การสืบสวนผู้ดูแลเซิร์ฟเวอร์ของเว็บไซต์ที่มีโดเมนเฉพาะด้วย 'aguse.jp

เมื่อต้องการทำการลบบทความหรือขอเปิดเผยที่อยู่ IP ของผู้โพสต์บนเว็บไซต์ที่มีโดเมนเอกลักษณ์ ผู้ที่เราสามารถยื่นคำขอเหล่านี้ได้ โดยทั่วไปแล้ว จะมีอยู่สองประเภท คือ
- ผู้ดำเนินการเว็บไซต์ (ซึ่งส่วนใหญ่จะตรงกับผู้ที่ลงทะเบียนโดเมน)
- ผู้ดูแลเว็บเซิร์ฟเวอร์
ตัวอย่างเช่น ในกรณีของการขอลบบทความ คุณสามารถ
- ยื่นคำขอต่อผู้ดำเนินการเว็บไซต์ว่า “ฉันได้รับความเสียหายจากการถูกดูหมิ่นบนเว็บไซต์ที่คุณดำเนินการ ฉันต้องการให้คุณลบบทความนั้น”
- ยื่นคำขอต่อผู้ดูแลเว็บเซิร์ฟเวอร์ว่า “ฉันได้รับความเสียหายจากการถูกดูหมิ่นบนเว็บไซต์ที่โฮสต์บนเซิร์ฟเวอร์ที่คุณดูแล ฉันต้องการให้คุณลบบทความนั้น”
ในทางปฏิบัติ ผู้ที่คุณสามารถยื่นคำขอลบบทความบนอินเทอร์เน็ตได้ โดยทั่วไปแล้ว จะเป็น
- ผู้ที่มีอำนาจในการลบบทความนั้น
- ผู้ที่มีส่วนร่วมในการเผยแพร่บทความนั้นบนอินเทอร์เน็ตอย่างมากพอที่จะสามารถกล่าวได้ว่า ตามหลักการ ควรจะลบบทความนั้น
และผู้ดำเนินการเว็บไซต์และผู้ดูแลเว็บเซิร์ฟเวอร์ทั้งสอง ทั้งคู่ตรงตามเงื่อนไขนี้ การขอเปิดเผยที่อยู่ IP ก็มีโครงสร้างทางตรรกศาสตร์ที่แตกต่างกัน แต่สรุปผลก็จะเหมือนกัน
ความหมายของ “การสืบสวนผู้ดูแลเว็บเซิร์ฟเวอร์”
แต่ถ้าเราพูดถึง “ผู้ดูแลเว็บเซิร์ฟเวอร์ของเว็บไซต์ที่ใช้โดเมนเฉพาะ” นั้นหมายถึงใครอย่างแน่นอน? ยกตัวอย่างเช่น ในกรณีของเว็บไซต์ของเรา (เว็บไซต์ของสำนักกฎหมาย Monolis) ผู้ดูแลเว็บเซิร์ฟเวอร์คือใครอย่างแน่นอน?
เราจะอธิบายวิธีการสืบสวนเพื่อหาว่าผู้ดูแลเว็บเซิร์ฟเวอร์ของเว็บไซต์ที่ใช้โดเมนเฉพาะคือใคร โดยใช้บริการเว็บ “aguse.jp”.
วิธีการตรวจสอบผู้ดำเนินการเว็บไซต์ = ผู้ลงทะเบียนโดเมน
ดังที่เราได้เขียนไว้ตั้งแต่ต้น ไม่ว่าจะเป็นการร้องขอลบบทความหรือการร้องขอเปิดเผยที่อยู่ IP หากคุณทราบผู้ดำเนินการเว็บไซต์ คุณสามารถยื่นคำร้องไปยังผู้ดำเนินการนั้นได้ ในกรณีของเว็บไซต์ที่มีโดเมนเฉพาะ ผู้ดำเนินการเว็บไซต์มักจะตรงกับผู้ที่ลงทะเบียนโดเมน และคุณสามารถตรวจสอบข้อมูลเกี่ยวกับผู้ลงทะเบียนโดเมนเฉพาะผ่านระบบที่เรียกว่า “whois” วิธีนี้ได้รับการอธิบายในบทความอื่น
https://monolith.law/reputation/ansi-whois-howto[ja]
วิธีการสำรวจผู้ดูแลเว็บเซิร์ฟเวอร์
เว็บไซต์ที่ดำเนินการด้วยโดเมนเฉพาะส่วนใหญ่จะใช้เซิร์ฟเวอร์เช่าในการดำเนินการ โดยทั่วไป “เว็บไซต์ที่มีโดเมนเฉพาะ” จะเปิดใช้งานด้วยขั้นตอนดังนี้:
- ขั้นแรก, ใช้บริการลงทะเบียนโดเมน (Domain Registrar) เช่น “Onamae.com” หรือ “GoDaddy” เพื่อรับโดเมนเฉพาะ
- ขั้นต่อไป, ทำสัญญากับเซิร์ฟเวอร์เช่าเช่น “Sakura Internet” และรักษาเว็บเซิร์ฟเวอร์ที่ให้บริการโฮสต์เว็บไซต์
- ตั้งค่าให้เมื่อพยายามเข้าถึง URL ของโดเมนนั้น จะเชื่อมต่อกับเว็บเซิร์ฟเวอร์นั้น
นั่นคือขั้นตอนในการเปิดใช้งาน
วิธีการใช้งาน「aguse.jp」
และเว็บเซอร์วิสที่ถูกใช้งานอย่างแพร่หลายในการตรวจสอบเว็บเซิร์ฟเวอร์นี้คือ「aguse.jp」
วิธีการใช้งาน「aguse.jp」นั้นง่ายมาก ขั้นแรก ให้คุณป้อน URL ที่ต้องการตรวจสอบในหน้าแรก ข้อมูลที่จำเป็นในขั้นตอนนี้คือ URL
http://www.Monolith-law.jp/article/index.html
ส่วนที่เป็น「www.Monolith-law.jp」นั้น นั่นคือส่วนที่เรียกว่า “ชื่อโฮสต์”
ถ้าอ้างอิงจากตัวอย่างข้างต้น ส่วนที่เป็น「/article」ขึ้นไปนั้น เป็นข้อมูลที่บ่งบอกถึงตำแหน่งภายในเซิร์ฟเวอร์ของหน้าเว็บนั้น และไม่จำเป็นสำหรับการระบุเซิร์ฟเวอร์ ในขณะเดียวกัน ส่วนที่เป็น「www」นั้นเป็น “โดเมนย่อย” ซึ่งสามารถตั้งค่าได้ไม่จำกัดในโดเมนที่เป็นเอกลักษณ์ (Monolith-law.jp) แต่ถ้าโดเมนย่อยต่างกัน เซิร์ฟเวอร์อาจจะต่างกัน นั่นคือ ถ้า
https://monolith-law.jp
http://www2.Monolith-law.jp
http://blog.Monolith-law.jp
มีโดเมนย่อยหลายๆ ตัวเช่นนี้ สำหรับแต่ละโดเมนย่อย เซิร์ฟเวอร์อาจจะต่างกัน ซึ่งนี่จะต่างจากการตรวจสอบข้อมูลของผู้ลงทะเบียนโดเมนโดยใช้ “whois”
วิธีการอ่านหน้าผลการสืบค้นจาก「aguse.jp」
เมื่อคุณคลิกที่ “สืบค้น” หน้าผลการสืบค้นจะปรากฏขึ้น
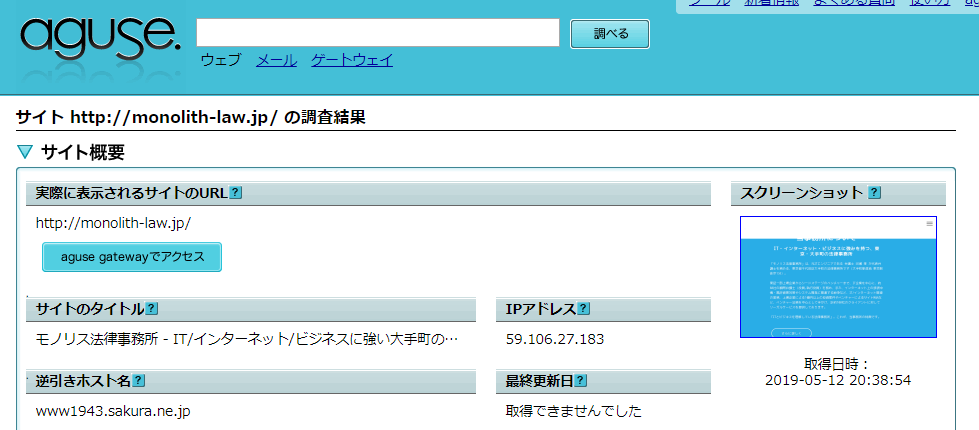
สิ่งที่แสดงใน “ชื่อโฮสต์ที่ถูกอ้างถึง” คือ “ชื่อโฮสต์” ของเว็บเซิร์ฟเวอร์ที่ให้บริการเว็บไซต์นั้น
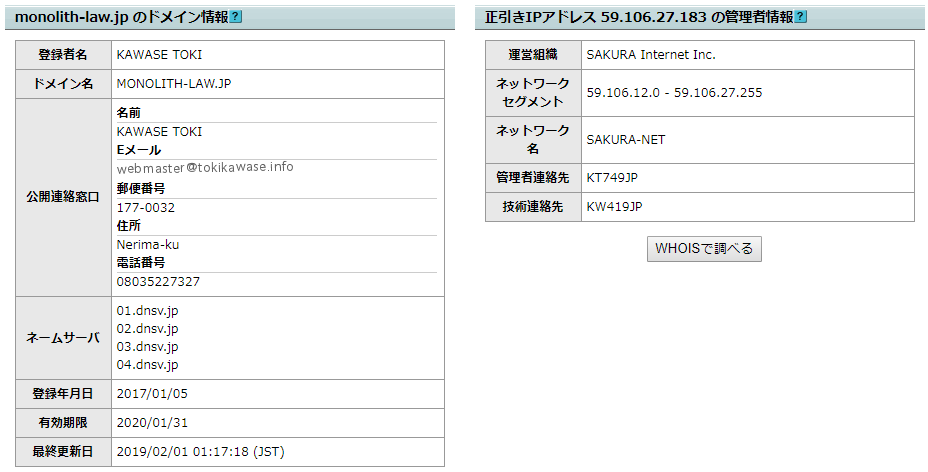
และสิ่งที่แสดงใน “ข้อมูลผู้ดูแล IP ที่ถูกอ้างถึง ●●.●●.●●.●●” คือข้อมูลเกี่ยวกับผู้ดูแลเว็บเซิร์ฟเวอร์นั้น
วิธีการสืบสวนของผู้ดูแลระบบ
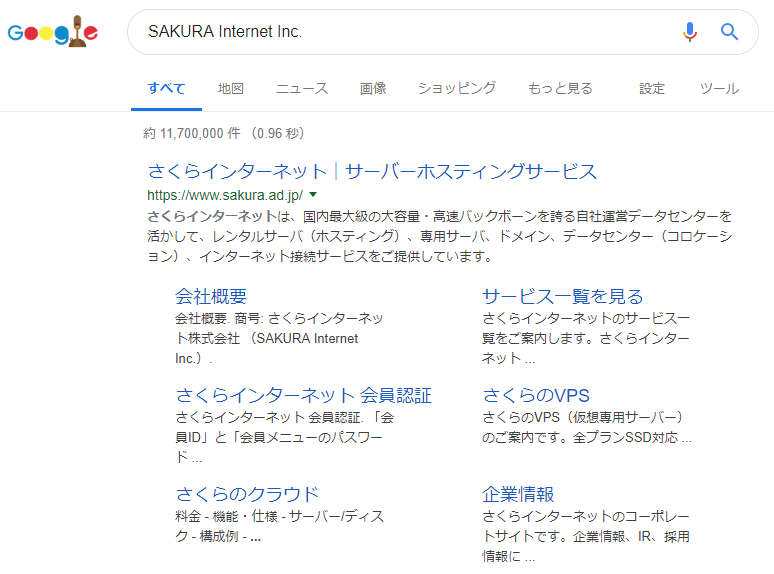
หากคุณทำการค้นหาข้อความที่แสดงอยู่ที่นี่บน Google คุณจะสามารถระบุผู้ดูแลเว็บเซิร์ฟเวอร์ได้ ในกรณีนี้ ได้ระบุได้ว่า “บริษัท ซากุระ อินเทอร์เน็ต” คือผู้ที่ดูแล “www.Monolith-law.jp”
「aguse.jp」 ดำเนินการสำรวจอย่างไร
การใช้งาน「aguse.jp」ในฐานะเว็บเซอร์วิส โดยพื้นฐานแล้วจะสิ้นสุดตามที่ได้กล่าวไว้ด้านบน แต่ในขณะนี้ มีการดำเนินการอย่างไรทางเทคนิค และทำไมเราสามารถตรวจสอบข้อมูลของผู้ดูแลเว็บเซิร์ฟเวอร์ที่โฮสต์เว็บไซต์โดเมนเฉพาะด้วยวิธีนี้ จะมีการอธิบายเพิ่มเติมในที่นี้ ในที่สุด หากคุณไม่รู้ว่า “ทำอะไร” คุณจะไม่สามารถรับมือกับกรณีที่เป็นข้อยกเว้นได้ แม้แต่น้อย
“IP แอดเดรส” คือที่อยู่บนอินเทอร์เน็ต
เราจะเริ่มต้นเรื่องนี้จาก “IP แอดเดรสคืออะไร” ก่อน IP แอดเดรสคือข้อมูลที่ทุกเครื่องที่เชื่อมต่อกับอินเทอร์เน็ต (โดยหลัก) จะมีเป็นของตัวเอง ซึ่งเรียกว่า “ที่อยู่บนอินเทอร์เน็ต” ตัวอย่างเช่น เมื่อคุณเข้าชมเว็บไซต์นี้ด้วยสมาร์ทโฟน สมาร์ทโฟนของคุณก็จะมี IP แอดเดรสของตัวเอง
และเช่นเดียวกับอุปกรณ์ที่ใช้เข้าชมเว็บไซต์ (เช่น สมาร์ทโฟน) ที่มี IP แอดเดรสของตัวเอง เว็บไซต์และเว็บเซิร์ฟเวอร์ที่โฮสต์เว็บไซต์นั้น ก็จะมี IP แอดเดรสของตัวเอง การสื่อสารระหว่างเครื่องบนอินเทอร์เน็ต เช่น “การสื่อสารเพื่อเข้าชมเว็บไซต์ของทนายความ Monolis ผ่านสมาร์ทโฟน” จะเกิดขึ้นระหว่างเครื่องที่มี IP แอดเดรสของตัวเองเสมอ
สมาร์ทโฟนที่มี IP แอดเดรส ●●.●●.●●.●● และ
เว็บเซิร์ฟเวอร์ที่มี IP แอดเดรส ●●.●●.●●.●● จะแลกเปลี่ยนข้อมูลของหน้าเว็บกัน
นี่คือ “การเข้าชมเว็บไซต์ผ่านอินเทอร์เน็ต”
ความสัมพันธ์ระหว่าง「URL」และ「IP แอดเดรสของเว็บเซิร์ฟเวอร์」
แต่ในประสบการณ์ปกติของการท่องเว็บ ผู้ใช้มักจะไม่ได้สนใจว่า IP แอดเดรสของเว็บไซต์ที่เขากำลังดู (หรือเว็บเซิร์ฟเวอร์ที่โฮสต์เว็บไซต์นั้น) คืออะไร การสื่อสารที่อาศัย IP แอดเดรสเป็นหลักนั้น มักจะเกิดขึ้นภายในอุปกรณ์เช่นสมาร์ทโฟน และผู้ใช้ไม่ต้องสนใจถึง “IP แอดเดรส” เนื่องจากมันถูกออกแบบให้เช่นนั้น สิ่งที่ผู้ใช้ต้องสนใจแทน IP แอดเดรสคือ URL
https://monolith.law/article/index.html
ผู้ใช้จึงท่องเว็บโดยมี URL เป็นสิ่งที่ต้องสนใจ ในกรณีที่ผู้ใช้พยายามเปิด URL ที่กล่าวถึงข้างต้น อุปกรณ์เช่นสมาร์ทโฟนจะทำการ
- สืบค้น IP แอดเดรสของ URL นั้น (หรือเว็บเซิร์ฟเวอร์ที่โฮสต์เว็บไซต์)
- สื่อสารกับ IP แอดเดรสนั้น
ซึ่งเป็นกระบวนการที่เกิดขึ้น
ความหมายของ “การแปลงทางตรง” ของชื่อโฮสต์
การประมวลผลที่ 1 ดังกล่าวข้างต้น นั่นคือ การแปลง URL (ที่แน่นอนคือส่วน “www.Monolith-law.jp” ของ URL หรือ “ชื่อโฮสต์”) เป็น IP ที่อยู่ จะเรียกว่า “การแปลงทางตรง”
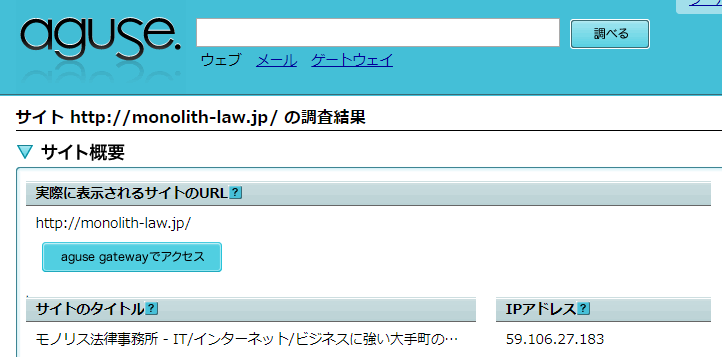
เมื่อคุณตรวจสอบ URL ด้วย “aguse.jp” ข้อมูลที่แสดงใน “IP ที่อยู่” คือ IP ที่อยู่ที่ได้มาจากการ “แปลงทางตรง” ส่วนของชื่อโฮสต์ของ URL นั้น
ความหมายของ “การค้นหา IP แบบย้อนกลับ”
การค้นหาแบบย้อนกลับ หรือ “Reverse Lookup” คือ การทำกระบวนการแปลง IP แอดเดรสเป็นชื่อโฮสต์ ซึ่งเป็นการทำงานที่ตรงข้ามกับ “การค้นหาแบบตรง”
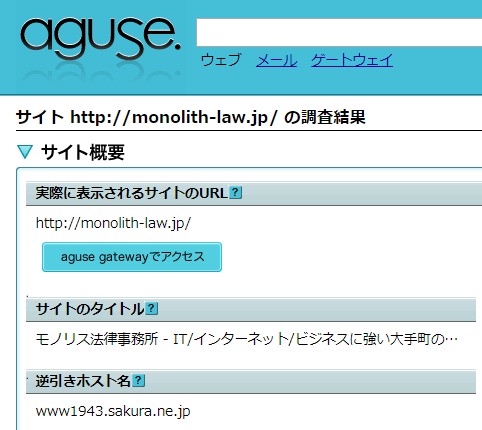
ชื่อโฮสต์ที่แสดงใน “การค้นหาแบบย้อนกลับ” ของ “aguse.jp” คือ
- การค้นหาชื่อโฮสต์ใน URL แบบตรงก่อน
- แล้วค้นหาชื่อโฮสต์ที่ได้จากการค้นหาแบบย้อนกลับ
นั่นคือความหมายของมัน
สิ่งที่ทำให้ซับซ้อนที่นี่คือ เมื่อทำการ “ค้นหาแบบตรง → ค้นหาแบบย้อนกลับ” ในกรณีของเว็บไซต์ที่มีโดเมนเฉพาะของตัวเอง ชื่อโฮสต์ของเซิร์ฟเวอร์เช่าจะปรากฏขึ้น ซึ่งเป็นกลไกที่ค่อนข้างซับซ้อน แต่เราจะอธิบายให้คุณเข้าใจในที่นี้อย่างง่ายๆ
ความหมายของ “เซิร์ฟเวอร์ชื่อ”
ขั้นแรก, “การค้นหาย้อนกลับ” ไม่ได้เป็นกระบวนการที่จำเป็นสำหรับการใช้งานอินเทอร์เน็ตเสมอไป ดังที่กล่าวไว้ข้างต้น, ในระหว่างการท่องเว็บปกติ “การค้นหา IP ของเซิร์ฟเวอร์เว็บจาก URL” หรือ “การค้นหาตรง” จะเกิดขึ้น แต่ “การค้นหาย้อนกลับ” ไม่มีส่วนในการท่องเว็บปกติหรือการสื่อสารอินเทอร์เน็ตปกติ และ “เซิร์ฟเวอร์ชื่อ” คือสิ่งที่ใช้ในการทำ “การค้นหาตรง” นี้
- ขั้นแรก, สืบค้น IP ของเซิร์ฟเวอร์เว็บที่โฮสต์เว็บไซต์ของ URL นั้น
- สื่อสารกับ IP นั้น
สิ่งที่เกิดขึ้นในขั้นที่ 1 นี้, ถ้าพูดอย่างถูกต้องมากขึ้นคือ,
- สอบถามชื่อโฮสต์ของเซิร์ฟเวอร์เว็บที่โฮสต์เว็บไซต์ของ URL ที่ต้องการเข้าถึงกับเซิร์ฟเวอร์ชื่อ
- เซิร์ฟเวอร์ชื่อตอบ IP ของชื่อโฮสต์ของเซิร์ฟเวอร์เว็บที่โฮสต์เว็บไซต์ของ URL นั้น
ดังนั้น, เซิร์ฟเวอร์ชื่อคือสิ่งที่เก็บข้อมูลการจับคู่ระหว่าง “ชื่อโฮสต์และ IP ที่สอดคล้องกับชื่อโฮสต์” อย่างที่คุณเก็บข้อมูลในพจนานุกรม
“เซิร์ฟเวอร์ชื่อ” และ “เซิร์ฟเวอร์ชื่อรูท”
และเซิร์ฟเวอร์ชื่อนั้นมีอยู่เป็นจำนวนมากบนอินเทอร์เน็ต การดำเนินการสอบถามที่กล่าวถึงข้างต้นนั้นเกิดขึ้นอย่างมากในระหว่างการท่องเว็บ ถ้าเราสมมติว่า “เซิร์ฟเวอร์ชื่อเดียวสามารถตอบสนองต่อการสอบถามทั้งหมดในอินเทอร์เน็ตทั้งหมด” ระบบนั้นจะทำให้เซิร์ฟเวอร์มีภาระที่มากเกินไป ดังนั้นเซิร์ฟเวอร์ชื่อจึงมีอยู่เป็นจำนวนมาก และพวกเขาถูกจัดเรียงบนต้นไม้โดยเริ่มจาก “เซิร์ฟเวอร์ชื่อรูท” ซึ่งเป็นมาสเตอร์ของเซิร์ฟเวอร์ชื่อ “เซิร์ฟเวอร์ชื่อที่อยู่ภายใต้เซิร์ฟเวอร์ชื่อรูท (เช่น A, B) และเซิร์ฟเวอร์ชื่ออื่นๆ (เช่น C, D) อยู่ภายใต้เซิร์ฟเวอร์ชื่อ A” นั่นคือรูปแบบการทำงาน
และเซิร์ฟเวอร์ชื่อเหล่านี้ที่มีอยู่เป็นจำนวนมากบนอินเทอร์เน็ต ควรจะมีข้อมูลในพจนานุกรมที่เหมือนกันเสมอถ้าเป็นไปได้ แต่ถ้าพยายามทำให้สิ่งนี้เป็นจริง การทำงานในการซิงค์ข้อมูลนั้นจะกลายเป็นภาระที่มากเกินไป ดังนั้นในทางปฏิบัติ การซิงค์ข้อมูลที่สมบูรณ์แบบไม่ได้ดำเนินการ “มีข้อมูลที่ไหนสักแห่งบนเซิร์ฟเวอร์ชื่อบนต้นไม้ และถ้ามีข้อมูลที่ไหนสักแห่ง การสอบถามอย่างมีลำดับจะสามารถได้รับคำตอบในที่สุด” นั่นคือรูปแบบการทำงาน
คืออะไร “การค้นหาย้อนกลับ” ของ IP แอดเดรส
ในกรณีของ “การค้นหาย้อนกลับ” การสอบถามจะถูกดำเนินการจากเซิร์ฟเวอร์ชื่อรูทไปยังเซิร์ฟเวอร์ชื่ออื่นๆ ตามลำดับ การสอบถามนี้เป็นการสอบถามที่ตรงกันข้ามกับการสอบถามปกติ (การสอบถามในกรณีของการค้นหาตรง) คือ “กรุณาตอบชื่อโฮสต์ที่สอดคล้องกับ IP แอดเดรส ●●.●●.●●.●●” การตอบสนองต่อการสอบถามนี้ ในส่วนใหญ่จะเป็นสตริงที่เกี่ยวข้องกับเว็บเซิร์ฟเวอร์ที่โฮสต์เว็บไซต์นั้น ตัวอย่างเช่น
- ถ้าคุณ “ค้นหาตรง” ชื่อโฮสต์ “Monolith-law.jp” IP แอดเดรสที่ได้รับคือ “59.106.27.183”
- ถ้าคุณ “ค้นหาย้อนกลับ” IP แอดเดรส “59.106.27.183” ชื่อโฮสต์ที่ได้รับคือ “www1943.sakura.ne.jp” (ไม่ใช่ “Monolith-law.jp”)
นั่นคือ
และชื่อโฮสต์ที่ “เกี่ยวข้องกับเว็บเซิร์ฟเวอร์ที่โฮสต์เว็บไซต์นั้น” ในกรณีของเซิร์ฟเวอร์เช่า จะรวมถึงโดเมนที่เซิร์ฟเวอร์เช่ามี ในตัวอย่างข้างต้นคือ “sakura.ne.jp”
ข้อมูล whois ของโดเมนของผู้ให้บริการเซิร์ฟเวอร์เช่า
ผู้ให้บริการเซิร์ฟเวอร์เช่ามักจะลงทะเบียนข้อมูลที่ถูกต้องใน whois ในส่วนใหญ่
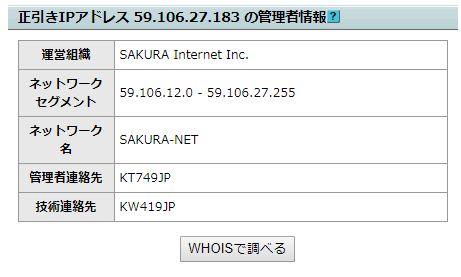
ดังนั้น, ถ้าคุณตรวจสอบชื่อโดเมนนี้ใน “whois”, คุณจะสามารถรับข้อมูลเกี่ยวกับผู้ให้บริการเซิร์ฟเวอร์เช่านั้น ๆ, ในตัวอย่างข้างต้น, คุณจะสามารถรับข้อมูลว่า “องค์กรผู้ดำเนินการ” คือ “SAKURA Internet Inc.”
สรุป
ดังนั้น การทำงานเช่น “การสืบสวนผู้ให้บริการเซิร์ฟเวอร์เช่าที่จัดการเซิร์ฟเวอร์โฮสติ้งเพื่อทำการร้องขอการลบหรือเปิดเผยที่อยู่ IP สำหรับเว็บไซต์ที่ดำเนินการด้วยโดเมนเฉพาะ” นั้นเป็นเรื่องที่ซับซ้อนอย่างมากในเชิงของ IT สิ่งที่อธิบายในบทความนี้เป็นเพียง “พื้นฐาน” และ “การประยุกต์ใช้” คือ “วิธีการแก้ไขปัญหาที่ไม่สามารถทะลุได้ด้วยความรู้พื้นฐานเท่านั้น”
การจัดการความเสี่ยงทางชื่อเสียงบนอินเทอร์เน็ตนั้น จำเป็นต้องมีความเชี่ยวชาญทั้งในด้าน IT และกฎหมายอย่างมาก
Category: Internet




















