Kan generering av "stemmer" med AI føre til brudd på opphavsretten? (#2 Genererings- og bruksfasen)

Med utviklingen av generativ AI-teknologi har det blitt mulig å enkelt lære opp og generere ‘stemmer’ av eksisterende sangere og stemmeskuespillere. I forretningsverdenen har dette åpnet for muligheter som å lære opp generativ AI til å skape nye ‘stemmer’ i apputvikling, spillutvikling og animasjonsproduksjon.
Å lære opp generativ AI med ‘stemmer’ av eksisterende sangere og stemmeskuespillere for å skape nye ‘stemmer’, kan potensielt være en ulovlig handling, som for eksempel brudd på opphavsretten. Faktisk er tolkningen av slike problemer ikke klart definert i den nåværende situasjonen.
Her vil vi forklare potensialet for brudd på opphavsrett, tilgrensende rettigheter og publisitetsrettigheter i generering og bruk av ‘stemmer’ i generativ AI. Juridiske problemstillinger i utviklings- og opplæringsfasen er forklart i denne artikkelen (Artikkel #1 Utviklings- og opplæringsfasen)[ja]. Vi anbefaler at du også tar en titt på denne.
Tre bruksmønstre i genererings- og bruksfasen
Å si at man “genererer en stemme med generativ AI” krever at vi deler prosessen inn i følgende to faser:
- Utviklings- og treningsfasen
- Genererings- og bruksfasen
Fase 1 utføres av AI-utviklere, mens fase 2 utføres av AI-brukere.
Når vi visualiserer disse prosessene, ser det slik ut:
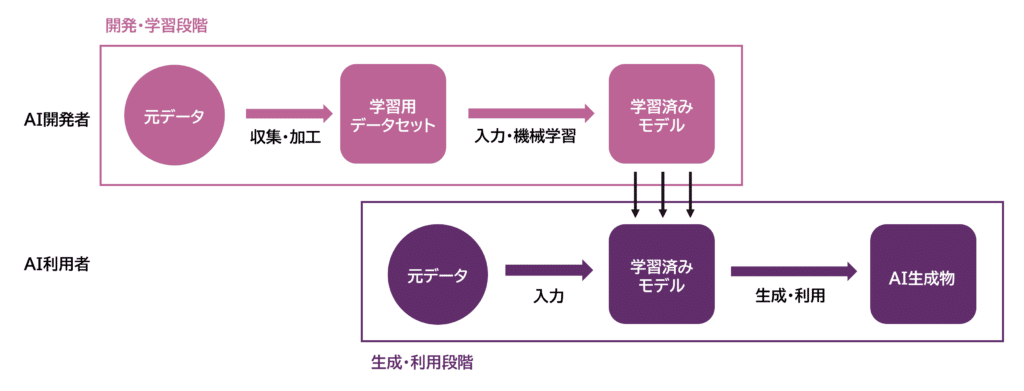
I utviklings- og treningsfasen samler og lagrer AI-utviklere rådata av menneskelige stemmer som treningsdata for AI-utvikling og skaper et treningsdatasett. Deretter mates treningsdatasettet inn i AI for maskinlæring, og en trent modell blir opprettet. Dette er vanligvis utført av AI-utviklere.
I genererings- og bruksfasen mates rådata inn i en generativ AI som har fullført maskinlæringen, og AI-genererte produkter blir skapt og brukt. Dette er vanligvis utført av AI-brukere.
For genererings- og bruksfasen kan vi forutse følgende tre bruksmønstre:
- Mønster 1: Handlingen med å mate en menneskelig stemme inn i AI for å generere et AI-produkt som er forskjellig fra den opprinnelige stemmedataen
- Mønster 2: Handlingen med å mate en menneskelig stemme inn i AI for å generere et AI-produkt som er identisk med eller ligner på den opprinnelige stemmedataen
- Mønster 3: Handlingen med å mate inn data som ikke er menneskelig stemmedata i AI for å generere et AI-produkt som er identisk med eller ligner på stemmedataen til en faktisk person
I det følgende vil vi kort forklare hvilke typer rettighetskrenkelser som potensielt kan oppstå fra hvert av disse bruksmønstrene.
Mønster 1: Inntasting av menneskestemmer i AI for å skape ulike genererte produkter

Først vil vi forklare mulige brudd på rettigheter som kan oppstå når menneskestemmer legges inn i AI for å skape genererte produkter som er forskjellige fra de opprinnelige stemmedataene.
Forholdet til opphavsrett
I mønster 1, forestill deg spesifikt en situasjon hvor en bestemt sangers stemmedata legges inn i en AI som kan identifisere hvilken sanger det er basert på stemmen, eller en situasjon hvor både en bestemt sangers stemme og AI-brukerens stemme legges inn samtidig for å generere stemmedata som ligner på den aktuelle sangeren.
Når det gjelder opphavsrett, blir det problematisk å legge inn eksisterende verk i AI. En slik handling faller under “informasjonsanalyse” (Opphavsrettsloven (heretter bare loven) Artikkel 30-4, nummer 2), og derfor kan opphavsrettsbeskyttede verk brukes på hvilken som helst måte så lenge det er innenfor grensene av hva som er nødvendig for informasjonsanalysen. Derfor, hvis det er nødvendig for informasjonsanalysen, vil ikke bruken av verkene utgjøre et brudd på opphavsretten så lenge det er innenfor de anerkjente grensene.
Forholdet til naborettigheter
I forhold til naborettigheter, siden Artikkel 102 anvender bestemmelsene i Artikkel 30-4 fra loven om opphavsrett, vil de ovennevnte inntastingshandlingene generelt ikke utgjøre et brudd på naborettighetene.
Forholdet til publisitetsrettigheter
I tilfellet med mønster 1, la oss anta at stemmen som legges inn i AI først, tilhører en bestemt kjent person. Når man bruker stemmedataene til en bestemt kjent person, vil handlinger som faller inn under de tre typene av brudd som ble forklart i første del (#1 Utviklings- og læringsfasen)[ja], utgjøre et brudd på publisitetsrettighetene og dermed være en ulovlig handling.
Imidlertid, selv om stemmedataene som legges inn denne gangen tilhører en bestemt kjent person, vil bruken av disse dataene bare være for inntasting og analyse i genererings-AI, og derfor ikke falle under de tre typene av brudd.
Dermed kan vi si at det ikke er rom for at denne bruken utgjør et brudd på publisitetsrettighetene.
Mønster 2: Inntasting av menneskelige stemmer i AI for å generere identiske eller lignende data
Mønster 2 innebærer å mate AI med en bestemt sangers stemmedata samt tekst- og melodidata, for å skape sangstemmedata med den aktuelle sangerens stemme. Dette kan grovt deles inn i tre handlinger:
- Inntasting av stemmedata i AI
- Generering av AI-produkter basert på disse dataene
- Bruk av de aktuelle AI-produktene
Med dette som utgangspunkt vil vi analysere forholdet til følgende rettigheter.
Forholdet til opphavsrett
Først og fremst, i forhold til opphavsrett, kan alle tre handlingene – inntasting, generering og bruk – innebære risiko for opphavsrettsbrudd.
For det første, når det gjelder inntastingen. Som med mønster 1, er inntastingen i prinsippet ikke et brudd på opphavsretten i henhold til artikkel 30-4 i den japanske opphavsrettsloven. Men det finnes et betydelig unntak fra denne regelen. Hvis formålet med å generere AI-produkter er å skape noe som har de essensielle uttrykksmessige egenskapene til originaldataene (et uttrykksproduksjonsformål), vil artikkel 30-4 ikke gjelde, og handlingen vil være ulovlig. I tilfellet med mønster 2, blir et uttrykksproduksjonsformål ofte bekreftet. Derfor er det en høy sannsynlighet for at det vil bli ansett som et opphavsrettsbrudd.
Deretter, når det gjelder genereringen. I mønster 2 blir det generert data som er identiske eller lignende med eksisterende opphavsrettsbeskyttet stemmedata, noe som utgjør et brudd på reproduksjonsretten (artikkel 21). Derfor er det en høy sannsynlighet for at det vil bli ansett som et opphavsrettsbrudd.
Til slutt, når det gjelder bruken. Bruken av data som er identiske eller lignende med eksisterende opphavsrettsbeskyttet materiale, som er generert i trinn 2, vil utgjøre et brudd på reproduksjonsretten (artikkel 21) eller retten til offentlig overføring (artikkel 23). Derfor er det en høy sannsynlighet for at det vil bli ansett som et opphavsrettsbrudd.
Forholdet til nærliggende rettigheter
I forhold til nærliggende rettigheter er det fortsatt praktiske og komplekse spørsmål som må vurderes, da de ennå ikke er avgjort.
I den nåværende situasjonen, som nevnt ovenfor, er artikkel 30-4, som regulerer opphavsrett, tilsvarende anvendt i henhold til artikkel 102, så risikoen for brudd på nærliggende rettigheter er generelt lav.
Forholdet til publisitetsrettigheter
Når det gjelder handlingene fra 1 til 3, er det lite rom for brudd på publisitetsrettigheter når det gjelder inntastingen og genereringen, da de ikke faller inn under de tre kategoriene av brudd.
Men når det gjelder bruken, hvis den aktuelle bruksmåten innebærer kommersiell bruk, som salg, vil det falle inn under de tre kategoriene av brudd, og dermed er det en høy sannsynlighet for at det vil bli ansett som et brudd på publisitetsrettigheter.
Mønster 3: Inndata til AI som ikke er stemmedata, genererer identiske eller lignende data som eksisterende personers stemmedata

Forholdet til opphavsrett
Mønster 3 innebærer for eksempel å angi et spesifikt stemmeskuespillernavn for å generere taledata for den aktuelle stemmeskuespilleren. Spørsmålet som oppstår er om AI-genererte verk har en avhengighet til eksisterende opphavsrettsbeskyttede verk.
Konklusjonen er at hvis en AI-bruker bevisst bruker AI med intensjonen om å generere et verk som er identisk med eller ligner et eksisterende opphavsrettsbeskyttet verk, anses det som at det foreligger en avhengighet.
For eksempel, hvis en AI-bruker genererer et AI-verk med det formål å etterligne en bestemt stemmeskuespillers stemme, vil dette falle inn under dette. Derfor er det en høy sannsynlighet for opphavsrettsbrudd i slike tilfeller.
Forholdet til nærliggende rettigheter
Selv om man bruker AI til å generere en fremføring som er identisk med eller ligner en eksisterende fremføring, vil ikke denne handlingen anses som en “innspilling” av den eksisterende fremføringen, og dermed ikke utgjøre et brudd på nærliggende rettigheter.
Forholdet til retten til publisitet
Når det gjelder retten til publisitet, oppstår problemer når den genererte stemmen brukes kommersielt. I praksis kan det tenkes mange detaljerte tilfeller, men det er nok å forstå konklusjonen.
Konklusjonen er at hvis en AI-bruker med hensikt genererer en stemme som er identisk med eller ligner stemmen til en bestemt kjent person, og deretter bruker denne identiske eller lignende stemmen, vil det utgjøre et brudd på retten til publisitet. Tilfeller der dette skjer utilsiktet er komplekse og inneholder fortsatt mye rom for diskusjon i praksis, så vi vil utelate dem fra denne artikkelen.
Oppsummering: Rådfør deg med eksperter om forholdet mellom generativ AI og opphavsrett
Vi har nå gjennomgått de juridiske rettighetene som menneskelige stemmer har, og de problematiske handlingene som kan oppstå ved bruk av disse rettighetene, med konkrete eksempler.
Når det gjelder de juridiske rettighetene til menneskelige stemmer, er det viktig å skille mellom ‘innhold’ og ‘lyd’, og å forstå betydningen av opphavsrett, nærliggende rettigheter og publisitetsrettigheter.
For de handlingene som kan være problematiske, må vi se nærmere på hva som spesifikt utgjør problemet. Når det gjelder å generere stemmer ved hjelp av generativ AI, er det mange diskusjoner både i praksis og i forretningsverdenen. Når du starter en ny virksomhet, bør du ta hensyn til de ovennevnte punktene og sørge for at du bruker generativ AI på en passende måte.
Relatert artikkel: Kan generering av ‘stemme’ med AI føre til brudd på opphavsretten? (#1 Utviklings- og læringsfasen)[ja]
Veiledning om tiltak fra vår advokatfirma
Monolith Advokatfirma har rik erfaring med IT, spesielt internett og juridiske tjenester i Japan. I de senere årene har generativ AI og intellektuell eiendomsrett, som opphavsrett, fått økt oppmerksomhet, og behovet for juridisk gjennomgang har blitt stadig viktigere. Vårt firma tilbyr løsninger relatert til intellektuell eiendom. Vennligst se nedenfor for detaljer i artikkelen.
Monolith Advokatfirmas tjenesteområder: IT- og immaterialrett for ulike selskaper[ja]
Category: IT




















