AI„Āß„ÄĆŚ£į„Äć„āíÁĒüśąź„Āô„āč„Ā®ŤĎóšĹúś®©šĺĶŚģ≥„Āę„Ā™„āčÔľüÔľą#1 ťĖčÁôļ„ÉĽŚ≠¶ÁŅíśģĶťöéÁ∑®ÔľČ

ÁĒüśąźAI„ĀģÁôļŚĪē„Āę„āą„āä„ÄĀŚģüŚú®„Āô„āčś≠ĆśČč„āĄŚ£įŚĄ™„Āģ„ÄĆŚ£į„Äć„āíÁį°Śćė„ĀęŚ≠¶ÁŅí„ÉĽÁĒüśąź„Āô„āč„Āď„Ā®„ĀĆŚŹĮŤÉĹ„Āę„Ā™„Ā£„Ā¶„ĀĄ„Āĺ„Āô„Äā„Éď„āł„Éć„āĻ„ā∑„Éľ„É≥„Āß„āā„ÄĀ„āĘ„Éó„É™ťĖčÁôļ„ÄĀ„ā≤„Éľ„Ɇ„āĮ„É™„ā®„ā§„Éą„āĄ„āĘ„Éč„É°šĹúśąź„ĀģŚ†īťĚĘ„Āß„ÄĀAI„Āę„ÄĆŚ£į„Äć„āíŚ≠¶ÁŅí„Āē„Āõ„ÄĀśĖį„Āü„Ā™„ÄĆŚ£į„Äć„āíÁĒüśąź„Āô„āč„Āď„Ā®„ĀĆŚŹĮŤÉĹ„Āę„Ā™„āä„Āĺ„Āó„Āü„Äā
ŚģüŚú®„Āô„āčś≠ĆśČč„āĄŚ£įŚĄ™„Āģ„ÄĆŚ£į„Äć„āíÁĒüśąźAI„ĀęŚ≠¶ÁŅí„Āē„Āõ„ÄĀśĖį„Āü„Ā™„ÄĆŚ£į„Äć„āíÁĒüśąź„Āô„āč„Āď„Ā®„ĀĮ„ÄĀŤĎóšĹúś®©šĺĶŚģ≥Á≠Č„ĀģťĀēś≥ēŤ°ĆÁāļ„Āę„Ā™„ā茏ĮŤÉĹśÄß„ĀĆ„Āā„āä„Āĺ„Āô„Äā
Śģüťöõ„Āģ„Ā®„Āď„āć„ÄĀ„Āď„ĀÜ„Āó„ĀüŚēŹť°Ć„Āę„Ā§„ĀĄ„Ā¶„ÄĀÁŹĺÁä∂„ÄĀśėéÁĘļ„Ā™Ťß£ťáą„ĀĮŚáļ„Ā¶„ĀĄ„Āĺ„Āõ„āď„Äā„ĀĚ„āā„ĀĚ„āā„ÄĀ„ÄĆŚ£į„Äć„ĀģśúČ„Āô„āčś≥ēÁöĄś®©Śą©„ĀĮ„Ā©„Āģ„āą„ĀÜ„Ā™„āā„Āģ„Āß„ÄĀ„Ā©„Āģ„āą„ĀÜ„Ā™Ś†īŚźą„ĀęŤĎóšĹúś®©ś≥ēšłä„ÄĀŚēŹť°Ć„Ā®„Ā™„āč„Āģ„Āß„Āó„āá„ĀÜ„Āč„Äā
„Āď„Āď„Āß„ĀĮ„ÄĀŚÖ∑šĹďÁöĄ„Ā™Śą©ÁĒ®„ÉĎ„āŅ„Éľ„É≥„āíśÉ≥Śģö„Āó„Ā™„ĀĆ„āČ„ÄĀ„Āď„ĀģŚēŹť°Ć„āíŚČćŚĺĆÁ∑®„Āę„āŹ„Āü„Ā£„Ā¶Ťß£Ť™¨„Āó„Ā¶„ĀĄ„Āć„Āĺ„Āô„ÄāŚČćÁ∑®„Āę„Āā„Āü„āčśú¨Á®Ņ„Āß„ĀĮ„ÄĀÁĒüśąźAI„ĀģťĖčÁôļ„ÉĽŚ≠¶ÁŅíśģĶťöé„ĀߍĶ∑„Āď„āä„ĀÜ„āčś®©Śą©šĺĶŚģ≥„Āę„Ā§„ĀĄ„Ā¶Ťß£Ť™¨„Āó„Āĺ„Āô„ÄāÁĒüśąź„ÉĽŚą©ÁĒ®śģĶťöé„Āß„Āģś≥ēÁöĄŚēŹť°ĆÁāĻ„ĀĮ„Āď„Ā°„āČ„ĀģŤ®ėšļčÔľą#2 ÁĒüśąź„ÉĽŚą©ÁĒ®śģĶťöéÁ∑®ÔľČ„ĀßŤß£Ť™¨„Āó„Ā¶„Āä„āä„Āĺ„Āô„Äā„Āú„Ā≤šĹĶ„Āõ„Ā¶„ĀĒŚŹāÁÖß„ĀŹ„Ā†„Āē„ĀĄ„Äā
„Āď„ĀģŤ®ėšļč„ĀģÁõģś¨°
šļļ„Āģ„ÄĆŚ£į„Äć„ā팏Ė„āäŚ∑Ľ„ĀŹ3„Ā§„Āģś≥ēÁöĄś®©Śą©
šļļ„Āģ„ÄĆŚ£į„Äć„ĀĮ„Ā©„Āģ„āą„ĀÜ„Ā™ś≥ēÁöĄś®©Śą©„āíśúČ„Āó„Ā¶„ĀĄ„āč„Āģ„Āß„Āó„āá„ĀÜ„Āč„Äā„Āď„ĀģŚēŹť°Ć„āíŤÄÉ„Āą„āčšłä„Āß„ÄĆŚ£į„Äć„ĀęŚĮĺ„Āó„Ā¶2„Ā§„ĀģŤ¶ĖÁāĻ„āíśĆĀ„Ā§ŚŅÖŤ¶Ā„ĀĆ„Āā„āä„Āĺ„Āô„Äā
- „ĀĚ„ĀģŚ£į„ĀĆšĹē„āíŚĖč„Ā£„Ā¶„ĀĄ„āč„Āč„ÄĀ
- „ĀĚ„ĀģŚ£į„ĀĆ„Ā©„Āģ„āą„ĀÜ„Ā™ťü≥Ś£į„ĀߌĖč„Ā£„Ā¶„ĀĄ„āč„Āč
„Ā§„Āĺ„āä„ÄĀ1„Ā§Áõģ„ĀĮ„ÄĀŚ£į„Āģ„ÄĆŚÜÖŚģĻ„Äć„ĀģŚēŹť°Ć„ÄĀ2„Ā§Áõģ„ĀĮ„ÄĀŚ£į„Āģ„ÄĆťü≥„Äć„ĀģŚēŹť°Ć„Ā®Śąá„ā䌹܄ĀĎ„āč„Āď„Ā®„ĀĆ„Āß„Āć„Āĺ„Āô„Äā
šĺč„Āą„Āį„ÄĀŚźĆ„Āė„ÄĆ„Āä„ĀĮ„āą„ĀÜ„ĀĒ„ĀĖ„ĀĄ„Āĺ„Āô„Äć„Ā®„ĀĄ„ĀÜ„āĽ„É™„Éē„āíťĀē„ĀÜŚ£įŚĄ™„ĀĆśľĒ„Āė„Ā¶„ĀĄ„ā茆īŚźą„ÄĀ1„Ā§Áõģ„ĀģŚÜÖŚģĻ„ĀĮŚźĆ„Āė„Āß„Āô„ĀĆ„ÄĀ2„Ā§Áõģ„Āģťü≥„ĀĆÁēį„Ā™„āč„Ā®„ĀĄ„ĀÜ„Āď„Ā®„Āę„Ā™„āä„Āĺ„Āô„Äā
„Āď„āĆ„āČ„ĀģŤ¶ĖÁāĻ„Āģ„āā„Ā®„ÄĀÁŹĺŤ°Ćś≥ēšłä„ÄĀšļļ„Āģ„ÄĆŚ£į„Äć„ĀęÁôļÁĒü„Āó„ĀÜ„āčś≥ēÁöĄś®©Śą©„ĀĮšĽ•šłč„Āģ3„Ā§„ĀĆ„Āā„āč„Ā®ŤÄÉ„Āą„āČ„āĆ„Āĺ„Āô„Äā
| ‚φŤĎóšĹúś®© | Ś£į„Āģ„ÄĆŚÜÖŚģĻ„Äć„Āę„Ā§„ĀĄ„Ā¶ÁĒü„ĀėŚĺó„āč |
| ‚Ď°ŤĎóšĹúťö£śé•ś®©ÔľąŚģüśľĒŚģ∂„Āģś®©Śą©„Āęťôź„āčÔľČ | Ś£į„Āģ„ÄĆŚÜÖŚģĻ„Äć„ÄĆťü≥„Äć„Āę„Ā§„ĀĄ„Ā¶ÁĒü„ĀėŚĺó„āč |
| ‚ĎĘ„ÉĎ„ÉĖ„É™„ā∑„ÉÜ„ā£ś®© | Ś£į„Āģ„ÄĆťü≥„Äć„Āę„Ā§„ĀĄ„Ā¶ÁĒü„ĀėŚĺó„āč |
ŤĎóšĹúś®©„Āę„Ā§„ĀĄ„Ā¶
ŤĎóšĹúś®©„ĀĮ„ÄĀ„ĀĚ„ĀģŚ£į„Āģ„ÄĆŚÜÖŚģĻ„Äć„ĀĆŤĎóšĹúÁČ©„Āꍩ≤ŚĹď„Āô„ā茆īŚźą„ĀęÁôļÁĒü„Āó„Āĺ„Āô„Äā
šĺč„Āą„Āį„ÄĀśúČŚźćŚįŹŤ™¨„āíśúóŤ™≠„Āô„ā茆īŚźą„ÄĀ„ĀĚ„ĀģŚ£į„Āę„ĀĮ„ÄĀŤĎóšĹúś®©„ĀĆÁôļÁĒü„Āô„ā茏ĮŤÉĹśÄß„ĀĆ„Āā„āä„Āĺ„Āô„Äā„Āü„Ā†„ÄĀś≥®śĄŹ„Āó„Ā™„ĀĎ„āĆ„Āį„Ā™„āČ„Ā™„ĀĄ„Āģ„ĀĮ„ÄĀ„Āď„Āģ„āą„ĀÜ„Ā™Ś†īŚźą„ĀģŤĎóšĹúś®©ŤÄÖ„ĀĮ„ÄĀŚĹ≤ŚįŹŤ™¨„ĀģŚü∑Á≠ÜŤÄÖ„Āß„Āā„āä„ÄĀ„ÄĆŚ£į„ĀģšłĽÔľĚÁôļŚ£įŤÄÖ„Äć„Āß„ĀĮ„Ā™„ĀĄ„Āď„Ā®„Āß„Āô„Äā„Āô„Ā™„āŹ„Ā°„ÄĀÁĒüśąźAI„ĀßśúČŚźć„Ā™ŚįŹŤ™¨„ĀģŚÜÖŚģĻ„āíśúóŤ™≠„Āô„ā茟ąśąźťü≥Ś£į„āíšĹúśąź„Āó„ĀüŚ†īŚźą„ÄĀŚĹ≤Ť°ĆÁāļ„ĀĮ„ÄĀŚįŹŤ™¨„ĀģŚü∑Á≠ÜŤÄÖ„ĀģŤĎóšĹúś®©„āíšĺĶŚģ≥„Āô„ā茏ĮŤÉĹśÄß„ĀĆ„Āā„āä„Āĺ„Āô„Äā
„Āď„āĆ„ĀęŚĮĺ„Āó„ÄĀ„ĀĚ„ĀģŚ£į„ĀģŚÜÖŚģĻ„ĀĆšłÄŤą¨šļļ„Āģ„Āā„āä„ĀĶ„āĆ„Āüśó•ŚłłšľöŤ©Ī„Ā™„Ā©„āíŚÜÖŚģĻ„Ā®„Āô„ā茆īŚźą„ÄĀ„ĀĚ„ĀģŚ£į„Āę„ĀĮŤĎóšĹúś®©„ĀĮÁôļÁĒü„Āó„Āĺ„Āõ„āď„Äā„Āď„āĆ„ĀĮ„ÄĀ„Āā„āä„ĀĶ„āĆ„Āüśó•ŚłłšľöŤ©Ī„ĀĆ„ĀĚ„āā„ĀĚ„āāŤĎóšĹúÁČ©„Āę„Āā„Āü„āČ„Āö„ÄĀŤĎóšĹúś®©ś≥ē„ĀģšŅĚŤ≠∑ŚĮĺŤĪ°„Āß„ĀĮ„Ā™„ĀĄ„Āü„āĀ„Āß„Āô„Äā
ŤĎóšĹúťö£śé•ś®©„Āę„Ā§„ĀĄ„Ā¶
ŤĎóšĹúťö£śé•ś®©ÔľąŚģüśľĒŚģ∂„Āģś®©Śą©„Āęťôź„āčԾȄĀĮ„ÄĀ„ĀĚ„ĀģŚ£į„ĀģŚÜÖŚģĻ„ĀĆŤĎóšĹúÁČ©„Āꍩ≤ŚĹď„Āô„āč„āą„ĀÜ„Ā™Ś†īŚźą„Āß„Āā„Ā£„Ā¶„ÄĀ„ĀĚ„ĀģŚ£į„ĀĆśúóŤ™≠„Ā™„Ā©„ĀģŚĹĘśÖč„āíšľī„Ā£„Ā¶„ĀĄ„ā茆īŚźą„ĀęÁôļÁĒü„ĀóŚĺó„Āĺ„Āô„Äā
šłäŤ®ėŤĎóšĹúś®©„Āģť†Ö„Āß„āāŤß¶„āĆ„Āü„āą„ĀÜ„Ā™Ś†īŚźą„ÄĀ„ĀĚ„ĀģŚ£į„ĀĮ„ÄĆśúóŤ™≠„Äć„Ā®„ĀĄ„ĀÜ„ÄĆŚģüśľĒ„Äć„ā퍰ƄĀ£„Ā¶„ĀĄ„āč„Āď„Ā®„Āę„Ā™„āč„Āü„āĀ„ÄĀśúóŤ™≠ŤÄÖ„ĀęŤĎóšĹúťö£śé•ś®©„ĀĆÁĒü„Āė„ā茏ĮŤÉĹśÄß„ĀĆ„Āā„āä„Āĺ„Āô„ÄāšłäŤ®ėŤĎóšĹúś®©„ĀģŚ†īŚźą„Ā®„ĀĮÁēį„Ā™„āä„ÄĀŤĎóšĹúťö£śé•ś®©ŤÄÖ„ĀĮ„Āā„ĀŹ„Āĺ„ĀߌįŹŤ™¨„ĀģŚü∑Á≠ÜŤÄÖ„Āß„ĀĮ„Ā™„ĀŹ„ÄĀŚģüťöõ„ĀęÁôļŚ£į„Āó„Ā¶„ĀĄ„āčśúóŤ™≠ŤÄÖ„Āß„Āā„āč„Āď„Ā®„Āęś≥®śĄŹ„āí„Āô„āčŚŅÖŤ¶Ā„ĀĆ„Āā„āä„Āĺ„Āô„Äā
„ÉĎ„ÉĖ„É™„ā∑„ÉÜ„ā£ś®©„Āę„Ā§„ĀĄ„Ā¶
„ÉĎ„ÉĖ„É™„ā∑„ÉÜ„ā£ś®©„Ā®„ĀĮ„ÄĆšļļ„ĀģśįŹŚźć„ÄĀŤāĖŚÉŹÁ≠Č„ĀĆśúČ„Āô„ā蝰ߌģĘŤ™ėŚľēŚäõ„āíśé횼ĖÁöĄ„Āꌹ©ÁĒ®„Āô„āčś®©Śą©„Äć„Ā®„Āó„Ā¶„ÄĀŚą§šĺčś≥ēÁźÜÔľąśúÄŚą§H24.2.2ԾȄĀę„āą„Ā£„Ā¶Ť™ć„āĀ„āČ„āĆ„Āüś®©Śą©„Āß„Āô„Äā
| ‚Ė∂ÔłéśúÄŚą§H24.2.2Ôľą„ÉĒ„É≥„āĮ„ɨ„Éá„ā£„Éľšļ蚼∂ÔľČ ‚Ė†Śą§Á§ļŚÜÖŚģĻ ‚φśįŹŚźć„ÄĀŤāĖŚÉŹÁ≠Č„ĀĚ„āƍᙚĹď„āíÁč¨Áęč„Āó„Ā¶ťĎĎŤ≥ě„ĀģŚĮĺŤĪ°„Ā®„Ā™„āčŚēÜŚďĀÁ≠Č„Ā®„Āó„Ā¶šĹŅÁĒ®„Āó„ÄĀ ‚Ď°ŚēÜŚďĀÁ≠Č„ĀģŚ∑ģŚą•ŚĆĖ„āíŚõ≥„āčÁõģÁöĄ„ĀßśįŹŚźć„ÄĀŤāĖŚÉŹÁ≠Č„āíŚēÜŚďĀÁ≠Č„Āꚼė„Āó„ÄĀ ‚ĎĘśįŹŚźć„ÄĀŤāĖŚÉŹÁ≠Č„āíŚēÜŚďĀÁ≠Č„ĀģŚļÉŚĎä„Ā®„Āó„Ā¶šĹŅÁĒ®„Āô„āč„Ā™„Ā©„ÄĀŚįā„āČśįŹŚźć„ÄĀŤāĖŚÉŹÁ≠Č„ĀģśúČ„Āô„ā蝰ߌģĘŚźłŚľēŚäõ„ĀģŚą©ÁĒ®„āíÁõģÁöĄ„Ā®„Āô„ā茆īŚźą„Āę„ĀĮ„ÄĀ„ÉĎ„ÉĖ„É™„ā∑„ÉÜ„ā£ś®©šĺĶŚģ≥„Ā®„Āó„Ā¶šłćś≥ēŤ°ĆÁāļšłäťĀēś≥ē„Ā®„Ā™„āč ‚Ė†Ť™ŅśüĽŚģėŤß£Ť™¨ÔľąśúÄťęėŤ£ĀŚą§śČÄŚą§šĺčŤß£Ť™¨„ÉĽśįĎšļčÁĮáŚĻ≥śąź24ŚĻīŚļ¶ÔľąšłäÔľČ18ť†ĀԾȜú¨Śą§śĪļ„Āģ3ť°ěŚěč„Āę„ĀĄ„ĀÜ„ÄĆŤāĖŚÉŹÁ≠Č„Äć„Ā®„ĀĮ„ÄĀśú¨šļļ„ĀģšļļÁČ©Ť≠ėŚą•śÉÖŚ†Ī„āí„ĀĄ„ĀÜ„āā„Āģ„Āß„Āā„āä„ÄĀšĺč„Āą„Āį„ÄĀ„āĶ„ā§„É≥„ÄĀÁĹ≤Śźć„ÄĀŚ£į„ÄĀ„Éö„É≥„Éć„Éľ„Ɇ„ÄĀŤäłŚźćÁ≠Č„ā팟ę„āÄ„āā„Āģ„Āß„Āā„āč |
„ÉĒ„É≥„āĮ„ɨ„Éá„ā£„Éľšļ蚼∂„Āę„āą„āĆ„Āį„ÄĀŚ£į„Āę„āā„ÉĎ„ÉĖ„É™„ā∑„ÉÜ„ā£ś®©„ĀĆÁôļÁĒü„Āô„āčšĹôŚúį„ĀĆ„Āā„āä„Āĺ„Āô„Äā„ĀĚ„Āó„Ā¶„ÄĀŚĹ≤Ś£į„ĀĆ„ÄĀŚģüŚú®„ĀģŚ£įŚĄ™„āĄšŅ≥ŚĄ™„ÄĀś≠ĆśČč„Ā™„Ā©„Āģ„āą„ĀÜ„Ā™ť°ßŚģĘŚźłŚľēŚäõ„ĀĆ„Āā„āčšļļÁČ©„Āģ„āā„Āģ„Āß„Āā„āč„āā„Āģ„Ā®Ť™ćŚģö„Āß„Āć„āĆ„Āį„ÄĀ„ĀĚ„Āģ„ÄĆŚÜÖŚģĻ„Äć„ĀęťĖĘ„āŹ„āČ„Āö„ÄĀ„ÉĎ„ÉĖ„É™„ā∑„ÉÜ„ā£ś®©„ĀĆÁôļÁĒü„Āó„Āĺ„Āô„Äā„ĀĚ„Āó„Ā¶„ÄĀ„ÉĒ„É≥„āĮ„ɨ„Éá„ā£„Éľšļ蚼∂„ĀģŚą§Á§ļ„Āó„Āü3„Ā§„ĀģšĺĶŚģ≥śÖčśßė„Āģ„ĀĄ„Āö„āĆ„Āč„ĀģśÖčśßė„ĀߌĹ≤Ś£į„ā팹©ÁĒ®„Āô„āĆ„Āį„ÄĀ„ÉĎ„ÉĖ„É™„ā∑„ÉÜ„ā£ś®©šĺĶŚģ≥„Āꍩ≤ŚĹď„Āó„Āĺ„Āô„Äā
ťĖčÁôļ„ÉĽŚ≠¶ÁŅíśģĶťöé„Āß„Āģ3„Ā§„ĀģŚą©ÁĒ®„ÉĎ„āŅ„Éľ„É≥
Śćė„Āę„ÄĆÁĒüśąźAI„Āߌ£į„āíÁĒüśąź„Āô„āč„Äć„Ā®Ť®Ä„Ā£„Ā¶„āā„ÄĀ„ĀĚ„ĀģŚ∑•Á®č„ĀĮšĽ•šłč„Āģ2„Ā§„Āꌹ܄ĀĎ„Ā¶ŤÄÉ„Āą„āčŚŅÖŤ¶Ā„ĀĆ„Āā„āä„Āĺ„Āô„Äā
- ťĖčÁôļ„ÉĽŚ≠¶ÁŅíśģĶťöé
- ÁĒüśąź„ÉĽŚą©ÁĒ®śģĶťöé
„ĀĚ„Āó„Ā¶„ÄĀ1„ĀĮAIťĖčÁôļŤÄÖ„Āę„āą„Ā£„Ā¶„ÄĀ2„ĀĮAIŚą©ÁĒ®ŤÄÖ„Āę„āą„Ā£„Ā¶Ť°Ć„āŹ„āĆ„āčŚ∑•Á®č„Āę„Ā™„āä„Āĺ„Āô„Äā
„Āď„āĆ„āČ„ĀģŚ∑•Á®č„āíŚõ≥ŚľŹŚĆĖ„Āô„āč„Ā®šĽ•šłč„ĀģťÄö„āä„Āß„Āô„Äā
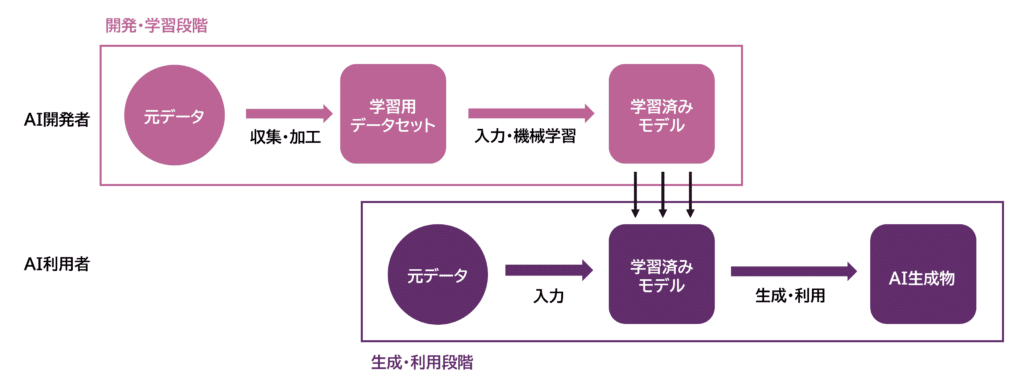
ťĖčÁôļ„ÉĽŚ≠¶ÁŅíśģĶťöé„Āß„ĀĮ„ÄĀAIťĖčÁôļ„ĀģŚ≠¶ÁŅíÁĒ®„Éá„Éľ„āŅ„Ā®„Āó„Ā¶„ÄĀšļļ„ĀģŚ£į„ĀģŚÖÉ„Éá„Éľ„āŅ„ā팏éťõÜ„ÉĽŤďĄÁ©ć„Āó„ÄĀŚ≠¶ÁŅíÁĒ®„Éá„Éľ„āŅ„āĽ„ÉÉ„Éą„āíšĹúśąź„Āó„Āĺ„Āô„Äā„ĀĚ„ĀģŚĺĆ„ÄĀŚ≠¶ÁŅíÁĒ®„Éá„Éľ„āŅ„āĽ„ÉÉ„Éą„āíAI„ĀęŚÖ•Śäõ„Āó„ÄĀś©üśĘįŚ≠¶ÁŅí„ā퍰ƄĀĄ„ÄĀŚ≠¶ÁŅíśłą„ĀŅ„Āģ„ÉĘ„Éá„Éę„āíšĹúśąź„Āó„Āĺ„Āô„ÄāšłÄśĖĻ„ÄĀÁĒüśąź„ÉĽŚą©ÁĒ®śģĶťöé„Āß„ĀĮ„ÄĀŚÖÉ„Éá„Éľ„āŅ„āíś©üśĘįŚ≠¶ÁŅí„āíÁĶā„Āą„ĀüÁĒüśąźAI„ĀęŚÖ•Śäõ„Āó„ÄĀAIÁĒüśąźÁČ©„āíÁĒüśąź„ÉĽŚą©ÁĒ®„Āó„Āĺ„Āô„Äā
ťĖčÁôļ„ÉĽŚ≠¶ÁŅíśģĶťöé„ĀģŚą©ÁĒ®„ÉĎ„āŅ„Éľ„É≥„Ā®„Āó„Ā¶„ĀĮšĽ•šłč„Āģ3„ÉĎ„āŅ„Éľ„É≥„āíśÉ≥Śģö„Āô„āč„Āď„Ā®„ĀĆ„Āß„Āć„Āĺ„Āô„Äā
- „ÉĎ„āŅ„Éľ„É≥1ÔľöAIťĖčÁôļ„Āģ„Āü„āĀ„ĀģŚ≠¶ÁŅíÁĒ®„Éá„Éľ„āŅ„Ā®„Āó„Ā¶šļļ„ĀģŚ£į„Éá„Éľ„āŅ„ā팏éťõÜ„ÉĽŤďĄÁ©ć„ÉĽŚä†Ś∑•„ÉĽŚą©ÁĒ®„Āô„ā荰ĆÁāļ
- „ÉĎ„āŅ„Éľ„É≥2ÔľöAIťĖčÁôļ„ĀęÁĒ®„ĀĄ„āČ„āĆ„āčŚ≠¶ÁŅíÁĒ®„Éá„Éľ„āŅ„āĽ„ÉÉ„Éą„ĀģŤ≤©Ś£≤„ÉĽŚÖ¨ťĖ荰ĆÁāļ
- „ÉĎ„āŅ„Éľ„É≥3ÔľöÁĒüśąźAI„ĀĚ„Āģ„āā„Āģ„ĀģŤ≤©Ś£≤„ÉĽŚÖ¨ťĖ荰ĆÁāļ
šĽ•šłč„ÄĀ„ĀĚ„āĆ„Āě„āĆ„ĀģŚą©ÁĒ®„ÉĎ„āŅ„Éľ„É≥„Āę„Āä„ĀĄ„Ā¶„ÄĀ„Ā©„Āģ„āą„ĀÜ„Ā™ś®©Śą©šĺĶŚģ≥„ā팾ē„ĀćŤĶ∑„Āď„ĀôŚŹĮŤÉĹśÄß„ĀĆ„Āā„āč„Āč„Āę„Ā§„ĀĄ„Ā¶Áį°Śćė„ĀęŤß£Ť™¨„Āó„Ā¶„ĀĄ„Āć„Āĺ„Āô„Äā
„ÉĎ„āŅ„Éľ„É≥1ÔľöAIťĖčÁôļ„Āģ„Āü„āĀ„ĀģŚ≠¶ÁŅíÁĒ®„Éá„Éľ„āŅ„Ā®„Āó„Ā¶šļļ„ĀģŚ£į„Éá„Éľ„āŅ„ā팏éťõÜ„ÉĽŤďĄÁ©ć„ÉĽŚä†Ś∑•„ÉĽŚą©ÁĒ®„Āô„āč

„Āĺ„Āö„ÄĀAI„āíŚ≠¶ÁŅí„Āē„Āõ„āč„Āü„āĀ„Āģšļļ„ĀģŚ£į„āí„Éá„Éľ„āŅ„ā팏éťõÜ„ÉĽŤďĄÁ©ć„ÉĽŚä†Ś∑•„Āó„ÄĀŚ≠¶ÁŅí„Āꌹ©ÁĒ®„Āô„āčśģĶťöé„Āę„Āä„ĀĄ„Ā¶ŤĶ∑„Āď„āä„ĀÜ„āčś®©Śą©šĺĶŚģ≥„Āę„Ā§„ĀĄ„Ā¶Ťß£Ť™¨„Āó„Āĺ„Āô„Äā
ŤĎóšĹúś®©„Ā®„ĀģťĖĘšŅā
„ÉĎ„āŅ„Éľ„É≥1„ĀģŚą©ÁĒ®Ť°ĆÁāļ„ĀĮ„ÄĀŚÖ∑šĹďÁöĄ„ĀꍮĄĀÜ„Ā®„ÄĀÁĒüśąźAI„ĀĚ„Āģ„āā„Āģ„āíťĖčÁôļ„Āô„ā荰ĆÁāļ„ĀĆ„Āď„āĆ„ĀęŚĹď„Āü„āä„Āĺ„Āô„Äā„ĀĚ„Āó„Ā¶„ÄĀAI„ĀģťĖčÁôļ„ĀĮŤĎóšĹúś®©ś≥ēÔľąś≥ēŚźćšĽ•šłčÁē•ÔľČÁ¨¨30śĚ°„Āģ4Á¨¨2ŚŹ∑„Āģ„ÄĆśÉÖŚ†ĪŤß£śěź„Äć„ĀęŚĹď„Āü„āč„Āü„āĀ„ÄĀ„ĀĚ„āĆ„ĀęŚŅÖŤ¶Ā„Ā™ŤĎóšĹúÁČ©„ĀģŚą©ÁĒ®Ť°ĆÁāļ„ĀĮŚéüŚČáŤĎóšĹúś®©šĺĶŚģ≥„Ā®„ĀĮ„Ā™„āä„Āĺ„Āõ„āďÔľąÁ¨¨30śĚ°„Āģ4ԾȄÄā
„āā„Ā£„Ā®„āāšłäŤ®ė„Āę„ĀĮťá挧߄Ā™šĺ茧Ė„ĀĆ„Āā„āä„Āĺ„Āô„Äā„ĀĚ„āĆ„ĀĮ„ÄĀŚ≠¶ÁŅíÁĒ®„Éá„Éľ„āŅ„āĽ„ÉÉ„Éą„āíšĹúśąź„Āô„āčšłä„Āß„ÄĀŚÖÉ„Éá„Éľ„āŅ„ĀĆśúČ„Āô„ā荰®ÁŹĺšłä„Āģśú¨Ť≥™ÁöĄÁČĻŚĺī„āíśúČ„Āô„āčAIÁĒüśąźÁČ©„āíÁĒüśąź„Āô„āčÁõģÁöĄÔľąŤ°®ÁŹĺŚáļŚäõÁõģÁöĄÔľČ„ĀĆ„Āā„ā茆īŚźą„Āę„ĀĮ„ÄĀ30śĚ°„Āģ4„ĀĮťĀ©ś≥ē„Āē„āĆ„Āö„ÄĀťĀēś≥ē„Ā®„Ā™„āč„Āď„Ā®„Āß„Āô„Äā
„Āô„Ā™„āŹ„Ā°„ÄĀ„Āā„āčÁČĻŚģö„ĀģŚ£įŚĄ™„ĀĆśúČ„Āó„Ā¶„ĀĄ„āčÁČĻŚĺīÁöĄ„Ā™Ś£į„āíŚÜćÁŹĺ„ÄĀ„Āĺ„Āü„ĀĮ„ā™„Éě„Éľ„āł„É•„Āô„āč„āą„ĀÜ„Ā™Ś†īŚźą„Āę„ÄĀšĽĖ„ĀģŚ£įŚĄ™„ĀģŚ£į„Éá„Éľ„āŅ„ā팹©ÁĒ®„Āó„ĀüŚ†īŚźą„ÄĀŤ°®ÁŹĺŚáļŚäõÁõģÁöĄ„ĀĆ„Āā„āč„Ā®„Āó„Ā¶„ÄĀŚĹ≤Śą©ÁĒ®Ť°ĆÁāļ„ĀĮŤĎóšĹúś®©šĺĶŚģ≥„Āꍩ≤ŚĹď„Āô„ā茏ĮŤÉĹśÄß„ĀĆ„Āā„āä„Āĺ„Āô„Äā
ŤĎóšĹúťö£śé•ś®©„Ā®„ĀģťĖĘšŅā
ŤĎóšĹúťö£śé•ś®©„Ā®„ĀģťĖĘšŅā„Āß„āā„ÄĀÁ¨¨102śĚ°„Āę„āą„āäŤĎóšĹúś®©„Āę„Ā§„ĀĄ„Ā¶„ĀģŤ¶ŹŚģö„Āß„Āā„āčÁ¨¨30śĚ°„Āģ4„ĀĆśļĖÁĒ®„Āē„āĆ„Ā¶„ĀĄ„Āĺ„Āô„Āģ„Āß„ÄĀÁĒüśąźAI„āíťĖčÁôļ„Āô„āč„Āü„āĀ„ĀęŚģüśľĒÁ≠Č„ā퍰ƄĀ£„Ā¶„āāŚéüŚČá„Ā®„Āó„Ā¶„ÄĀŤĎóšĹúťö£śé•ś®©šĺĶŚģ≥„Āę„ĀĮŚĹď„Āü„āä„Āĺ„Āõ„āď„Äā
„ÉĎ„ÉĖ„É™„ā∑„ÉÜ„ā£ś®©„Ā®„ĀģťĖĘšŅā
„ÉĎ„ÉĖ„É™„ā∑„ÉÜ„ā£ś®©„Ā®„ĀģťĖĘšŅā„ĀĆŚēŹť°Ć„Ā®„Ā™„ā茆īťĚĘ„ĀĮ„ÄĀť°ßŚģĘŚźłŚľēŚäõ„Āģ„Āā„āčÁČĻŚģö„ĀģŤĎóŚźćšļļ„Āģ„ÄĆŚ£į„Äć„ĀģÁĒüśąź„āíÁõģÁöĄ„Ā®„Āó„ĀüÁĒüśąźAI„ĀģťĖčÁôļ„ĀĆśÉ≥Śģö„Āē„āĆ„Āĺ„Āô„Äā
„ÉĎ„ÉĖ„É™„ā∑„ÉÜ„ā£ś®©šĺĶŚģ≥„āíśßčśąź„Āô„āč„Ā茟¶„Āč„Āę„Ā§„ĀĄ„Ā¶„ĀĮ„ÄĀšłäśé≤„ÉĒ„É≥„āĮ„ɨ„Éá„ā£šļ蚼∂„ĀģšĺĶŚģ≥śÖčśßė3ť°ěŚěč„ĀĆŚŹāŤÄÉ„Āę„Ā™„āä„Āĺ„Āô„Äā
„Āĺ„Āö„ÄĀÁČĻŚģö„ĀģŤĎóŚźćšļļ„Āģ„ÄĆŚ£į„Äć„ĀģÁĒüśąź„āíÁõģÁöĄ„Ā®„Āó„ĀüÁĒüśąźAI„ĀģťĖčÁôļŤ°ĆÁāļ„ĀĚ„āƍᙚĹď„ĀĮ„ÄĀšłäśé≤„ÉĒ„É≥„āĮ„ɨ„Éá„ā£šļ蚼∂„ĀģšĺĶŚģ≥śÖčśßė3ť°ěŚěč„Āę„ĀĮŤ©≤ŚĹď„Āó„Āĺ„Āõ„āď„Äā„āā„Ā£„Ā®„āā„ÄĀŚĹ≤Ť°ĆÁāļ„ĀĆ„ÄĆŚįā„āČśįŹŚźć„ÄĀŤāĖŚÉŹÁ≠Č„ĀģśúČ„Āô„ā蝰ߌģĘŚźłŚľēŚäõ„ĀģŚą©ÁĒ®„āíÁõģÁöĄ„Ā®„Āô„ā茆īŚźą„Äć„Āꍩ≤ŚĹď„Āô„āĆ„Āį„ÄĀ„ÉĎ„ÉĖ„É™„ā∑„ÉÜ„ā£ś®©šĺĶŚģ≥„Ā®„Āó„Ā¶šłćś≥ēŤ°ĆÁāļ„āíśßčśąź„ĀóŚĺó„Āĺ„Āô„Äā
ť°ßŚģĘŚźłŚľēŚäõ„ĀģŚą©ÁĒ®„ĀĆÁĒü„ĀėŚĺó„āč„Āü„āĀ„Āę„ĀĮ„ÄĀÁĒüśąźAI„ĀģťĖčÁôļśģĶťöé„ÄĀ„Ā®„āä„āŹ„ĀĎŚ≠¶ÁŅíÁĒ®„Éá„Éľ„āŅ„āĽ„ÉÉ„Éą„āíšĹúśąź„Āô„āčťöõ„Āę„ÄĀÁ¨¨šłČŤÄÖ„ĀĆŚĹ≤ŤĎóŚźćšļļ„ĀģŚ£į„Āß„Āā„āč„Āď„Ā®„āíÁü•Ť¶ö„Āô„āčŚŅÖŤ¶Ā„ĀĆ„Āā„āä„Āĺ„Āô„Äāť°ßŚģĘ„Āü„āčÁ¨¨šłČŤÄÖ„ĀĆÁü•Ť¶ö„Āó„Ā™„ĀĎ„āĆ„Āį„ÄĀ„ĀĚ„āā„ĀĚ„āāť°ßŚģĘŤ™ėŚľē„ĀĮÁĒü„ĀėŚĺó„Ā™„ĀĄ„Āü„āĀ„Āß„Āô„Äā„Āó„Āč„Āó„ÄĀťÄöŚłłÁĒüśąźAI„ĀģťĖčÁôļśģĶťöé„Āę„Āä„ĀĄ„Ā¶ť°ßŚģĘ„Āü„āčÁ¨¨šłČŤÄÖ„ĀĆšĽčŚú®„Āô„āčšĹôŚúį„ĀĮ„Āā„āä„Āĺ„Āõ„āď„Äā
„Āó„Āü„ĀĆ„Ā£„Ā¶„ÄĀŚĹ≤Śą©ÁĒ®Ť°ĆÁāļ„ĀĮ„ÉĎ„ÉĖ„É™„ā∑„ÉÜ„ā£ś®©šĺĶŚģ≥„Ā®„Ā™„āčšĹôŚúį„ĀĮ„ĀĽ„Ā®„āď„Ā©„Ā™„ĀĄ„Ā®Ť®Ä„Āą„Āĺ„Āô„Äā
„ÉĎ„āŅ„Éľ„É≥2ÔľöAIťĖčÁôļ„ĀęÁĒ®„ĀĄ„āČ„āĆ„āčŚ≠¶ÁŅíÁĒ®„Éá„Éľ„āŅ„āĽ„ÉÉ„Éą„ĀģŤ≤©Ś£≤„ÉĽŚÖ¨ťĖč
„Āď„Āď„Āß„ĀĮ„ÄĀAIŚ≠¶ÁŅíÁĒ®„Éá„Éľ„āŅ„āĽ„ÉÉ„Éą„ĀģŤ≤©Ś£≤„ÉĽŚÖ¨ťĖč„ĀģśģĶťöé„Āę„Āä„ĀĄ„Ā¶ŤĶ∑„Āď„āä„ĀÜ„āčś®©Śą©šĺĶŚģ≥„Āę„Ā§„ĀĄ„Ā¶Ťß£Ť™¨„Āó„Āĺ„Āô„Äā
ŤĎóšĹúś®©„Ā®„ĀģťĖĘšŅā
Ś≠¶ÁŅíÁĒ®„Éá„Éľ„āŅ„āĽ„ÉÉ„Éą„Āģšł≠„Āę„ÄĀŚÖÉ„Éá„Éľ„āŅ„ĀĆ„ĀĚ„Āģ„Āĺ„Āĺ„ĀģŚĹĘŚľŹ„ÄĀ„Āā„āč„ĀĄ„ĀĮŚ§öŚįό䆌∑•„Āē„āĆ„ĀüŚĹĘ„ĀßšŅĚŚ≠ė„Āē„āĆ„Ā¶„ĀĄ„ā茆īŚźą„ÄĀŚ≠¶ÁŅíÁĒ®„Éá„Éľ„āŅ„āĽ„ÉÉ„Éą„ĀģŤ≤©Ś£≤„ÉĽŚÖ¨ťĖ荰ĆÁāļ„ĀĮ„ÄĀŚĹ≤ŤĎóšĹúÁČ©„ÄĀ„Āā„āč„ĀĄ„ĀĮšļĆś¨°ÁöĄŤĎóšĹúÁČ©ÔľąÁ¨¨28śĚ°ÔľČ„ĀģŤ≠≤śł°ś®©šĺĶŚģ≥ÔľąÁ¨¨26śĚ°„Āģ2ԾȄÄĀŚÖ¨Ť°ÜťÄĀšŅ°ś®©šĺĶŚģ≥ÔľąÁ¨¨23śĚ°ÔľČ„āíśßčśąź„Āó„Āĺ„Āô„Äā„ĀĚ„Āģ„Āü„āĀ„ÄĀŤĎóšĹúś®©ŤÄÖ„ĀģŚźĆśĄŹ„Ā™„ĀŹŤ°Ć„ĀÜ„Ā®ŤĎóšĹúś®©šĺĶŚģ≥„Ā®„Ā™„āä„Āĺ„Āô„Äā
„āā„Ā£„Ā®„āā„ÄĀšłäŤ®ėŚźĆśßėÁ¨¨30śĚ°„Āģ4„ĀĮ„ÄĀ„ÄĆśÉÖŚ†ĪŤß£śěź„ĀģÁĒ®„Āęšĺõ„Āô„ā茆īŚźą„Äć„Āę„ĀĮ„ÄĆ„ĀĚ„ĀģŚŅÖŤ¶Ā„Ā®Ť™ć„āĀ„āČ„āĆ„āčťôźŚļ¶„Āę„Āä„ĀĄ„Ā¶„ÄĀ„ĀĄ„Āö„āĆ„ĀģśĖĻś≥ē„Āę„āą„āč„Āč„āíŚēŹ„āŹ„Āö„ÄĀŚą©ÁĒ®„Āô„āč„Āď„Ā®„ĀĆ„Āß„Āć„āč„Äć„Ā®Śģö„āĀ„Ā¶„ĀĄ„Āĺ„Āô„Äā„ĀĚ„Āģ„Āü„āĀ„ÄĀÁĒüśąźAI„āíťĖčÁôļ„Āô„āč„Āü„āĀ„ĀęŤ≠≤śł°„āĄŚÖ¨ťĖč„ā퍰ƄĀÜŚ†īŚźą„Āę„ĀĮ„ÄĀŚŅÖŤ¶Ā„Ā®Ť™ć„āĀ„āČ„āĆ„āčťôźŚļ¶„Āß„Āā„āčťôź„āä„ÄĀŤĎóšĹúś®©šĺĶŚģ≥„Ā®„ĀĮ„Ā™„āä„Āĺ„Āõ„āď„Äā
ŤĎóšĹúťö£śé•ś®©„Ā®„ĀģťĖĘšŅā
šłäŤ®ėŚźĆśßė„ÄĀÁ¨¨102śĚ°„Āę„āą„āäŤĎóšĹúś®©„Āę„Ā§„ĀĄ„Ā¶„ĀģŤ¶ŹŚģö„Āß„Āā„āčÁ¨¨30śĚ°„Āģ4„ĀĆśļĖÁĒ®„Āē„āĆ„Ā¶„ĀĄ„Āĺ„Āô„Āģ„Āß„ÄĀÁĒüśąźAI„āíťĖčÁôļ„Āô„āč„Āü„āĀ„ĀģŚ≠¶ÁŅíÁĒ®„Éá„Éľ„āŅ„āĽ„ÉÉ„Éą„ĀģŚÖ¨ťĖč„ÉĽŤ≤©Ś£≤„ā퍰ƄĀ£„Ā¶„āāŚéüŚČáŤĎóšĹúťö£śé•ś®©šĺĶŚģ≥„Ā®„Ā™„āä„Āĺ„Āõ„āď„Äā
„ÉĎ„ÉĖ„É™„ā∑„ÉÜ„ā£ś®©„Ā®„ĀģťĖĘšŅā
Ś≠¶ÁŅíÁĒ®„Éá„Éľ„āŅ„āĽ„ÉÉ„Éą„Āģšł≠„Āę„ĀĮ„ÄĀÁČĻŚģö„ĀģŤĎóŚźćšļļ„ĀģŚ£į„ĀĆ„ĀĚ„Āģ„Āĺ„ĀĺŚÜćÁĒü„Āß„Āć„āčŚĹĘŚľŹ„ĀßšŅĚŚ≠ė„Āē„āĆ„Ā¶„ĀĄ„Āĺ„Āô„Äā„Āó„Āč„Āó„ÄĀŚ≠¶ÁŅíÁĒ®„Éá„Éľ„āŅ„āĽ„ÉÉ„Éą„ĀĮťÄöŚłłÁĒüśąźAI„ĀģťĖčÁôļ„Āģ„Āü„āĀ„ĀęÁĒ®„ĀĄ„āČ„āĆ„āč„ĀęťĀé„Āé„Āö„ÄĀ„ÉĒ„É≥„āĮ„ɨ„Éá„ā£šļ蚼∂„ĀģśúÄŚą§„ĀĆŚą§Á§ļ„Āó„Āü„ÄĆśįŹŚźć„ÄĀŤāĖŚÉŹÁ≠Č„ĀĚ„āƍᙚĹď„āíÁč¨Áęč„Āó„Ā¶ťĎĎŤ≥ě„ĀģŚĮĺŤĪ°„Ā®„Ā™„āčŚēÜŚďĀÁ≠Č„Ā®„Āó„Ā¶šĹŅÁĒ®„Äć„Āô„ā茆īŚźą„Ā®„ĀĮŤ®Ä„Āą„Āĺ„Āõ„āď„Äā
„Āó„Āü„ĀĆ„Ā£„Ā¶„ÄĀŚĹ≤Śą©ÁĒ®Ť°ĆÁāļ„ĀĮ„ÉĎ„ÉĖ„É™„ā∑„ÉÜ„ā£ś®©šĺĶŚģ≥„Ā®„Ā™„āčšĹôŚúį„ĀĮ„ĀĽ„Ā®„āď„Ā©„Ā™„ĀĄ„Ā®Ť®Ä„Āą„Āĺ„Āô„Äā
„ÉĎ„āŅ„Éľ„É≥3ÔľöÁĒüśąźAI„ĀĚ„Āģ„āā„Āģ„ĀģŤ≤©Ś£≤„ÉĽŚÖ¨ťĖč

„Āď„Āď„Āß„ĀĮ„ÄĀŚ≠¶ÁŅíśłą„ĀŅ„ÉĘ„Éá„Éę„ĀĚ„Āģ„āā„Āģ„ĀģŤ≤©Ś£≤„ÉĽŚÖ¨ťĖč„ĀģśģĶťöé„Āę„Āä„ĀĄ„Ā¶ŤĶ∑„Āď„āä„ĀÜ„āčś®©Śą©šĺĶŚģ≥„Āę„Ā§„ĀĄ„Ā¶Ťß£Ť™¨„Āó„Āĺ„Āô„Äā
ŤĎóšĹúś®©„Ā®„ĀģťĖĘšŅā
ÁĒüśąźAI„ĀĚ„Āģ„āā„Āģ„Āę„ĀĮŚ≠¶ÁŅíÁĒ®„Éá„Éľ„āŅ„āĽ„ÉÉ„Éą„Ā®„ĀĮÁēį„Ā™„āä„ÄĀŚ≠¶ÁŅíśłą„ĀŅ„ÉĘ„Éá„Éę„Āģšł≠„ĀęŚÖÉ„Éá„Éľ„āŅÔľąŤĎóšĹúÁȩԾȄĀģŚČĶšĹúśÄß„āíśúČ„Āô„āčťÉ®ŚąÜ„ĀĆśģč„Ā£„Ā¶„ĀĄ„āč„Āď„Ā®„ĀĮŤ¶≥ŚŅĶ„ĀóŚĺó„Āĺ„Āõ„āď„Äā„ĀĚ„Āģ„Āü„āĀ„ÄĀÁĒüśąźAI„ĀĚ„āƍᙚĹď„ÄĀ„Āô„Ā™„āŹ„Ā°Ś≠¶ÁŅíśłą„ĀŅ„ÉĘ„Éá„Éę„ĀĮ„ÄĀŚÖÉ„Éá„Éľ„āŅ„ĀģšļĆś¨°ÁöĄŤĎóšĹúÁČ©„Ā®„ĀĮ„ĀĄ„Āą„Āö„Āď„āĆ„āČ„ĀģŚÖ¨ťĖč„ÉĽŤ≤©Ś£≤„ĀĮŤĎóšĹúś®©šĺĶŚģ≥„āíśßčśąź„Āó„Ā™„ĀĄ„Ā®Ť®Ä„Āą„Āĺ„Āô„Äā
ŤĎóšĹúťö£śé•ś®©„Ā®„ĀģťĖĘšŅā
šłäŤ®ėŚźĆśßė„ÄĀŚ≠¶ÁŅíśłą„ĀŅ„ÉĘ„Éá„Éę„Āģšł≠„ĀęŚÖÉ„Éá„Éľ„āŅ„ĀģŚČĶšĹúśÄß„āíśúČ„Āô„āčťÉ®ŚąÜ„ĀĆśģč„Ā£„Ā¶„ĀĄ„āč„Āď„Ā®„ĀĮŤ¶≥ŚŅĶ„ĀóŚĺó„Ā™„ĀĄ„Āü„āĀ„ÄĀÁĒüśąźAI„ĀĚ„Āģ„āā„Āģ„ĀģŤ≤©Ś£≤„ÉĽŚÖ¨ťĖč„ā퍰ƄĀ£„Ā¶„āāŤĎóšĹúťö£śé•ś®©„āíšĺĶŚģ≥„Āó„Ā™„ĀĄ„Ā®Ť®Ä„Āą„Āĺ„Āô„Äā
„ÉĎ„ÉĖ„É™„ā∑„ÉÜ„ā£ś®©„Ā®„ĀģťĖĘšŅā
ÁČĻŚģö„ĀģŤĎóŚźćšļļ„ĀģŚ£į„āíŤá™ÁĒĪ„Āč„Ā§ťęėÁ≤ĺŚļ¶„ĀęÁĒüśąź„Āß„Āć„āčAI„Āß„Āā„Ā£„Ā¶„āā„ÄĀ„ÉĒ„É≥„āĮ„ɨ„Éá„ā£„Éľšļ蚼∂„ĀģśúÄŚą§„ĀĆŚą§Á§ļ„Āó„ĀüšĺĶŚģ≥śÖčśßė3ť°ěŚěč„Āꍩ≤ŚĹď„Āó„Ā™„ĀĄ„Āď„Ā®„ĀĮśėé„āČ„Āč„Āß„Āô„Äā„āā„Ā£„Ā®„āā„Āď„Āģ„āą„ĀÜ„Ā™AI„ĀĮ„ÄĀÁČĻŚģö„ĀģŤĎóŚźćšļļ„ĀģŚ£į„āíŤá™ÁĒĪ„Āč„Ā§ťęėÁ≤ĺŚļ¶„ĀęÁĒüśąź„Āß„Āć„āčAI„Āß„Āā„āč„Āď„Ā®„āí„Éź„É™„É•„Éľ„Ā®„Āó„Ā¶ť°ßŚģĘ„ā팟łŚľē„Āô„āč„Āģ„ĀĆťÄöŚłł„Āß„Āā„āä„ÄĀ„Āĺ„Āüť°ßŚģĘ„āāŚĹ≤AI„ĀĆÁČĻŚģö„ĀģŤĎóŚźćšļļ„ĀģŚ£į„āíŤá™ÁĒĪ„Āč„Ā§ťęėÁ≤ĺŚļ¶„ĀęÁĒüśąź„Āß„Āć„āč„Āď„Ā®„āíÁźÜÁĒĪ„ĀęŚĹ≤AI„āíŤ≥ľŚÖ•„Āô„āč„Āģ„ĀĆťÄöŚłł„Āß„Āô„Äā„ĀĚ„Āģ„Āü„āĀ„ÄĀ„Āď„Āģ„āą„ĀÜ„Ā™AI„ĀģŤ≤©Ś£≤„ĀĮ„ÄĀšĺĶŚģ≥śÖčśßė3ť°ěŚěč„Āģť°ěšľľŤ°ĆÁāļ„Ā®„Āó„Ā¶„ÉĎ„ÉĖ„É™„ā∑„ÉÜ„ā£ś®©šĺĶŚģ≥„Ā®„Ā™„ā茏ĮŤÉĹśÄß„ĀĆťęė„ĀĄ„Ā®Ť®Ä„Āą„Āĺ„Āô„Äā
„Āĺ„Ā®„āĀÔľöÁĒüśąźAI„Ā®ŤĎóšĹúś®©„ĀģťĖĘšŅā„Āę„Ā§„ĀĄ„Ā¶„ĀĮŚįāťĖÄŚģ∂„ĀęÁõłŤęá„āí
„Āď„Āď„Āĺ„Āß„ÄĀšļļ„ĀģŚ£į„ĀģśúČ„Āô„āčś≥ēÁöĄś®©Śą©„ÄĀ„ĀĚ„Āó„Ā¶„ĀĚ„āĆ„āČ„ā팹©ÁĒ®„Āô„ā茆īŚźą„ĀęŚēŹť°Ć„Ā®„Ā™„ā荰ĆÁāļ„Āę„Ā§„ĀĄ„Ā¶ŚÖ∑šĹďÁöĄšļčšĺč„ā퍳Ź„Āĺ„Āą„Ā¶Ťß£Ť™¨„Āó„Ā¶„Āć„Āĺ„Āó„Āü„Äā
šļļ„ĀģŚ£į„Āģś≥ēÁöĄś®©Śą©„Āę„Ā§„ĀĄ„Ā¶„ĀĮ„ÄĀ„ÄĆŚÜÖŚģĻ„Äć„Ā®„ÄĆťü≥„Äć„Āꌹ܄ĀĎ„Ā¶ŤÄÉ„Āą„āčŚŅÖŤ¶Ā„ĀĆ„Āā„āč„Āď„Ā®„ÄĀŤĎóšĹúś®©„ÄĀŤĎóšĹúťö£śé•ś®©„ÄĀ„ÉĎ„ÉĖ„É™„ā∑„ÉÜ„ā£ś®©„ā퍶≥ŚŅĶ„ĀóŚĺó„āč„Āď„Ā®„ĀĆťá捶Ā„Āß„Āô„Äā„Āď„Āď„Āß„ĀĮŚČćÁ∑®„Ā®„Āó„Ā¶ťĖčÁôļ„ÉĽŚ≠¶ÁŅíśģĶťöé„ĀęÁĶě„Ā£„Ā¶Ťß£Ť™¨„āí„Āó„Ā¶„Āć„Āĺ„Āó„Āü„ĀĆ„ÄĀŚĺĆÁ∑®„Āß„ĀĮÁĒüśąź„ÉĽŚą©ÁĒ®śģĶťöé„Āę„Ā§„ĀĄ„Ā¶Ťß£Ť™¨„Āó„Ā¶„ĀĄ„Āć„Āĺ„Āô„Äā
ťĖĘťÄ£Ť®ėšļčÔľöAI„Āß„ÄĆŚ£į„Äć„āíÁĒüśąź„Āô„āč„Ā®ŤĎóšĹúś®©šĺĶŚģ≥„Āę„Ā™„āčÔľüÔľą#2 ÁĒüśąź„ÉĽŚą©ÁĒ®śģĶťöéÁ∑®ÔľČ
ŚĹďšļčŚčôśČÄ„Āę„āą„āčŚĮĺÁ≠Ė„Āģ„ĀĒś°ąŚÜÖ
„ÉĘ„Éé„É™„āĻś≥ēŚĺčšļčŚčôśČÄ„ĀĮ„ÄĀIT„ÄĀÁČĻ„Āę„ā§„É≥„āŅ„Éľ„Éć„ÉÉ„Éą„Ā®ś≥ēŚĺč„Āģšł°ťĚĘ„ĀęŤĪäŚĮĆ„Ā™ÁĶĆť®ď„āíśúČ„Āô„āčś≥ēŚĺčšļčŚčôśČÄ„Āß„Āô„ÄāŤŅĎŚĻī„ÄĀÁĒüśąźAI„āĄŤĎóšĹúś®©„āí„āĀ„Āź„āčÁü•ÁöĄŤ≤°ÁĒ£ś®©„ĀĮś≥®Áõģ„āíťõÜ„āĀ„Ā¶„Āä„āä„ÄĀ„É™„Éľ„ā¨„Éę„ÉĀ„āß„ÉÉ„āĮ„ĀģŚŅÖŤ¶ĀśÄß„ĀĮ„Āĺ„Āô„Āĺ„ĀôŚĘóŚä†„Āó„Ā¶„ĀĄ„Āĺ„Āô„ÄāŚĹďšļčŚčôśČÄ„Āß„ĀĮÁü•ÁöĄŤ≤°ÁĒ£„ĀęťĖĘ„Āô„āč„āĹ„É™„É•„Éľ„ā∑„Éß„É≥śŹźšĺõ„ā퍰ƄĀ£„Ā¶„Āä„āä„Āĺ„Āô„ÄāšłčŤ®ėŤ®ėšļč„Āę„Ā¶Ť©≥Áīį„ā퍮ėŤľČ„Āó„Ā¶„Āä„āä„Āĺ„Āô„Äā
„ÉĘ„Éé„É™„āĻś≥ēŚĺčšļčŚčôśČÄ„ĀģŚŹĖśČĪŚąÜťáéÔľöŚźĄÁ®ģšľĀś•≠„ĀģIT„ÉĽÁü•Ť≤°ś≥ēŚčô



„āę„ÉÜ„āī„É™„Éľ: IT„ÉĽ„Éô„É≥„ÉĀ„É£„Éľ„ĀģšľĀś•≠ś≥ēŚčô
„āŅ„āį: AIťĖĘťÄ£„ÉĎ„ÉĖ„É™„ā∑„ÉÜ„ā£ś®©Áü•ÁöĄŤ≤°ÁĒ£ś®©ŤĎóšĹúś®©ŤĎóšĹúťö£śé•ś®©
ťĖĘťÄ£Ť®ėšļč

ChatGPT„āíś•≠ŚčôŚą©ÁĒ®„Āô„āč„É™„āĻ„āĮ„Ā®„ĀĮÔľüś≥ēÁöĄ„Ā™ŚēŹť°Ć„Āę„Ā§„ĀĄ„Ā¶„āāŤß£Ť™¨
IT„ÉĽ„Éô„É≥„ÉĀ„É£„Éľ„ĀģšľĀś•≠ś≥ēŚčô

Twitter„ĀßšĽĖšļļ„Āģ„ÉĄ„ā§„Éľ„Éą„āí„āĻ„āĮ„É™„Éľ„É≥„ā∑„Éß„ÉÉ„ÉąŚľēÁĒ®„Āô„āč„Āģ„ĀĮŤĎó.
ťĘ®Ť©ēŤĘęŚģ≥ŚĮĺÁ≠Ė


ChatGPT„ĀģŚą©ÁĒ®Ť¶ŹÁīĄ„āíŤß£Ť™¨„ÄĀŚēÜś•≠Śą©ÁĒ®šłä„Āģś≥®śĄŹÁāĻ„Ā®„ĀĮÔľü
IT„ÉĽ„Éô„É≥„ÉĀ„É£„Éľ„ĀģšľĀś•≠ś≥ēŚčô

ŚēÜś®ô„Āģť°ěšľľ„ĀĮ„Ā©„Āď„Āĺ„Āߍ®Ī„Āē„āĆ„āčÔľüť°ěšľľśÄß„ĀģŚüļśļĖ„Ā®ŚēÜś®ôś®©šĺĶŚģ≥„Ā®„Ā™„ā茆īŚźą.
IT„ÉĽ„Éô„É≥„ÉĀ„É£„Éľ„ĀģšľĀś•≠ś≥ēŚčô

Amazon„Āę„Āä„ĀĎ„āčŤôöŚĀĹ„ĀģŚēÜś®ôś®©šĺĶŚģ≥ÁĒ≥Áęč„Ā¶„Āł„Āģś≥ēŚčôśą¶Áē•„Ā®„āĘ„āę„ā¶„É≥.
IT„ÉĽ„Éô„É≥„ÉĀ„É£„Éľ„ĀģšľĀś•≠ś≥ēŚčô


























