og derfor krever brukerregistrering og innlogging).
For eksempel, i tilfelle av fjerning av arrestasjonsartikler, er det nødvendig å nøye undersøke også disse avisdatabase-nettstedene. Dette er fordi mange selskaper som undersøker bedrifters eller individers kredittverdighet, bruker disse avisdatabase-nettstedene.
For mer informasjon om avisdatabase-nettsteder, se artikkelen nedenfor.
https://monolith.law/reputation/criminal-record-newspaper-database[ja]
Oppsummering
Som nevnt ovenfor, er det å “liste opp mål for fjerningsforespørsler på internett som et tiltak mot rykteskade” en svært spesialisert oppgave. Vårt firma utfører denne typen artikkellisting når vi håndterer rykteskade, men dette arbeidet forutsetter ekspertise innen IT og internett.
Fjerning av sider (eller foruminnlegg) på internett som et tiltak mot rykteskade er en oppgave som bare advokater kan utføre.
https://monolith.law/reputation/hiben-koui[ja]
Men på den annen side, er denne listingen, som hovedsakelig krever IT og internett kunnskap, en svært krevende oppgave, som forklart i denne artikkelen. Dette er en av de store grunnene til at man bør søke hjelp fra et advokatfirma med høy ekspertise innen IT og internett når man håndterer rykteskade. Hvis denne typen listing er slurvete, kan det føre til problemer som:
- Selv om alle listede sider er fjernet, kan andre sider som ikke ble vist i de globale søkeresultatene ved listingstidspunktet dukke opp i søkeresultatene, noe som krever ytterligere fjerning og gjør at det opprinnelige budsjettet er sterkt feilberegnet.
- Rettsprosedyrer som egentlig skulle ha vært løst i én omgang, kan kreve to eller tre omganger, noe som fører til overdrevne kostnader.
- Man kan overse eksistensen av sider utenfor det åpne nettet, som for eksempel nyhetsdatabaser, og dermed ikke løse “problemer” som at “det er vanskelig å få jobb på grunn av søk på arrestasjonsartikler”.
Dette er grunnen til at slike problemer kan oppstå.
Category: Internet