Explaining the Method of Scrutinizing Negative Articles on the Internet: A Prerequisite for Reputational Damage Control

When it comes to eradicating web pages related to past corporate scandals, flame wars, arrests, and criminal records, the first prerequisite is to “list all negative pages and posts without any omissions”. Without this list, it is impossible to proceed with reputational damage control while looking at the overall volume. For example, there is a risk that court procedures such as provisional dispositions and trials, which should have been completed in one go, may need to be carried out twice due to oversights.
However, listing all web pages and posts that describe a certain fact (such as corporate scandals, flame wars, arrests, and criminal records) on the Internet is by no means an “easy” task. This part requires a high level of expertise and cannot be done without know-how.
Monolith Law Office is a law firm specializing in reputational damage control, boasting a team that includes a representative lawyer who is a former IT engineer and staff specializing in the kind of internet research mentioned above. We will explain below how this internet research should be conducted.
What are Google Search Results and their Limitations?
The foundation of internet research is undoubtedly Google Search. However, when you search for the keywords you want on Google, for example, if you want to delete an arrest article, you search for keywords like “your name arrest”, there are limitations to the search results displayed in three ways.
Web Pages Subject to Google Search
There are countless web pages on the Internet. Although it is theoretically impossible to measure the total number of web pages on the Internet, it is said that the number of “websites” is currently about 1.8 billion.
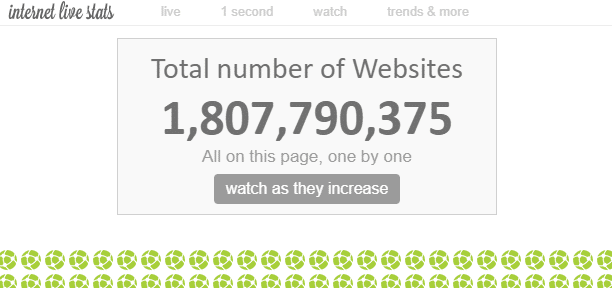
Since there are multiple web pages within a single website, the number of web pages is far greater than that.
Google search, simply put, is:
- Google’s bot (Googlebot) crawls the Internet, detects new web pages that can be opened by following links from known web pages
- Understands the content of that page (index registration)
- Displays that page in the search results when a search is conducted with the keywords contained in that page
What I want to say is that what is displayed in Google search is only the “web pages that Google has indexed in the above manner”, not “all web pages”. In other words, as long as you use Google search, you cannot find “web pages that Google has not yet indexed”, and there is no way in this world to exhaustively search all web pages on the Internet.
“Similar” Web Pages are Excluded from Search Results
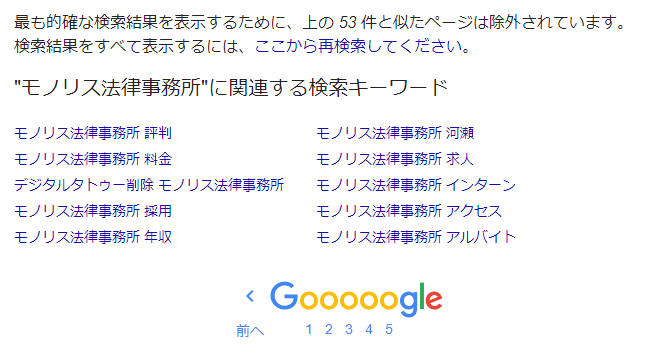
Google does not display “all web pages containing the search keyword among the indexed web pages” in its search results. You may have noticed this if you regularly use Google search. This is indicated by the message displayed on the final page of the search results: “In order to display the most accurate search results, pages similar to the above ○ items have been excluded.”
For example,
- A news story is first published on a major news site
- The news article is then reposted on news aggregation services
- The article is also reposted on personal websites, etc.
In such cases, if the same content fills the search results, it would be difficult for users to use. Therefore, Google automatically excludes “similar” pages from the search results. In the above case, items 2 and 3 would be excluded.
This is not necessarily a “user-friendly” feature if you want to “sweep away” pages that are damaging to your reputation. For example, if the “certain news” mentioned above is an article about your past arrest,
If only the “1. Original article from a major news site” was displayed in the search results and you deleted that page, the “2. Reposted article on a news aggregation service” might start appearing in Google search results because 1 has been removed
This situation could occur.
This problem can be solved by clicking on the “To display all search results, please re-search from here” section in the above display. However, if you are not aware of this feature or function, there is a possibility that you may “miss” pages that are damaging to your reputation.
There is a limit to the number of articles displayed from the same site

Furthermore, Google sets a limit on the number of search result pages displayed from a single website. This specification is a bit complex, but simply put, “a maximum of 2 pages are displayed from the same site”.
What this means is, for example, even if there are 5 Q&As featuring a company or individual’s name within Yahoo! Chiebukuro, in the search results for that company or individual’s name on Google, a maximum of 2 pages from Yahoo! Chiebukuro will be displayed. The same applies to forums and the like; even if there are 5 threads on 5chan containing a certain keyword, a maximum of 2 will be displayed in Google search results. Also, for instance, if a person has,
- An article about their arrest
- An article about their re-arrest
- An article about their guilty verdict
and these 3 articles exist on the same news site, at least one of them (3-2=1) will not be displayed in Google search results.
When searching for a certain keyword, if pages from the same site (for example, Yahoo! Chiebukuro, a specific forum, a specific news site, etc.) are lined up in large numbers in the search results, it is inconvenient for the user, so Google has this specification.
However, this specification is not necessarily “user-friendly” when you want to “sweep away defamatory pages”.
For example, if you want to remove negative Q&As from Yahoo! Chiebukuro through legal proceedings, and you look at Google search results and decide “there are only 2 targets” and proceed with the proceedings, when the removal is successful, one of the remaining 3 (5-2=3) will be displayed in the search results.
Advanced Google Search Using “Search Operators”
The feature known as “search operators” in Google is particularly necessary to solve the third problem mentioned above.
Indeed, Google sets a limit of “basically 2 pages per site” for its function of “searching for pages containing the relevant keywords from the entire Internet” (global search). However, by using the “search operator” of “keyword site: target site URL”, you can:
- Conduct a search targeting only articles within the specified site
- There is no limit of “basically 2 pages per site” for the search results
This allows you to perform such a search.
“Search operators” are actually more complex, and there are other search operators that can be used to solve problems other than the ones mentioned above.
Special Search Methods for Specific Sites
For example, Yahoo! Chiebukuro (Yahoo! Answers in Japan) has its own unique search function.
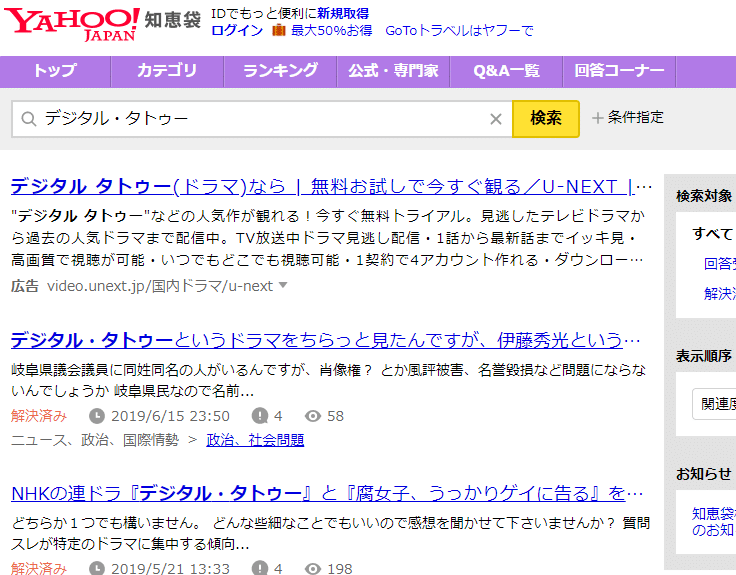
This search function does not rely on “web pages that Google has (incidentally) indexed,” but rather “results from a search conducted directly by Yahoo! Chiebukuro’s search program within its own database.” This resolves the issue we initially mentioned, that “there are web pages that Google has not yet indexed.” In other words, if the page is within Yahoo! Chiebukuro, you can find it without fail by using Yahoo! Chiebukuro’s search function.
In other words,
If a page on Yahoo! Chiebukuro is found in a global search regarding a certain fact (a company’s scandal, an individual’s arrest, etc.), using Yahoo! Chiebukuro’s search function would provide a more comprehensive list than using the “site:” search formula.
This is the point.
The same applies to Twitter. Due to the nature of its service, Twitter often has multiple tweets about a trending topic (a company’s scandal, an individual’s arrest, etc.). Not all of these tweets are necessarily indexed by Google, and not all of them are displayed in a global search.
How to Count “One” Deletion Target

The Relationship between Proper Listing and “URL”
So far, we have discussed “how to find as many web pages (URLs) as possible using Google search and other tools.” However, it’s not necessarily better to list as many as possible. This is because the target of a deletion request is not always based on the “URL.”
In the Case of 5ch (Japanese Internet forum)
This issue particularly arises with bulletin board-type sites (like 5ch and its copy sites, and other bulletin board-type sites).
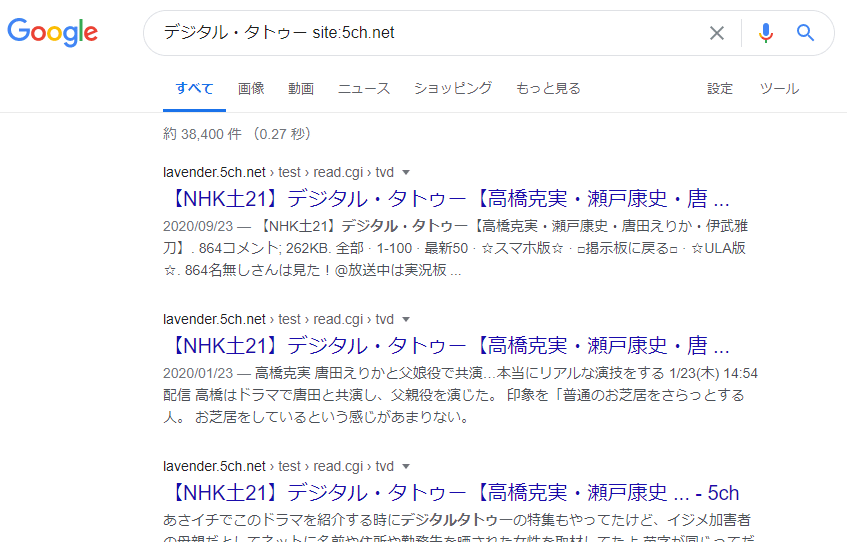
For example, if you search for a certain keyword in Google using the search formula “site:5ch.net”, meaning you are searching within 5ch, you may see URLs like the following in the search results:
- ○○○.5ch.net/test/read.cgi/○○/○○○○/40
- ○○○.5ch.net/test/read.cgi/○○/○○○○/1-100
- ○○○.5ch.net/test/read.cgi/○○/○○○○/30-
5ch has the following features:
- If you add a response number after the thread URL, only that response will be displayed.
- If you add a range of response numbers like “A-B” after the thread URL, only the responses within that range will be displayed.
- If you add a starting response number and “-” after the thread URL, all responses from that point onwards will be displayed.
In other words, if the keyword is written only in response number 40, various URLs (web pages) will appear in the “search results.”
However, when making a deletion request to a bulletin board-type site, the unit of the request is, at least in principle, the “response.” Therefore, if you want to delete response number 40, you only need to extract the URL:
- ○○○.5ch.net/test/read.cgi/○○/○○○○/40
And you don’t need to list the latter two.
In the Case of 5ch Copy Sites and Summary Sites
Furthermore, to complicate matters, even within the same 5ch (system), the unit of deletion requests for copy sites and “summary sites” is not the “response” but the “page (thread).” Which site’s deletion request target is what is entirely a matter of “know-how.”
Therefore,
- Understanding the legal unit of deletion requests
- Understanding the URL specifications of a website (for example, 5ch has complex rules as mentioned above)
Without these, it can be difficult to “list deletion targets while looking at search results.”
Searching Beyond the Open Web

So far, we have discussed sites that Google may index. However, there are also sites that:
- Google definitely does not index
- But should be considered for removal requests as part of reputational damage control
These sites do exist.
Google, due to its specifications, only considers websites that anyone can view without logging in (the open web) as search targets. However, there are also services in this world, such as “paid web services that allow you to search and view past newspaper articles in bulk (and therefore cannot be viewed without user registration or login)”.
For example, in the case of removing arrest articles, it is necessary to scrutinize the above-mentioned newspaper database sites. This is because many companies that investigate the creditworthiness of corporations and individuals often use these newspaper database sites.
For more details about newspaper database sites, please refer to the article below.
Summary
As discussed above, compiling a list of items to be removed from the internet as a measure against reputational damage is a highly specialized task. Our firm undertakes such a task when dealing with reputational damage. However, this work presupposes expertise in IT and the Internet.
Only lawyers can remove pages (or bulletin board responses) as a measure against online reputational damage.
On the other hand, this listing requires a high level of IT and Internet knowledge, as explained in this article. This is one of the major reasons why you should entrust your reputational damage measures to a law firm with advanced expertise in IT and the Internet. If the listing is not thorough, you may encounter problems such as:
- Even if all the listed pages are removed, other pages that were not displayed in the global search results at the time of listing may appear, requiring additional removal and significantly misjudging the initial budget.
- Court procedures that should have been completed in one go may require two or three times, resulting in excessive costs.
- You may not notice the existence of pages outside the open web, such as newspaper database sites, and the “problem” of being hindered in finding employment due to being searched for arrest articles may not be resolved.
These are the potential issues that could arise.
Category: Internet
Related Articles

Can Posting Someone's Photo Without Permission Be a Crime? Explaining Possible Legal Actions
Internet


How Far Can You Go with Product Promotion on YouTube? Explaining the Relationship with the Japan.
Internet

Is the Publication of Photos and Videos an Infringement of Portrait Rights? Unraveling the Stand.
Internet

What is the Method of Investigating Criminal Records such as Previous Convictions? Explanation o.
Internet















