Grundlæggende foranstaltninger mod rygteskader: En guide til at gennemgå negative artikler på nettet

I tilfælde af at man ønsker at fjerne alle websider, der omhandler tidligere virksomhedsskandaler, brandhændelser, anholdelser eller tidligere domme, er det først og fremmest nødvendigt at lave en fuldstændig liste over alle disse negative sider og indlæg. Uden denne liste er det umuligt at vurdere det samlede omfang og dermed at gennemføre effektive foranstaltninger mod omdømmeskader. For eksempel kan det være nødvendigt at gennemføre retssager eller foreløbige foranstaltninger to gange i stedet for én, hvis der er overset noget.
Men det er langt fra ‘let’ at lave en fuldstændig liste over alle websider og indlæg på internettet, der omhandler en bestemt hændelse (som for eksempel virksomhedsskandaler, brandhændelser, anholdelser eller tidligere domme). Dette er en opgave, der kræver stor ekspertise og know-how.
Monolith Law Office er et advokatfirma med speciale i håndtering af omdømmeskader. Vi har en stab af specialister, herunder vores administrerende advokat, der tidligere var IT-ingeniør, og personale, der er specialiseret i netforskning. Nedenfor vil vi forklare, hvordan netforskning skal udføres.
Hvad er Google-søgeresultater og deres begrænsninger?
Grundlaget for netforskning er uden tvivl Google-søgning. Men der er begrænsninger i de søgeresultater, der vises, når du søger efter de nøgleord, du vil finde på Google, for eksempel i tilfælde af at fjerne en anholdelsesartikel, ved at søge efter nøgleord som “dit eget navn anholdelse”. Disse begrænsninger findes i tre aspekter.
Websteder, der er mål for Google-søgning
Der findes et “uendeligt” antal websteder på internettet. Selvom det teoretisk set er umuligt at måle det samlede antal websteder på internettet, er det ifølge nogle kilder omkring 1,8 milliarder websteder i øjeblikket.
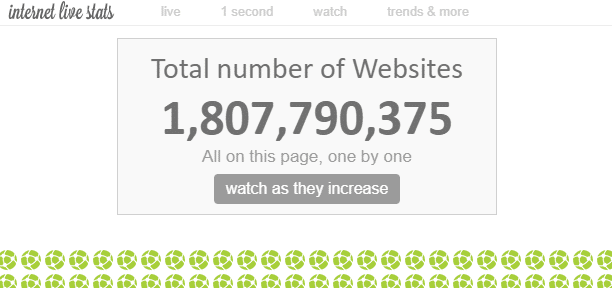
Da der findes flere websider inden for et enkelt websted, er antallet af websider meget større end antallet af websteder.
Og Google-søgning er, simpelt sagt, en proces, hvor:
- Googles bot (Googlebot) scanner internettet, opdager nye websider ved at følge links fra kendte websider
- Forstår indholdet af disse sider (indeksering)
- Viser disse sider i søgeresultaterne, når der søges med nøgleord indeholdt på disse sider
Det, jeg vil sige, er, at de sider, der vises i Google-søgning, er de sider, som Google har indekseret på den måde, jeg har beskrevet ovenfor, ikke “alle websider”. Med andre ord, så længe du bruger Google-søgning, kan du ikke finde “websider, som Google endnu ikke har indekseret”, og der er ingen måde i denne verden at fuldstændigt søge alle websider på internettet.
“Lignende” websider udelukkes fra søgeresultater
Google inkluderer ikke “alle websider, der indeholder søgeordene, blandt de websider, der er indekseret” i søgeresultaterne. Dette er noget, du måske har bemærket, hvis du bruger Google-søgning regelmæssigt. Det er angivet på den sidste side af søgeresultaterne, hvor der står “For at vise de mest præcise resultater er sider, der ligner de ovenstående, udelukket.”
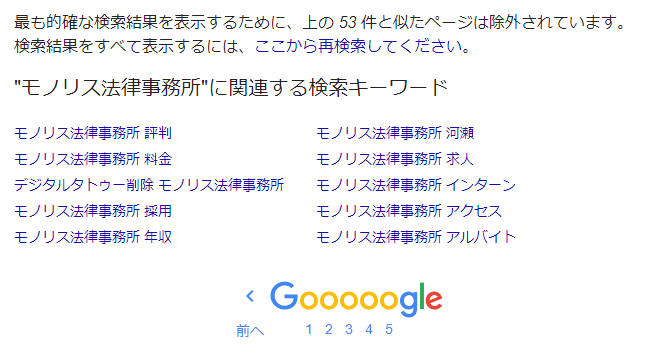
For eksempel, hvis:
- En nyhed først blev offentliggjort på et større nyhedssted
- Nyhedsartiklen blev genudgivet på en nyhedssammenfatningstjeneste
- Den blev også genudgivet på personlige hjemmesider osv.
I sådanne tilfælde, for at undgå at fylde søgeresultaterne med sider med det samme indhold, hvilket ville gøre det svært for brugerne at bruge, udelukker Google “lignende” sider fra søgeresultaterne. I ovenstående eksempel ville det være punkt 2 og 3.
Dette er ikke nødvendigvis en “brugervenlig” funktion, hvis du ønsker at fjerne alle sider med skadelige rygter. For eksempel, hvis ovenstående “nyhed” er en gammel arrestationsrapport om dig selv,
Hvis kun “1. Den oprindelige artikel fra det større nyhedssted” blev vist i søgeresultaterne, og du fjerner denne side, kan “2. Genudgivelsen af artiklen på nyhedssammenfatningstjenesten” begynde at blive vist i Google-søgeresultaterne, fordi 1 er blevet fjernet.
Dette er en mulig situation.
Dette problem kan løses ved at klikke på “Klik her for at søge igen og vise alle resultater” i ovenstående meddelelse, men hvis du ikke kender til denne funktion, er der en risiko for, at du kan “overse” sider med skadelige rygter.
Der er en grænse for antallet af artikler, der vises fra samme hjemmeside

Desuden har Google sat en grænse for antallet af søgeresultatsider, der vises fra en enkelt hjemmeside. Denne specifikation er lidt kompliceret, men for at sige det simpelt, “maksimalt 2 sider vises fra samme hjemmeside”.
For at forklare, hvad det betyder, lad os sige, for eksempel, at der er 5 Q&A’er, hvor et bestemt firma eller persons navn optræder på Yahoo! Chiebukuro (Yahoo! Answers), men i Google-søgeresultaterne for det pågældende firma eller persons navn, vil der højst blive vist 2 sider fra Yahoo! Chiebukuro. Det samme gælder for fora, selvom der er 5 tråde på 5chan (et japansk forum) med et bestemt nøgleord, vil der højst blive vist 2 i Google-søgeresultaterne. For eksempel, hvis en person har,
- En artikel om deres anholdelse
- En artikel om deres genanholdelse
- En artikel om deres domfældelse
og alle 3 artikler findes på samme nyhedsside, vil mindst en af dem (3-2=1) ikke blive vist i Google-søgeresultaterne.
Når man søger efter et bestemt nøgleord, og sider fra samme hjemmeside (for eksempel Yahoo! Chiebukuro, et bestemt forum, en bestemt nyhedsside osv.) fylder søgeresultaterne, er det upraktisk for brugeren, så Google har denne specifikation.
Men denne specifikation er ikke nødvendigvis “brugervenlig”, hvis man ønsker at “fjerne alle sider med dårligt ry”.
For eksempel, hvis man ønsker at fjerne negative Q&A’er fra Yahoo! Chiebukuro gennem retslige procedurer, og man ser på Google-søgeresultaterne og beslutter, at “der er kun 2 mål”, og fortsætter med proceduren, vil en af de resterende 3 (5-2=3) blive vist i søgeresultaterne, når sletningen er vellykket.
Avanceret Google-søgning ved hjælp af “søgeformler”
For at løse især det tredje problem nævnt ovenfor, er det nødvendigt at bruge en funktion i Google kaldet “søgeformler”.
Google har ganske vist en grænse på “grundlæggende 2 sider pr. site” for sin funktion til at “søge efter sider, der indeholder det pågældende nøgleord fra hele internettet” (global søgning). Men hvis du bruger en “søgeformel” som “nøgleord site: målwebstedets URL”, kan du:
- Udføre en søgning, der kun målretter artikler inden for det specificerede målwebsted
- Der er ingen grænse på “grundlæggende 2 sider pr. site” for disse søgeresultater
Dette gør det muligt at udføre sådanne søgninger.
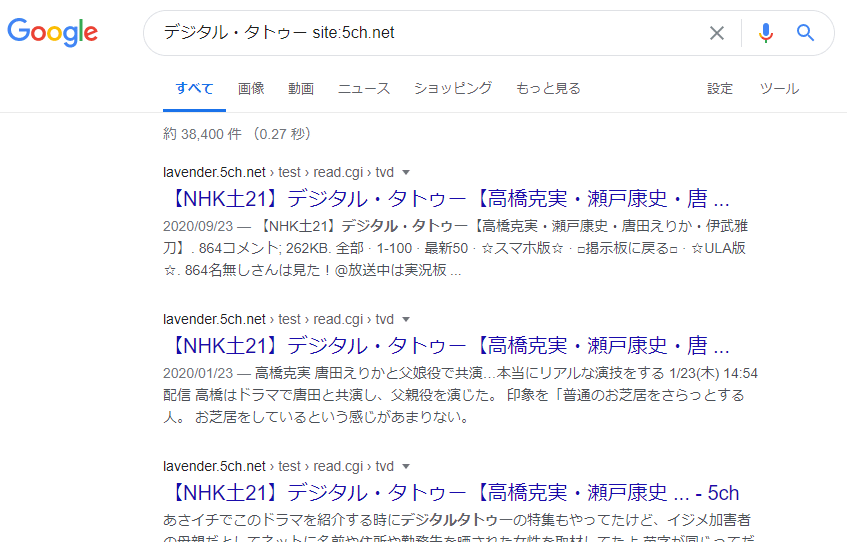
“Søgeformler” er faktisk mere komplekse, og der findes også søgeformler, der bruges til at løse andre problemer end dem nævnt ovenfor.
Særlige søgefunktioner for bestemte websteder
For eksempel har Yahoo! Chiebukuro (Yahoo! Answers) sin egen søgefunktion.
Denne søgning er ikke baseret på “websider, som Google tilfældigvis har indekseret”, men er “resultatet af en direkte søgning i Yahoo! Chiebukuro’s database ved hjælp af Yahoo! Chiebukuro’s søgeprogram”. Dette løser problemet, vi først nævnte, om at “der findes websider, som Google endnu ikke har indekseret”. Det betyder, at “hvis det er en side inden for Yahoo! Chiebukuro, kan du finde alt uden at overse noget, så længe du bruger Yahoo! Chiebukuro’s søgefunktion”.
Det vil sige,
Hvis en side fra Yahoo! Chiebukuro er fundet i en global søgning om en bestemt kendsgerning (f.eks. en virksomheds skandale, en persons anholdelse osv.), kan du lave en mere komplet liste ved at bruge Yahoo! Chiebukuro’s søgefunktion i stedet for at bruge “site:” søgeformlen.
Det er pointen.
Det samme gælder for Twitter. På grund af naturen af Twitter’s tjeneste, er der ofte mange tweets om en bestemt kendsgerning (f.eks. en virksomheds skandale, en persons anholdelse osv.). Ikke alle disse tweets er nødvendigvis indekseret af Google, og de vises ikke alle på en global søgning.
Metoden til at tælle ‘1 sag’ der skal slettes

Forholdet mellem en passende liste og ‘URL’
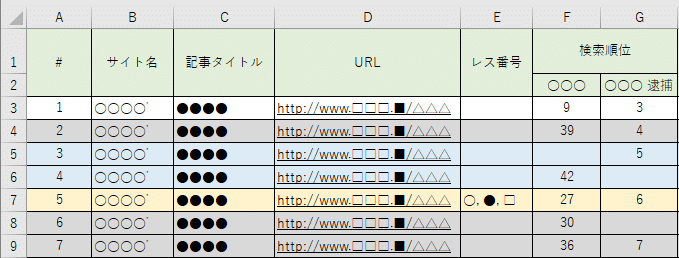
Indtil videre har vi skrevet om ‘hvordan man finder så mange websider (URL’er) som muligt ved hjælp af Google-søgning osv.’, men det betyder ikke nødvendigvis, at det er godt, hvis du kan lave en lang liste. Dette skyldes, at det, der skal slettes, ikke nødvendigvis tager ‘URL’ som enhed.
I tilfældet med 5chan (japansk diskussionsforum)
Dette er et problem, der især opstår i tilfælde af diskussionsforumsider (som 5chan og dets kopiwebsteder, og andre diskussionsforumsider).
For eksempel, hvis du søger efter et bestemt nøgleord på Google med søgeformlen ‘site:5ch.net’, det vil sige, du søger inden for 5chan, kan du se URL’er som følgende i søgeresultaterne:
- ○○○.5ch.net/test/read.cgi/○○/○○○○/40
- ○○○.5ch.net/test/read.cgi/○○/○○○○/1-100
- ○○○.5ch.net/test/read.cgi/○○/○○○○/30-
5chan har følgende specifikationer:
- Hvis du skriver svarnummeret efter tråd-URL’en, vises kun det svar
- Hvis du skriver et interval af svarnumre som ‘A-B’ efter tråd-URL’en, vises kun de svar i det interval
- Hvis du skriver et startpunkt for svarnumre som ‘A-‘ efter tråd-URL’en, vises alle svar fra det punkt og frem
Det betyder, at hvis det pågældende nøgleord kun er skrevet i svar nummer 40, vil forskellige URL’er (websider) blive vist i ‘søgeresultaterne’.
Men når du anmoder om sletning fra diskussionsforumsider, er enheden for det, der skal slettes, i det mindste principielt ‘svar’. Derfor, hvis du vil slette svar nummer 40, skal du blot udtrække
- ○○○.5ch.net/test/read.cgi/○○/○○○○/40
URL’en, og du behøver ikke at liste de to sidste.
I tilfældet med 5chan kopisider og opsummeringssider
For at tilføje, selvom det er lidt kompliceret, selv inden for det samme 5chan (system), afhænger enheden for sletteanmodningen af webstedet, og det kan være ‘side (tråd)’ i stedet for ‘svar’ for kopisider og ‘opsummeringssider’. Hvad der er målet for sletteanmodningen for hvilket websted er helt inden for området ‘know-how’.
https://monolith.law/reputation/delation-of-scraping-site-roundup-website[ja]
Derfor,
- Forståelse af enheden for juridiske sletteanmodninger
- Forståelse af URL-specifikationerne for et bestemt websted (for eksempel har 5chan de ovennævnte komplekse regler)
er nødvendige for at kunne ‘liste det, der skal slettes, mens man ser på søgeresultaterne’.
Søgning uden for det åbne web

Indtil videre har vi forklaret om de sider, som Google potentielt kan indeksere, men der er også en gruppe af sider, som:
- Google helt sikkert ikke vil indeksere
- Men bør overvejes som mål for fjernelsesanmodninger i forbindelse med håndtering af omdømmeskader
Google indekserer kun websteder, der er tilgængelige for alle uden at logge ind (det åbne web) i henhold til ovenstående specifikationer. Men der findes også tjenester på nettet, som for eksempel tillader søgning og visning af gamle avisartikler mod betaling (og derfor kræver brugerregistrering eller login for at kunne ses).
For eksempel, i tilfælde af fjernelse af anholdelsesartikler, er det nødvendigt at undersøge også disse avisdatabase-websteder. Dette skyldes, at mange virksomheder, der undersøger virksomheders eller individers kreditværdighed, bruger disse avisdatabase-websteder.
For mere detaljeret information om avisdatabase-websteder, se artiklen nedenfor.
https://monolith.law/reputation/criminal-record-newspaper-database[ja]
Opsummering
Som det fremgår ovenfor, er det at “opliste mål for sletningsanmodninger fra internettet som en del af håndteringen af omdømmeskader” en meget specialiseret opgave. Vores kontor udfører denne type opgaveliste, når vi håndterer omdømmeskader, men dette arbejde forudsætter ekspertise inden for IT og internet.
Sletning af sider (eller forumindlæg) på internettet som en del af håndteringen af omdømmeskader er en opgave, der kun kan udføres af en advokat.
https://monolith.law/reputation/hiben-koui[ja]
Men på den anden side er denne opgaveliste, som hovedsageligt kræver IT- og internetkundskab, en meget krævende opgave, som vi har forklaret i denne artikel. Dette er en af de store grunde til, at man bør henvende sig til et advokatkontor med avanceret ekspertise inden for IT og internet, når man skal håndtere omdømmeskader. Det bliver gentaget, men hvis denne type liste er for let, kan følgende problemer opstå:
- Selvom alle de opregnede sider er ryddet, kan andre sider, der ikke blev vist i de globale søgeresultater på tidspunktet for opregningen, blive vist i søgeresultaterne, hvilket kræver yderligere sletning, og den oprindelige budgetberegning bliver meget forkert.
- Med hensyn til retssager, selvom det oprindeligt skulle have været nok med én gang, bliver det nødvendigt med to eller tre gange, hvilket resulterer i overdrevne omkostninger.
- Man bemærker ikke eksistensen af sider uden for det åbne web, såsom avisdatabaser, og løser derfor ikke “problemet” med for eksempel “at blive forhindret i at få et job på grund af søgning efter anholdelsesartikler”.
Dette er grunden til, at sådanne problemer kan opstå.
Category: Internet
Related Articles


En advokat forklarer, hvordan man identificerer navn og adresse på en YouTuber, der har modtaget.
Internet


Håndtering af 'Identitetstyveri' på Instagram - En vejledning til proceduren for afsløring af IP.
Internet

Hvad skal man være opmærksom på ved udsendelse af investeringsinformation på SNS? Forklaring af .
Internet

Hvordan man anmoder om sletning af indlæg, der er blevet bagtalt på det uformelle diskussionsfor.
Internet














