Kan generering af "stemmer" med AI udgøre en krænkelse af ophavsretten? (#1 Udviklings- og læringsfase)

Udviklingen af generativ AI har gjort det muligt at lære og generere ‘stemmer’ af eksisterende sangere og stemmeskuespillere med lethed. I forretningsverdenen er det nu muligt at lære AI ‘stemmer’ og skabe nye ‘stemmer’ i forbindelse med appudvikling, spilskabelse og animeproduktion.
At lære en generativ AI ‘stemmer’ af eksisterende sangere og stemmeskuespillere og skabe nye ‘stemmer’ kan potentielt være en overtrædelse af ophavsretten eller andre ulovlige handlinger under japansk lov.
I virkeligheden er der endnu ikke kommet en klar fortolkning af disse problemer. Hvad er de juridiske rettigheder forbundet med en ‘stemme’, og hvornår kan det blive et problem under den japanske ophavsretslov?
I denne og den følgende artikel vil vi forklare dette problem ved at antage specifikke anvendelsesmønstre. I denne første del vil vi forklare om potentielle rettighedskrænkelser i udviklings- og læringsfasen af generativ AI. Juridiske problemstillinger i forbindelse med generering og brug vil blive forklaret i denne artikel (#2 Generering og brugsfasen)[ja]. Vi opfordrer dig til at læse begge artikler.
Tre juridiske rettigheder omkring menneskers ‘stemme’ under japansk lov
Hvilke juridiske rettigheder har menneskers ‘stemme’? For at overveje dette spørgsmål er det nødvendigt at have to perspektiver på ‘stemmen’:
- Hvad stemmen siger,
- Hvordan stemmen lyder.
Med andre ord kan vi skelne mellem det første punkt, som er et spørgsmål om ‘stemmens’ indhold, og det andet punkt, som er et spørgsmål om ‘stemmens’ lyd.
For eksempel, hvis forskellige stemmeskuespillere siger replikken ‘godmorgen’, vil det første punkt, indholdet, være det samme, mens det andet punkt, lyden, vil være forskellig.
Ud fra disse perspektiver kan vi under gældende japansk lovgivning identificere følgende tre juridiske rettigheder, der kan opstå i forbindelse med menneskers ‘stemme’:
| ① Ophavsret | Kan opstå i forbindelse med ‘stemmens’ indhold |
| ② Nærliggende rettigheder (begrænset til udøvende kunstneres rettigheder) | Kan opstå i forbindelse med både ‘stemmens’ indhold og lyd |
| ③ Publicitetsret | Kan opstå i forbindelse med ‘stemmens’ lyd |
Om Ophavsret i Japan
Ophavsret opstår, når indholdet af en stemme kvalificerer sig som et værk under den japanske ophavsretslov.
For eksempel, hvis man oplæser en berømt roman, kan der opstå ophavsret på stemmen. Det vigtige at bemærke her er, at ophavsretsindehaveren i sådanne tilfælde er forfatteren af romanen, og ikke “stemmens ejer = den person, der taler”. Det betyder, at hvis man skaber en syntetisk stemme, der oplæser indholdet af en berømt roman ved hjælp af genereret AI, kan denne handling potentielt krænke romanforfatterens ophavsret.
Derimod, hvis indholdet af en stemme er almindelig dagligdags samtale fra en almindelig person, opstår der ikke ophavsret på stemmen. Dette skyldes, at almindelig dagligdags samtale i sig selv ikke betragtes som et værk og derfor ikke er beskyttet af ophavsretsloven.
Om Nærliggende Ophavsrettigheder Under Japansk Lov
Nærliggende ophavsrettigheder (begrænset til rettigheder for udøvende kunstnere) kan opstå, når indholdet af en stemme anses for at være et værk, og denne stemme ledsages af en form for fremførelse, såsom oplæsning.
Som nævnt i ovenstående afsnit om ophavsret, kan en oplæser opnå nærliggende ophavsrettigheder, fordi vedkommende udfører en “fremførelse” i form af oplæsning. Det er vigtigt at bemærke, at i modsætning til ophavsretsindehaveren, er indehaveren af de nærliggende ophavsrettigheder ikke forfatteren af romanen, men derimod den person, der faktisk udfører oplæsningen.
Om Publicitetsrettigheder i Japan
Publicitetsrettigheder refererer til retten til eksklusivt at udnytte den kundetiltrækningskraft, som en persons navn, billede osv. besidder. Denne ret er anerkendt af præcedensretten (Højesteretsdom H24 (2012).2.2).
| ▶︎Højesteretsdom H24 (2012).2.2 (Pink Lady-sagen) ■Domstolens afgørelse ①Når et navn, et billede osv. anvendes som et selvstændigt produkt, der kan betragtes, ②Når et navn, et billede osv. anvendes med det formål at differentiere produkter, ③Når et navn, et billede osv. anvendes som reklame for produkter, og formålet udelukkende er at udnytte den kundetiltrækningskraft, som navnet eller billedet besidder, vil det udgøre en krænkelse af publicitetsrettighederne og være ulovligt som en ulovlig handling ■Kommentar fra undersøgelsesdommeren (Højesterettens årsberetning om civilretlige afgørelser for året H24 (2012), del 1, side 18) Udtrykket “billede osv.” i denne afgørelse refererer til personlig identifikationsinformation, og kan for eksempel inkludere autografer, underskrifter, stemmer, pseudonymer, kunstnernavne osv. |
Ifølge Pink Lady-sagen kan der også opstå publicitetsrettigheder for en stemme. Hvis det kan fastslås, at den pågældende stemme tilhører en person med kundetiltrækningskraft, som en faktisk stemmeskuespiller, skuespiller, sanger osv., vil publicitetsrettigheder opstå uafhængigt af “indholdet”. Og hvis den pågældende stemme anvendes på en af de tre måder, som blev fastslået i Pink Lady-sagen, vil det udgøre en krænkelse af publicitetsrettighederne.
Tre anvendelsesmønstre i udviklings- og læringsfasen
At sige “at generere en stemme med generativ AI” kræver en opdeling af processen i følgende to faser:
- Udviklings- og læringsfasen
- Genererings- og anvendelsesfasen
Fase 1 udføres af AI-udviklere, mens fase 2 udføres af AI-brugere.
Når disse processer visualiseres, ser det ud som følger:
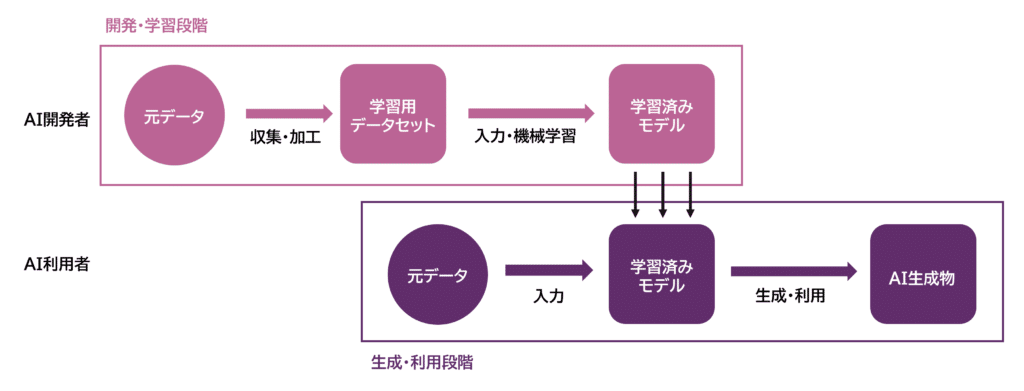
I udviklings- og læringsfasen indsamler og lagrer man menneskelige stemmedata som læringsdata for AI-udvikling og skaber et datasæt til læring. Derefter indføres dette læringsdatasæt i AI’en for at udføre maskinlæring og skabe en trænet model. I genererings- og anvendelsesfasen indføres de oprindelige data i den generative AI, som har gennemgået maskinlæring, for at generere og anvende AI-produkter.
Der kan forventes følgende tre anvendelsesmønstre i udviklings- og læringsfasen:
- Mønster 1: Indsamling, lagring, bearbejdning og anvendelse af menneskelige stemmedata som læringsdata for AI-udvikling
- Mønster 2: Salg eller offentliggørelse af læringsdatasæt anvendt i AI-udvikling
- Mønster 3: Salg eller offentliggørelse af den generative AI selv
I det følgende vil vi kort forklare, hvilke potentielle rettighedskrænkelser der kan opstå i hvert af disse anvendelsesmønstre.
Mønster 1: Indsamling, oplagring, bearbejdning og anvendelse af menneskelige stemmedata til træning af AI

Først vil vi forklare de potentielle krænkelser af rettigheder, der kan opstå i forbindelse med indsamling, oplagring, bearbejdning og anvendelse af menneskelige stemmedata til træning af AI.
Forholdet til ophavsret
I mønster 1 refererer de anvendte handlinger specifikt til udviklingen af selve generativ AI. AI-udvikling falder under ‘informationsanalyse’ i henhold til artikel 30-4, punkt 2, i den japanske ophavsretslov (herefter forkortet), og derfor betragtes brugen af nødvendige ophavsretligt beskyttede værker som principielt ikke at være en krænkelse af ophavsretten (artikel 30-4).
Der er dog en væsentlig undtagelse. Hvis formålet med at skabe et træningsdatasæt er at generere AI-produkter, der har de essentielle udtryksmæssige karakteristika fra de oprindelige data (med henblik på udtryksoutput), så gælder artikel 30-4 ikke, og handlingen vil være ulovlig.
Det betyder, at hvis man bruger stemmedata fra andre stemmeskuespillere med det formål at reproducere eller hylde en bestemt stemmeskuespillers karakteristiske stemme, kan denne brug betragtes som en krænkelse af ophavsretten, fordi der er et formål med udtryksoutput.
Forholdet til naborettigheder
I forhold til naborettigheder anvendes bestemmelserne i ophavsretslovens artikel 30-4 også i henhold til artikel 102, så udviklingen af generativ AI, selv når den involverer liveoptræden, er som hovedregel ikke en krænkelse af naborettighederne.
Forholdet til retten til offentliggørelse
Spørgsmålet om krænkelse af retten til offentliggørelse bliver relevant, når udviklingen af generativ AI, der har til formål at skabe en bestemt berømtheds ‘stemme’, overvejes.
For at afgøre, om der er tale om en krænkelse af retten til offentliggørelse, kan de tre typer af krænkelser, der blev identificeret i den såkaldte Pink Lady-sag, tjene som reference.
Først og fremmest falder selve handlingen med at udvikle generativ AI med det formål at skabe en bestemt berømtheds ‘stemme’ ikke ind under de tre typer af krænkelser, der blev identificeret i Pink Lady-sagen. Men hvis handlingen udelukkende har til formål at udnytte den kundetiltrækkende kraft, som et navn eller et billede besidder, kan det udgøre en krænkelse af retten til offentliggørelse og dermed være en ulovlig handling.
For at udnyttelsen af kundetiltrækkende kraft kan finde sted, er det nødvendigt, at tredjeparter kan genkende, at det er den pågældende berømtheds stemme, når de skaber datasættet til træning. Hvis tredjeparter, som er kunder, ikke kan genkende dette, kan der ikke opstå nogen kundeattraktion. Men normalt er der ikke plads til, at tredjeparter, som er kunder, involveres i udviklingsfasen af generativ AI.
Derfor kan det siges, at der næsten ikke er nogen mulighed for, at sådan en brug vil udgøre en krænkelse af retten til offentliggørelse.
Mønster 2: Salg og offentliggørelse af træningsdatasæt anvendt i AI-udvikling
Her forklarer vi om mulige krænkelser af rettigheder, der kan opstå i forbindelse med salg og offentliggørelse af AI-træningsdatasæt.
Forholdet til ophavsret
Hvis det oprindelige data i et træningsdatasæt er gemt i sin oprindelige form eller i en let modificeret form, kan salg og offentliggørelse af træningsdatasættet udgøre en krænkelse af overdragelsesretten (artikel 26, paragraf 2) eller offentliggørelsesretten (artikel 23) for det pågældende værk eller et afledt værk (artikel 28). Derfor vil det uden ophavsmandens samtykke udgøre en krænkelse af ophavsretten.
Ikke desto mindre, som nævnt ovenfor, tillader artikel 30, paragraf 4, brug “til informationsanalyse” i det omfang det anses for nødvendigt, uanset metoden. Således udgør overdragelse eller offentliggørelse til udvikling af generativ AI ikke en krænkelse af ophavsretten, så længe det er inden for det nødvendige omfang.
Forholdet til beslægtede rettigheder
Ligesom ovenfor er artikel 30, paragraf 4, som omhandler ophavsret, gjort anvendelig ved artikel 102, så salg og offentliggørelse af træningsdatasæt til udvikling af generativ AI udgør i princippet ikke en krænkelse af beslægtede rettigheder.
Forholdet til retten til offentlighed
Inden for træningsdatasættene findes der data, der kan afspille stemmer af specifikke berømtheder i deres oprindelige form. Men træningsdatasæt anvendes normalt kun til udvikling af generativ AI og kan ikke betragtes som brug af “navn, portræt osv. som et selvstændigt objekt for beundring i varer osv.”, som det blev fastslået i den endelige dom i Pink Lady-sagen.
Derfor kan det siges, at der næsten ikke er nogen mulighed for, at den pågældende brug udgør en krænkelse af retten til offentlighed.
Mønster 3: Salg og offentliggørelse af selve genererings-AI’en

Her vil vi forklare om mulige krænkelser af rettigheder, der kan opstå i forbindelse med salg og offentliggørelse af selve den trænede model.
Forholdet til ophavsret
I modsætning til datasæt til træning kan man ikke forestille sig, at den trænede model af en genererings-AI indeholder dele af det oprindelige data (værker) med kreativitet. Derfor kan det siges, at selve genererings-AI’en, det vil sige den trænede model, ikke udgør et sekundært ophavsretligt værk, og at offentliggørelse og salg af disse ikke udgør en krænkelse af ophavsretten.
Forholdet til beslægtede rettigheder
Ligesom ovenfor kan man ikke forestille sig, at den trænede model indeholder dele af det oprindelige data med kreativitet, og derfor kan det siges, at salg og offentliggørelse af selve genererings-AI’en ikke krænker de beslægtede rettigheder.
Forholdet til publicitetsret
Selv en AI, der kan generere en bestemt berømtheds stemme frit og med høj præcision, falder klart uden for de tre typer af krænkelser, som blev fastslået i den øverste domstols afgørelse i Pink Lady-sagen. Det er dog almindeligt, at sådan en AI tiltrækker kunder ved at værdisætte evnen til at generere en bestemt berømtheds stemme frit og med høj præcision, og kunderne køber typisk den pågældende AI af samme grund. Derfor kan salget af en sådan AI sandsynligvis udgøre en krænkelse af publicitetsretten som en lignende handling til de tre typer af krænkelser.
Konklusion: Søg rådgivning hos en ekspert angående forholdet mellem generativ AI og ophavsret
Indtil nu har vi forklaret de juridiske rettigheder, der er forbundet med menneskelige stemmer, og de handlinger, der kan udgøre problemer, når disse rettigheder anvendes, baseret på konkrete eksempler.
Det er vigtigt at forstå, at de juridiske rettigheder til en persons stemme skal overvejes både i forhold til ‘indhold’ og ‘lyd’, og at det er væsentligt at overveje ophavsret, beslægtede rettigheder og publicitetsrettigheder. I denne første del har vi fokuseret på udviklings- og læringsfasen, men i den næste del vil vi forklare genererings- og anvendelsesfasen.
Relateret artikel: Kan generering af ‘stemme’ med AI medføre ophavsretskrænkelser? (#2 Genererings- og anvendelsesfasen)[ja]
Vejledning i foranstaltninger fra vores advokatfirma
Monolith Advokatfirma er et advokatfirma med omfattende erfaring inden for IT og juridiske tjenester, især på internettet. I de senere år har generativ AI og intellektuel ejendomsret, herunder ophavsret, tiltrukket sig stor opmærksomhed, og behovet for juridisk gennemgang er stigende. Vores firma tilbyder løsninger relateret til intellektuel ejendomsret. Yderligere detaljer er angivet i artiklen nedenfor.
Monolith Advokatfirmas ekspertiseområder: IT- og intellektuel ejendomsret for forskellige virksomheder[ja]
Category: IT




















