Kan generering af "stemmer" med AI udgøre en krænkelse af ophavsretten? (#2 Genererings- og anvendelsesfasen)

Med udviklingen af generativ AI-teknologi er det blevet muligt let at lære og generere ‘stemmer’ af eksisterende sangere og stemmeskuespillere. I forretningsverdenen er det nu muligt at lære generativ AI ‘stemmer’ og skabe nye ‘stemmer’ i situationer som appudvikling, spiludvikling og animeproduktion.
At lære en generativ AI ‘stemmer’ af eksisterende sangere og stemmeskuespillere og skabe nye ‘stemmer’ kan potentielt være en overtrædelse af ophavsretten eller andre ulovlige handlinger. Faktisk er fortolkningen af sådanne problemer endnu ikke klart defineret i den nuværende situation.
Her vil vi forklare muligheden for krænkelse af ophavsret, beslægtede rettigheder og publicitetsrettigheder i forbindelse med generering og brug af generativ AI. Juridiske problemstillinger i udviklings- og læringsfasen er forklaret i denne artikel (#1 Udviklings- og læringsfasen)[ja]. Vi opfordrer dig til at læse dem i sammenhæng.
Tre anvendelsesmønstre i genererings- og brugsfasen
Når vi taler om at “generere stemmer med generativ AI”, er det nødvendigt at opdele processen i følgende to faser:
- Udviklings- og læringsfasen
- Genererings- og brugsfasen
Fase 1 udføres af AI-udviklere, mens fase 2 udføres af AI-brugere.
Når vi skematisk fremstiller disse faser, ser det ud som følger:
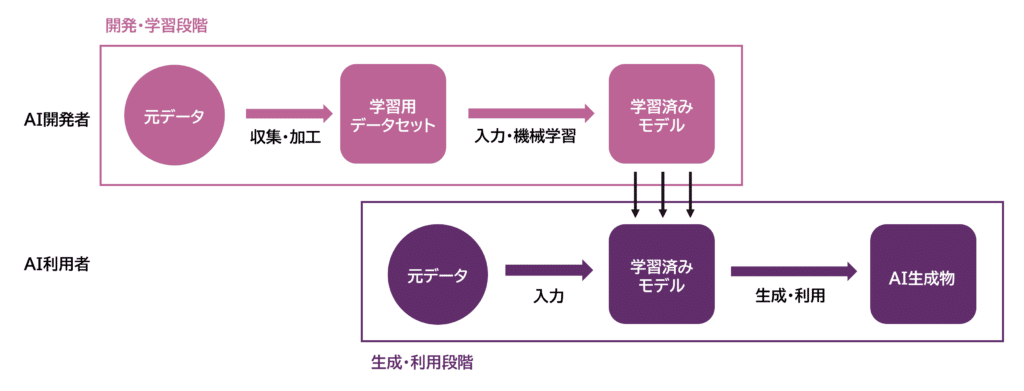
I udviklings- og læringsfasen indsamler og akkumulerer man oprindelige stemmedata som læringsdata for AI-udvikling og skaber et datasæt til læring. Derefter indføres dette læringsdatasæt i AI’en for at udføre maskinlæring og skabe en trænet model. Disse opgaver udføres normalt af AI-udviklere.
I genererings- og brugsfasen indføres de oprindelige data i den maskinlærte generative AI for at skabe og anvende AI-genererede produkter. Disse opgaver udføres normalt af AI-brugere.
For genererings- og brugsfasen kan vi forvente følgende tre anvendelsesmønstre:
- Mønster 1: At indføre en persons stemme i AI for at generere et AI-produkt, der er forskelligt fra den pågældende stemmedata
- Mønster 2: At indføre en persons stemme i AI for at generere et AI-produkt, der er identisk med eller ligner den pågældende stemmedata
- Mønster 3: At indføre data, der ikke er stemmedata fra en person, i AI for at generere et AI-produkt, der er identisk med eller ligner stemmedata fra en eksisterende person
I det følgende vil vi kort forklare, hvilke potentielle rettighedskrænkelser hvert anvendelsesmønster kan medføre.
Mønster 1: Indtastning af en persons stemme i AI og skabelse af et anderledes produkt

Først vil jeg forklare om mulige krænkelser af rettigheder, der kan opstå, når man indtaster en persons stemme i AI for at skabe et produkt, der er forskelligt fra den oprindelige stemmedata.
Forholdet til ophavsret
I mønster 1, forestil dig specifikt en situation, hvor man indtaster en bestemt sangers stemmedata i en AI, der kan identificere hvilken sanger det er, eller hvor man indtaster både en bestemt sangers stemme og brugerens egen stemme for at skabe stemmedata, der lyder som sangeren.
I forhold til ophavsretten bliver det problematisk at indtaste eksisterende værker i AI. Denne handling falder under “informationsanalyse” (Ophavsretsloven (herefter kun nævnt som loven) Artikel 30, Paragraf 4, Nummer 2), og derfor kan man bruge ophavsretligt beskyttede værker i enhver form, så længe det er nødvendigt for informationsanalysen. Derfor, hvis det er nødvendigt for informationsanalysen, vil brugen inden for de anerkendte grænser ikke udgøre en krænkelse af ophavsretten.
Forholdet til naborettigheder
I forhold til naborettighederne anvendes bestemmelserne i Ophavsretslovens Artikel 102, så de samme indtastningshandlinger generelt ikke vil udgøre en krænkelse af naborettighederne.
Forholdet til retten til offentlighed
I tilfældet med mønster 1, lad os antage, at stemmen, der indtastes, tilhører en bestemt berømthed. Hvis man bruger stemmedata fra en bestemt berømthed, kan handlingen udgøre en krænkelse af retten til offentlighed, som beskrevet i første del (#1 Udviklings- og læringsfase)[ja], hvis den falder ind under en af de tre typer af krænkelser. Men i dette tilfælde, selvom stemmedataen, der indtastes, tilhører en bestemt berømthed, er handlingen begrænset til at indtaste og analysere stemmedataen i genererings-AI’en, så den falder ikke ind under de tre typer af krænkelser.
Derfor kan man sige, at der ikke er plads til krænkelse af retten til offentlighed i denne brugshandling.
Mønster 2: Indtastning af en persons stemme i AI for at generere identiske eller lignende data
Mønster 2 refererer til processen, hvor man indtaster en bestemt sangers stemmedata sammen med sangtekster og melodidata i et AI-system for at skabe nye stemmedata, der synger de samme tekster og melodier med sangerens stemme. Dette kan overordnet opdeles i tre handlinger:
- Handlingen at indtaste stemmedata i AI
- Handlingen at skabe AI-genererede værker baseret på disse data
- Handlingen at anvende de AI-genererede værker
Med disse handlinger som udgangspunkt vil vi analysere forholdet til følgende rettigheder.
Forholdet til ophavsret
Først og fremmest, i forhold til ophavsretten, kan alle tre handlinger – indtastning, skabelse og anvendelse – indebære risiko for ophavsretskrænkelser.
For det første, hvad angår indtastningen. Ligesom med mønster 1, er indtastningshandlingen som udgangspunkt ikke en krænkelse af ophavsretten i henhold til artikel 30-4. Men der er en væsentlig undtagelse til denne regel. Hvis formålet med at skabe AI-genererede værker er at reproducere de essentielle karakteristika af den oprindelige datas udtryk (et formål med udtryksoutput), så gælder artikel 30-4 ikke, og handlingen vil være ulovlig. I tilfældet med mønster 2 bekræftes formålet med udtryksoutput ofte, hvilket betyder, at der er en høj sandsynlighed for ophavsretskrænkelse.
Dernæst, hvad angår skabelsen. I tilfældet med mønster 2 skabes der data, der er identiske eller ligner eksisterende ophavsretligt beskyttede stemmedata, hvilket udgør en krænkelse af reproduktionsretten (artikel 21). Derfor er der en høj sandsynlighed for ophavsretskrænkelse.
Endelig, hvad angår anvendelsen. Handlingen at anvende de i punkt 2 skabte værker, der er identiske eller ligner eksisterende ophavsretligt beskyttede værker, udgør en krænkelse af reproduktionsretten (artikel 21) eller retten til offentlig transmission (artikel 23). Derfor er der en høj sandsynlighed for ophavsretskrænkelse.
Forholdet til naborettigheder
I forhold til naborettighederne er der stadig praktiske og komplekse spørgsmål, der skal afklares, og derfor er yderligere overvejelser nødvendige.
I den nuværende situation anvendes bestemmelserne om ophavsret, såsom artikel 30-4, også på naborettigheder i henhold til artikel 102, hvilket betyder, at sandsynligheden for krænkelse af naborettigheder generelt er lav.
Forholdet til publicitetsrettigheder
Når det kommer til handlingerne fra punkt 1 til 3, er der næsten ingen risiko for krænkelse af publicitetsrettighederne i forbindelse med indtastning og skabelse af data.
Men når det gælder anvendelsen i punkt 3, hvis denne anvendelse indebærer kommerciel brug, såsom salg, så er der en høj sandsynlighed for, at det vil udgøre en krænkelse af publicitetsrettighederne.
Mønster 3: Indtastning af ikke-stemme data i AI for at generere identiske eller lignende stemmedata som en eksisterende person

Forholdet til ophavsretten
Mønster 3 indebærer for eksempel at indtaste navnet på en bestemt stemmeskuespiller og generere taledata for replikker fra den pågældende stemmeskuespiller ved hjælp af AI. Spørgsmålet er, om AI-genererede værker er afhængige af eksisterende ophavsretligt beskyttede værker.
Konklusionen er, at hvis en AI-bruger bevidst anvender AI med intentionen om at generere et værk, der er identisk med eller ligner et eksisterende ophavsretligt beskyttet værk, anses det for at være afhængigt af det eksisterende værk, hvilket er den fremherskende opfattelse.
For eksempel, hvis en AI-bruger genererer et AI-værk med det formål at efterligne en bestemt stemmeskuespillers stemme, vil dette være et tilfælde heraf. Derfor er der en høj sandsynlighed for ophavsretskrænkelse i sådanne tilfælde.
Forholdet til naborettigheder
Endvidere, selvom man bruger AI til at generere en præstation, der er identisk med eller ligner en eksisterende præstation, betragtes denne handling ikke som en “optagelse” af den eksisterende præstation, og derfor udgør det ikke en krænkelse af naborettighederne.
Forholdet til retten til publisitet
I forhold til retten til publisitet opstår der problemer, når den genererede stemme anvendes kommercielt. I praksis kan der tænkes mange forskellige scenarier, men det er nok at forstå konklusionen.
Konklusionen er, at hvis en AI-bruger med intentionen om at generere en stemme, der er identisk med eller ligner stemmen af en bestemt berømthed, realiserer dette og derefter anvender den genererede identiske eller lignende stemme, vil det udgøre en krænkelse af retten til publisitet. Tilfælde, hvor dette sker utilsigtet, er komplekse og indeholder stadig meget plads til debat i praksis, så de vil blive udeladt i denne artikel.
Konklusion: Søg rådgivning fra eksperter vedrørende forholdet mellem generativ AI og ophavsret
Indtil nu har vi forklaret de juridiske rettigheder, der er forbundet med menneskelige stemmer, og de problematiske handlinger, der kan opstå, når disse rettigheder anvendes, med udgangspunkt i konkrete eksempler.
Det er vigtigt at overveje de juridiske rettigheder til en persons stemme separat i forhold til ‘indhold’ og ‘lyd’, og at være opmærksom på ophavsret, beslægtede rettigheder og publicitetsrettigheder.
Når det kommer til problematiske handlinger, er det nødvendigt at fokusere på, hvad der præcist udgør problemet. Ved generering af stemmer ved hjælp af generativ AI er der mange diskussioner både i praksis og i forretningsverdenen. Når du starter en ny forretning, bør du være opmærksom på ovenstående punkter og stræbe efter at bruge generativ AI korrekt.
Relateret artikel: Kan generering af ‘stemme’ med AI føre til ophavsretskrænkelser? (#1 Udviklings- og læringsfase)[ja]
Vejledning i foranstaltninger fra vores advokatfirma
Monolith Advokatfirma kombinerer dybdegående erfaring inden for IT, især internettet, og jura. I de senere år har generativ AI og intellektuel ejendomsret, herunder ophavsret, tiltrukket sig stor opmærksomhed, og behovet for juridisk gennemgang er stigende. Vores firma tilbyder løsninger relateret til intellektuel ejendomsret. Yderligere detaljer er angivet i artiklen nedenfor.
Monolith Advokatfirmas ekspertiseområder: IT- og intellektuel ejendomsret for forskellige virksomheder[ja]
Category: IT




















