Предпосылки мер противдействия ущербу от негативных отзывов: методы анализа негативных статей в интернете

В случае, когда необходимо полностью очистить веб-страницы, связанные с прошлыми корпоративными скандалами, инцидентами, арестами или судимостью, первоначально необходимо составить список всех негативных страниц и публикаций без пропусков. Если вы не можете составить этот список, вы не сможете продвигать меры по управлению репутационными рисками, глядя на общий объем, и, например, в отношении судебных процедур, таких как временные меры или судебные разбирательства, возникает риск, что из-за пропуска придется проводить их дважды, хотя они должны были бы завершиться за один раз.
Однако составление списка всех веб-страниц и публикаций, упоминающих определенные факты (например, корпоративные скандалы, инциденты, аресты или судимости) в Интернете, никоим образом не является “простым”. Эта работа требует высокой специализации и невозможна без соответствующих навыков.
Юридическая фирма “Monolith” (Японская юридическая фирма “Monolith”), в которой работают бывшие IT-инженеры и специалисты по интернет-исследованиям, как указано выше, является юридической фирмой, специализирующейся на управлении репутационными рисками. В следующем мы объясним, как должны проводиться интернет-исследования.
Что такое результаты поиска Google и их ограничения?
Основой интернет-исследований, безусловно, является поиск в Google. Однако результаты поиска в Google по ключевым словам, которые вы хотите найти, например, в случае удаления статей об аресте, таких как “мое имя арест”, имеют ограничения в трех аспектах.
Веб-страницы, которые попадают в поиск Google
В интернете существует «бесчисленное» количество веб-страниц. Теоретически невозможно измерить общее количество веб-страниц в интернете, но по некоторым данным, количество «веб-сайтов» на данный момент составляет около 1,8 миллиарда.
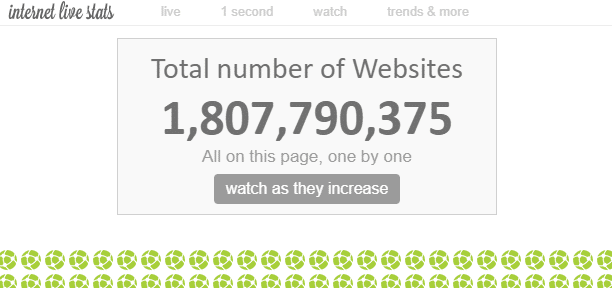
Поскольку на одном веб-сайте может быть несколько веб-страниц, количество веб-страниц значительно превышает это число.
А поиск Google, говоря простыми словами, работает следующим образом:
- Бот Google (Googlebot) сканирует интернет, обнаруживая новые веб-страницы, которые можно открыть, следуя по ссылкам из уже известных веб-страниц
- Определяет содержание этой страницы (регистрация в индексе)
- При поиске по ключевым словам, содержащимся на этой странице, отображает эту страницу в результатах поиска
То, что я хочу сказать, это то, что страницы, которые отображаются в поиске Google, это в конечном итоге «веб-страницы, которые Google зарегистрировал в индексе таким образом», а не «все веб-страницы». То есть, пока вы используете поиск Google, вы не сможете найти «веб-страницы, которые Google еще не зарегистрировал в индексе», и вообще, не существует способа, который позволил бы найти все веб-страницы в интернете без исключения.
“Похожие” веб-страницы исключаются из результатов поиска
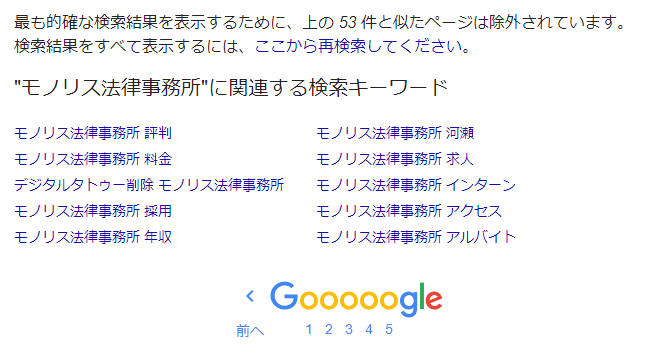
Google не отображает в результатах поиска “все веб-страницы, содержащие ключевые слова поиска, зарегистрированные в индексе”. Это может быть заметно, если вы обычно используете поиск Google. Это проявляется в сообщении, отображаемом на последней странице результатов поиска: “Чтобы показать наиболее точные результаты поиска, страницы, похожие на ○ выше, исключены”.
Например,
- Новость впервые распространяется на крупном новостном сайте
- Затем она перепечатывается на сервисах, которые собирают новостные статьи
- И далее перепечатывается на личных сайтах и т.д.
В таких случаях, если страницы с одинаковым содержанием заполняют результаты поиска, это затрудняет использование для пользователей. Поэтому Google автоматически исключает “похожие” страницы из результатов поиска, в данном случае пункты 2 и 3.
Это не всегда “удобно” для тех, кто хочет “очистить” страницы с негативной репутацией. Например, если вышеупомянутая “новость” – это статья о вашем прошлом аресте,
Если в результатах поиска отображалась только “1. Статья, впервые опубликованная на крупном новостном сайте”, и вы удалили только эту страницу, то после удаления 1, “2. Статья, перепечатанная на сервисе сбора новостей” начинает отображаться в результатах поиска Google.
Такая ситуация вполне возможна.
Эту проблему можно решить, нажав на ссылку “Чтобы показать все результаты поиска, перезапустите поиск здесь” в вышеупомянутом сообщении. Однако, если вы не знаете об этой функции, вы можете “пропустить” страницы с негативной репутацией.
Существует ограничение на количество статей, отображаемых с одного и того же сайта

Кроме того, Google устанавливает ограничение на количество страниц результатов поиска, отображаемых с одного веб-сайта. Эта функция немного сложна, но если говорить просто, “максимальное количество страниц, отображаемых с одного сайта, составляет 2”.
Что это значит? Например, даже если на Yahoo!知恵袋 (Японский Yahoo! Answers) есть 5 вопросов и ответов, в которых упоминается имя компании или человека, в результатах поиска Google для этого имени компании или человека отображаются максимум 2 страницы из Yahoo!知恵袋. То же самое относится и к форумам: даже если есть 5 тем на 5chan (японский аналог 4chan), в которых содержится определенное ключевое слово, в результатах поиска Google отображаются максимум 2 из них. Кроме того, например, если один и тот же человек имеет:
- Статью об аресте
- Статью о повторном аресте
- Статью о приговоре виновным
и все три статьи находятся на одном и том же новостном сайте, то по крайней мере одна из них (3-2=1) не будет отображаться в результатах поиска Google.
Если при поиске определенного ключевого слова страницы с одного и того же сайта (например, Yahoo!知恵袋, определенный форум, определенный новостной сайт и т.д.) занимают большую часть результатов поиска, это может быть неудобно для пользователя, поэтому Google использует такую функцию.
Однако, эта функция не всегда “удобна”, особенно если вы хотите “полностью очистить страницы с негативной репутацией”.
Например, если вы хотите удалить негативные вопросы и ответы с Yahoo!知恵袋 через судебные процедуры, и смотрите на результаты поиска Google, решая, что “есть только два объекта”, и продолжаете процедуру, то после успешного удаления одна из оставшихся 3 из 5-2=3 может начать отображаться в результатах поиска.
Продвинутый поиск в Google с использованием «поисковых операторов»
Среди вышеупомянутых проблем, особенно для решения третьей проблемы, необходима функция Google, называемая «поисковыми операторами».
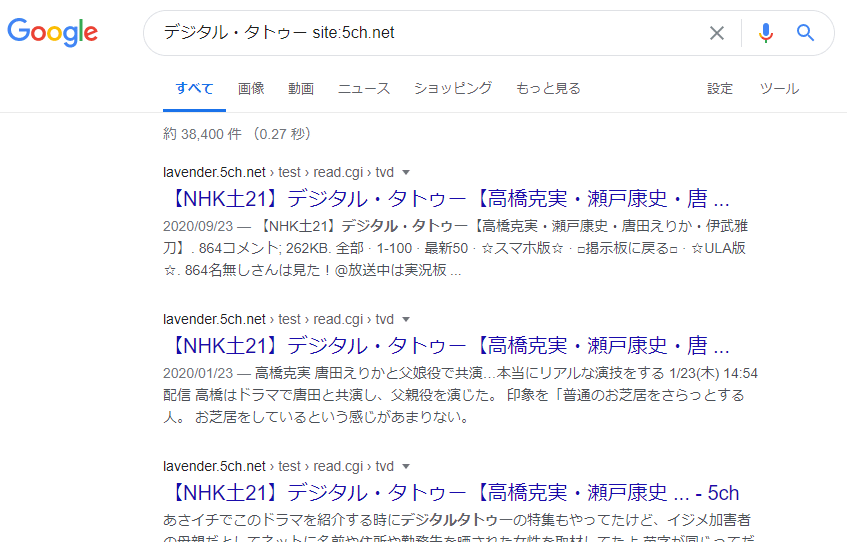
Google действительно устанавливает ограничение в «2 страницы на сайт» для функции «поиск страниц, содержащих данный ключевой запрос, по всему Интернету» (глобальный поиск). Однако, если вы используете «поисковый оператор» в формате «ключевое слово site:URL целевого сайта», вы можете выполнить поиск, который:
- Выполняет поиск только в статьях указанного целевого сайта
- В результаты поиска не применяется ограничение «2 страницы на сайт»
Таким образом, вы можете выполнить поиск.
«Поисковые операторы» на самом деле гораздо сложнее, и существуют и другие поисковые операторы, которые используются для решения проблем, отличных от вышеупомянутых.
Специальные средства поиска для конкретных сайтов
Например, на Yahoo!知恵袋 (Японский Yahoo! Answers) существует уникальная функция поиска.
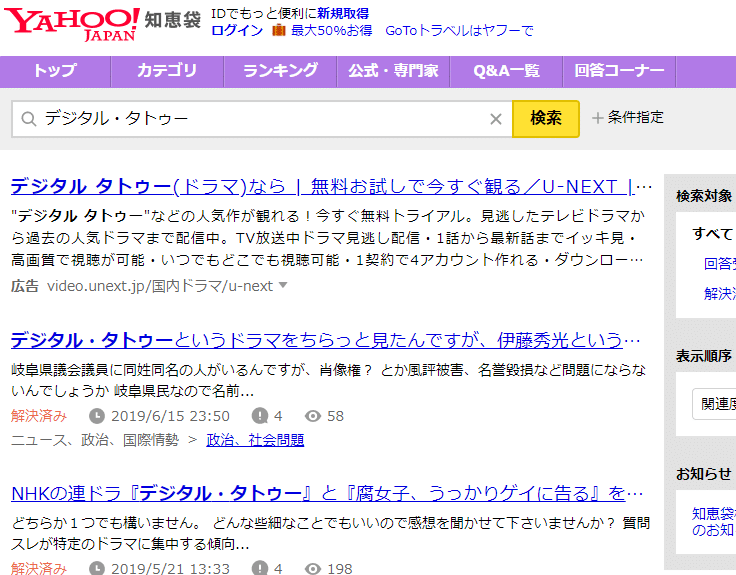
Этот поиск не основан на “веб-страницах, которые Google случайно зарегистрировал в индексе”, а на “результатах поиска, которые программа поиска Yahoo!知恵袋 напрямую проводит в базе данных Yahoo!知恵袋”. Это решает проблему, о которой мы говорили вначале, что “существуют веб-страницы, которые Google еще не зарегистрировал в индексе”. Это означает, что “если это страница внутри Yahoo!知恵袋, вы можете найти все без пропусков, используя только функцию поиска Yahoo!知恵袋”.
То есть,
Если страницы Yahoo!知恵袋 были обнаружены в глобальном поиске по какому-либо факту (несчастный случай в компании, арест человека и т.д.), использование функции поиска внутри Yahoo!知恵袋 позволит вам составить более полный список, чем использование формулы поиска “site:”.
Вот что это значит.
То же самое относится и к Twitter. По своей природе, на Twitter часто бывает множество твитов о фактах, ставших темой обсуждения (несчастный случай в компании, арест человека и т.д.). Не все эти твиты обязательно зарегистрированы в индексе Google, и не все они обязательно отображаются в глобальном поиске.
Метод подсчета “1 единицы” для удаления

Связь между правильным списком и «URL»
До сих пор мы говорили о «методах сбора как можно большего количества веб-страниц (URL) с помощью Google и других поисковых систем», но это не означает, что чем больше страниц вы соберете, тем лучше. Потому что целью запроса на удаление не всегда является «URL».
В случае с 5ch.net
Это становится проблемой, особенно на форумах (как 5ch.net, его копии и другие подобные сайты).
Например, если вы ищете определенное ключевое слово в Google с помощью формулы поиска «site:5ch.net», то есть, ищете внутри 5ch.net, в результатах поиска могут отображаться URL вида:
- ○○○.5ch.net/test/read.cgi/○○/○○○○/40
- ○○○.5ch.net/test/read.cgi/○○/○○○○/1-100
- ○○○.5ch.net/test/read.cgi/○○/○○○○/30-
На 5ch.net:
- Если после URL темы указать номер ответа, отобразится только этот ответ
- Если после URL темы указать диапазон номеров ответов в формате «A-B», отобразятся только ответы в этом диапазоне
- Если после URL темы указать номер ответа и «-», отобразятся все ответы, начиная с этого номера
То есть, если ключевое слово указано только в ответе под номером 40, различные URL (веб-страницы) будут отображаться в «результатах поиска».
Однако, когда вы подаете запрос на удаление на форум, единицей для запроса, по крайней мере в принципе, является «ответ». Следовательно, если вы хотите удалить ответ под номером 40, достаточно выделить только
- ○○○.5ch.net/test/read.cgi/○○/○○○○/40
URL, и вам не нужно включать в список два других.
В случае с копиями 5ch.net и агрегаторами
К тому же, хотя это и сложнее, но даже на 5ch.net (и подобных сайтах), на копиях сайта и «агрегаторах», единицей для запроса на удаление может быть не «ответ», а «страница (тема)». «Что является объектом запроса на удаление на каком сайте» полностью входит в область «навыков».
https://monolith.law/reputation/delation-of-scraping-site-roundup-website[ja]
Поэтому,
- Понимание единицы юридического запроса на удаление
- Понимание спецификации URL определенного веб-сайта (например, на 5ch.net есть сложные правила, как указано выше)
необходимо для того, чтобы «составить список объектов для удаления, просматривая результаты поиска».
Поиск вне открытого веба

До сих пор мы говорили о сайтах, которые Google может индексировать, но также существуют сайты:
- которые Google точно не будет индексировать,
- однако они должны быть рассмотрены в качестве объектов для запросов на удаление в рамках управления репутационным риском.
Google, по своей спецификации, не рассматривает в качестве объектов поиска ничего, кроме сайтов открытого веба, которые любой может просмотреть без входа в систему. Однако, например, в этом мире существуют такие вещи, как “платные веб-сервисы, которые позволяют искать и просматривать архивные статьи из газет (и, следовательно, которые нельзя просмотреть без регистрации пользователя или входа в систему)”.
Например, в случае удаления статей об арестах, необходимо тщательно проверить и сайты баз данных газет. Это связано с тем, что многие компании, занимающиеся исследованием кредитоспособности компаний и частных лиц, часто используют эти сайты баз данных газет.
Подробнее о сайтах баз данных газет мы рассказываем в следующей статье.
https://monolith.law/reputation/criminal-record-newspaper-database[ja]
Вывод
Как видно из вышеизложенного, составление списка объектов для удаления в рамках борьбы с репутационным риском в интернете – это очень специализированная задача. Наша юридическая фирма выполняет такую работу при оказании услуг по управлению репутационным риском, и эта работа предполагает наличие специализированных знаний в области IT и интернета.
Удаление страниц (или сообщений на форумах) в рамках борьбы с репутационным риском в интернете – это задача, которую может выполнить только адвокат.
https://monolith.law/reputation/hiben-koui[ja]
Однако, с другой стороны, составление этого списка – это задача, которая, как объясняется в этой статье, требует очень высокого уровня знаний в области IT и интернета. Это одна из важных причин, по которой стоит обратиться за услугами по управлению репутационным риском к юридической фирме, обладающей высокой специализацией в области IT и интернета. Если составление такого списка будет недостаточно тщательным, это может привести к следующим проблемам:
- Даже если вы полностью очистите список страниц, другие страницы, которые не отображались в глобальных результатах поиска во время составления списка, могут появиться в результатах поиска, и потребуется дополнительное удаление, что приведет к значительному превышению первоначального бюджета.
- В отношении судебных процедур, которые изначально должны были быть завершены за один раз, может потребоваться два или три раза, что приведет к необходимости значительных затрат.
- Вы можете не заметить существование страниц вне открытого веба, таких как сайты баз данных газет, и, например, “проблема” с “трудностями при трудоустройстве из-за поиска статей об аресте” не будет решена.
Вот почему возникают такие проблемы.
Category: Internet
Related Articles

Что такое «Ложные заявления о нарушении интеллектуальной собственности» на Amazon? Обзор юридиче.
Internet
Разбираем примеры скандалов с корпоративными аккаунтами Instagram! Меры предотвращения и реагиро.
Internet




Какие случаи онлайн-диффамации могут быть квалифицированы как преступления по ущемлению чести и .
Internet

Два способа борьбы с нарушением авторских прав на YouTube: что такое уведомление об удалении и з.
Internet













